Lus10004388 [FLAX]

| External link |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Symbol | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Arabidopsis homologues
|
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Paralogs
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Poplar homologues |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
| PFAM info |
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Representative CDS sequence |
>Lus10004388 pacid=23151929 polypeptide=Lus10004388 locus=Lus10004388.g ID=Lus10004388.BGIv1.0 annot-version=v1.0
ATGGCTTTCCACTTGTGCTTCAGTTGCTTCAATGGTGTTGATGCTGCAGCAAGCAACGAGACGGATCGCCAAGCCTTGCTTCATTTCAAGTCGATGATTT
CTAGCGATCCACTCGGAGCATTGAGCTCATGGAACGATTCCTCCTCCTTTACCAACTTCTGCCAGTGGCAGGGTGTTACTTGTAGCACAAGGCACCAAAG
AATCACAGTCCTGGACTTGAGATCCCTGCAACTCTCAGGTTCCGTCTCTCCGCATATTGGCAACCTCAGCTTCCTAAAGGAACTCTACCTAGTCAACAAC
AGCCTGACGCAACAGATTCCTCCTGAAATCGGCCGCCTCCACAGACTGGAGAGGTTGCTCATCCTGAACAACTCCTTCAGTGGTGAAATCCCACCAACAT
TGTCAAACTGCTCCAATCTTGTCATGTTCAACGCCGCCAACAACCTTTTGGTAGGTGAAATACCACGGGAGATCGGTTCCTTGAAGAATCTCCGGAACTT
TGTTGTCAGCTTCAACAGATTGACAGGATCCATCCCTGCTTCTCTAGGGAATCTTTCATCTCTCATGGTCCTTTCTGCAAGCAACAACCAACTATCCGGT
GATATTCCGAGCTCACTAGGTCAACTGAAGAACCTCAGCATTTTGTACCTTCCCATGAACAGTTTATCCGGTGTGATCCCTTCATCAATCTTCAATCTTT
CTTCTCTTACATATCTCTACTTCGGATTCAACCAGCTCCGCGGAACCCTCCCTTCCGATTTGGGAATATCACTCCCGAATATCCAGAGCTTCGATGTGGC
TCTCAACTACCTAACCGGTAACATCCCAGCTTCGTTCTCGAATTCