Lus10002955 [FLAX]

| External link |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Symbol | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Arabidopsis homologues
|
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Paralogs
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Poplar homologues |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
| PFAM info |
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Representative CDS sequence |
>Lus10002955 pacid=23142127 polypeptide=Lus10002955 locus=Lus10002955.g ID=Lus10002955.BGIv1.0 annot-version=v1.0
ATGGAGGCTGATACGTTTGAGGTCCAACCACCACCGCCATCCGGTTTCTTAACTGGCATAACCTTCGGTATCGCAACCAAAGACGAAAAGGAAAAGTTTG
CAGCTTTAGAGATTACAACAAATAGTGAAGTCACTGACACAAAGTTAGGATTCCCAAACGCTAGTTCTCAATGCTCCACTTGTGGTGCTAAAGATTTGAA
ACATTGTGAAGGTCACTTTGGCGTCATCAAGTTTCCTATGACAATTCTCAATCCCCATTTCATGTCTGAAGTCGCCCGCATTCTGAACAATATATGCCCG
AGTTGTAAATCTGTGCGGAATCTTTTGCCTAAGAAAAAGGATCAGAGGCCTAAAGAAAACCTGTCTAATGGCTGCAAATACTGTGCGAAGCAAGGAAAGA
CATTAGGGTGGTATCCAAGAATGAAGTTCACGGTTTTTACTGGACAATACTTTCGGAAAACGACAATCGTTGCCGGGATTGGCAAACAACTACCGACACG
GAGAGGAGTCAGAAAACTGGCTCCTGACTTTTGGGACATTATTCCAAAGGATGAAGAATTAGATGAAAACGCTATCACGCCAACTAAAAGGCTTTTGACG
CATGGGCAGATTTGCCATTTGTTAAATGGTGTTGATGATAGTTTCATAGAGAGGTTCTGTTTGAACAAAGAGTGTCTATTCCTCAATAGCTTCTCAGTAA
CACCAAATTCTCAGCGTGTTACGGAAATGATGAGTTCATATTCTAGTTCACGAAGATTGGCCTTTGATGGTCGCACTCGTGCATACAAGAAGATGGTTGA
TTTCAGAGGGAAAACACATGAATTATGTTACCATGTCCTCGAGGCTCTCGCAGCTTCCAAGATAAACACTGAACGGATAGCCCCAAACGATCCAATTGCC
CTTCTTCAAAAGAGGAATGATGATGTGTCTACAAACTCTTCCGGATTGAGATGGGTCAAGGATGTTGTTCTGGCTAAGAGGAATGATCATTGTTTCCGCA
TGGTGGTCGTCGGAGACCCTAGTCTACAGCTCAGTGAAATTGGGATCCCCCGCGCAGTTGCAGAAAGTATGAAAATTTCGGAACATCTGACAACATACAA
TGCAGACAAGCTCGTAAGTTGCGTTGAAGAGCTCCTTCTCGAGAAGGGTATGATTCATGTACGCAGAGGAAGCGACCTTGTTCGTATTTCTCGTACGAAG
GACCTCAAAATCGGGGACATGATATATAGGCGACTGAAGGATGGAGATACCGTCCTAGTCAACAGGCCTCCGTCCATCCATAAACACTCCCTAATTGCAC
TCTCTGTGAAGATCCTTCCGGTTACTTCATCTCTAGCGATAAATCCGCTCTGCTGCTCTCCGTTTCGGGGCGATTTCGACGGCGACTGCATGCATGGCTA
TATTCCTCAATGTGTTAACAGTAGAACCGAACTTAAGGAGCTCGTTTCATTGGATAAGCAGCTGACCGATGTACAGAGTGGCCAGAATCTTCTTGCTCTC
AGCCAAGATAGTTTGACTGCTGCACATTTAGTATTAGAGAATGGGATCTTTCTCAACAAATATCAGATGCAACAGTTGCAGATGTTCTGCCCTAAGGAGT
TGCTAGCCCCGGCGATGATGTCATCTTTGACCGGTGGGGTATGGACTGGAAAACAGTTGTTTAGCATGCTCTTGCCCCAAGGGTTTGACTTTGATTTTCC
ATCAGATAATGTCTCGATACGTGATGGTGAGCTAATGCATTGTGATGGATCTTTCTGGTTGCGTCAGACAGAAGGAAACCTATTTCAAAGCCTTTCCCAG
TGTTTCAGCGGTGATGTTCTTGATGTGCTGTATGCTACTCAGAGAGTTCTGGGCGAGTGGCTATCGACGAGAGGGTTTAGTGTTTCTCTCTCCGACTTCT
ACCTCTGTCCCGACTCCAACTCACACAAAAGCATGCTGGATGAGATCTCGTGCGGGTTGCAAGAAGCAGAAGAAGCTGCTGACGCAAGGCAGCTAATGGT
GGATTCTCGTCAGGATTTCCTTGCTACAGGCAGTGAAGAAGTTAGTGTCGTGTTCGAAGCTGATAGCTTTTTTCTTGAAAGGCAGAGATCTGCTGCACTG
AGTCAAGGATCGGTTGATGCTTTCAAGCAAGTGTTCCGAGATATTCAAACCCTGGCCTTCAGATATGCGTCTAAGGAAAATTCATTGCTGACCATGTTTA
AGGCCGGAAGCAAAGGAAATCTGCTGAAACTGGTCCAGCATAGCATGTCTCTCGGTCTGCAACATTCCCTTGTCCCATTGCCATTCAAGATGCCTCGCCA
GCTCTCGTGCGAATCGTGGGATAAACAGAAAGCCGATGATGCTACTGACTGTGCCAAGCGGTTTGTTCCATCTGCAATTGTCAAAAGCTGCTACCTAACC
GGACTGAATCCCTTGGAAGCTTTCGCTCACTCAGTCACAAACAGGGATAGCTCGTTCAGTGACAACGCTGAGCTTCCGGGAACTTTGTCCCGGAGACTTA
TGTTCTTCATGCGTGATATCTGCACGGCATATGATGGGACAGTAAGGAATGCATATGGGAATCAGCTTGTACAGTTTTCATACAACACTGATGAGAACAC
AAGCGATCGCGGTCCAGATGGTGGCCACCCTATTGGTGCACTGGCTGCTTCTTCGATCTCGGAAGCTGCATATAGTGCTCTGGACCAGCCGATTAGTCTT
CTGGAAAAATCGCCCCTGCTAAATCTCAAGAATGTACTGGAATGCGGTGCCAAAAAGAGTAAATCTCCACGAACTGCATCACTGTTTCTCTCGAAGAAGC
TCGGAAGAAAAAGATACGGTTTTGAGTATGGCGCGCTGGATGTTCGGACCCATTTGCAGAAAGTTCTGCTTTCTGATACAGTTTCTATTGCCAGGATAAT
ACATCCTCGGAAAGCTGATTGCGTGCCTCAACTGAGCCCTTGGGTTATACATTTCCATTTATTGAAGGAAATTGTGAAGAAGAAAGGCCTGCAGCCTGCA
GTAATAGTTGACGCTCTGGACAAGCAGTGCTCTGTGAATCCCAAATTTCCGAAAATTGAGTTCAAATACATTCGGCGATGTCGTGATGGTGACAATTGGA
ACGAACGCCAGGAAACATTTTGCATAACGGCCACAGTGATTGAAAGTCCCAAAAGATCTTCCACGGAGTTGGAAACTATTCGAGATTTCTTGATTCCCTT
TCTTCTTGGAACACCTATTAGAGGATTCTCGGATATCGACAAGGTGGCTATTCTTTGGAGTGATAAGCCAAAGGTAACGTTTTCCGGCAAACGAAAATCT
GGTGAGCTCTACTTGCGAGTAACGATGTCTGGAATGTCAGACACATCGAGACTCTGGGGCCAGCTTCTGGACAACTGTCTCCCTATAATGGATATGATTG
ACTGGACGCGAAGCCATCCGGATAACATCAGGGATTTATCTTCTGCTTATGGCATTGATTCTGCTTGGAATGTTTTTGTCAGTAGCCTGGAGTCTGCAAT
TGGTGATGTCGGCAAAACTGTTCTTCCTCAGTATTTGCTTCTGGCAGCTGACACTATGTCCATAACTGGAGAATTTGTTGGCTTGAATGGAAAAGGTTTG
AAGCTTCAGAGAGAGCATGCGTCTGTGACATCCCCATTTGTGCAGGGTGCCTTTAGTAATCCCGGGGATAACTTTATCCGTGCTGCAAAGGCTGGTGTCA
CTGATCAACTCATGGGTTCGGTGGATAAACTGGCATGGGGGAGGATGGCTGCCATTGGAACTGGCACTTTTGACATCATTATGACTCTGAAGGATCATGT
ACTGCCCAAGCATAAAAATGGGTACGAGTTTCTGGCTGAACACTCAACTTCTCAAACTCTCAGCACAACATTTGAGATACCAGACTCGTGGAGCAAAAGA
TTCGAGAAATGCCGAACAGAAATGCCATTCAAACTTGATGGCTATGCTAACCTATCCAAAAAGGCAAGTGTTGCAGCATCGCTTGGAACTCATCTATCTT
ACAACGACATTCTGAAGCTCGACCAAGAACTGCGCAGAATCTTGAATACCTCTCCTGTGGATGAGGAACTCAGTGATCGTGGCAAAGAGAAATTGATGAA
AGCATTATACTTCCACCCTCGTAAAGACGAGAAGATTGGAAACGGAGCTCAACACTTCAAGGTTATAAACCACCCGATACATGAAGGCTCGCGCTGCTTC
GCAGTGGTTAGAGCCAATGGTACAATGGAGGACTTCTCGTATCATAAGTGCATCATGGCTGCACTTGACATAATCGCCCCCGGTAAGACCTCATTGTACC
AGAAGAGGTATCTGCAGAGGCTCAATGGTAAAGATCAGTAA
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
AA sequence
|
>Lus10002955 pacid=23142127 polypeptide=Lus10002955 locus=Lus10002955.g ID=Lus10002955.BGIv1.0 annot-version=v1.0
MEADTFEVQPPPPSGFLTGITFGIATKDEKEKFAALEITTNSEVTDTKLGFPNASSQCSTCGAKDLKHCEGHFGVIKFPMTILNPHFMSEVARILNNICP
SCKSVRNLLPKKKDQRPKENLSNGCKYCAKQGKTLGWYPRMKFTVFTGQYFRKTTIVAGIGKQLPTRRGVRKLAPDFWDIIPKDEELDENAITPTKRLLT
HGQICHLLNGVDDSFIERFCLNKECLFLNSFSVTPNSQRVTEMMSSYSSSRRLAFDGRTRAYKKMVDFRGKTHELCYHVLEALAASKINTERIAPNDPIA
LLQKRNDDVSTNSSGLRWVKDVVLAKRNDHCFRMVVVGDPSLQLSEIGIPRAVAESMKISEHLTTYNADKLVSCVEELLLEKGMIHVRRGSDLVRISRTK
DLKIGDMIYRRLKDGDTVLVNRPPSIHKHSLIALSVKILPVTSSLAINPLCCSPFRGDFDGDCMHGYIPQCVNSRTELKELVSLDKQLTDVQSGQNLLAL
SQDSLTAAHLVLENGIFLNKYQMQQLQMFCPKELLAPAMMSSLTGGVWTGKQLFSMLLPQGFDFDFPSDNVSIRDGELMHCDGSFWLRQTEGNLFQSLSQ
CFSGDVLDVLYATQRVLGEWLSTRGFSVSLSDFYLCPDSNSHKSMLDEISCGLQEAEEAADARQLMVDSRQDFLATGSEEVSVVFEADSFFLERQRSAAL
SQGSVDAFKQVFRDIQTLAFRYASKENSLLTMFKAGSKGNLLKLVQHSMSLGLQHSLVPLPFKMPRQLSCESWDKQKADDATDCAKRFVPSAIVKSCYLT
GLNPLEAFAHSVTNRDSSFSDNAELPGTLSRRLMFFMRDICTAYDGTVRNAYGNQLVQFSYNTDENTSDRGPDGGHPIGALAASSISEAAYSALDQPISL
LEKSPLLNLKNVLECGAKKSKSPRTASLFLSKKLGRKRYGFEYGALDVRTHLQKVLLSDTVSIARIIHPRKADCVPQLSPWVIHFHLLKEIVKKKGLQPA
VIVDALDKQCSVNPKFPKIEFKYIRRCRDGDNWNERQETFCITATVIESPKRSSTELETIRDFLIPFLLGTPIRGFSDIDKVAILWSDKPKVTFSGKRKS
GELYLRVTMSGMSDTSRLWGQLLDNCLPIMDMIDWTRSHPDNIRDLSSAYGIDSAWNVFVSSLESAIGDVGKTVLPQYLLLAADTMSITGEFVGLNGKGL
KLQREHASVTSPFVQGAFSNPGDNFIRAAKAGVTDQLMGSVDKLAWGRMAAIGTGTFDIIMTLKDHVLPKHKNGYEFLAEHSTSQTLSTTFEIPDSWSKR
FEKCRTEMPFKLDGYANLSKKASVAASLGTHLSYNDILKLDQELRRILNTSPVDEELSDRGKEKLMKALYFHPRKDEKIGNGAQHFKVINHPIHEGSRCF
AVVRANGTMEDFSYHKCIMAALDIIAPGKTSLYQKRYLQRLNGKDQ
|
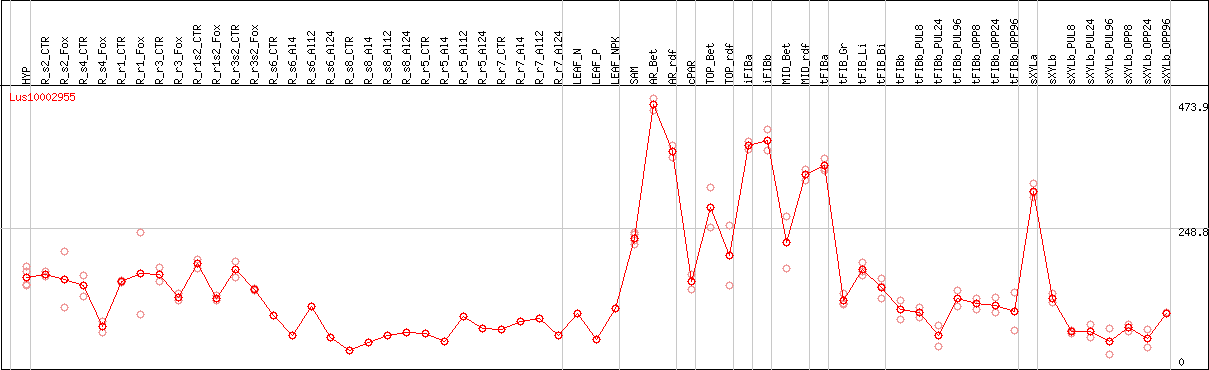
DESeq2's median of ratios [FLAX]
Coexpressed genes
Lus10002955 coexpression network
*The number of genes in the network is adjusted within 50 genes.*Gene name represents symbol(s) of closest Arabidopsis gene if symbol(s) for the gene itself doesn't exist.
*Circle diameter represents the number of connection with other genes within this network.
*Color for gene name represents subnetwork based on the result of network clustering.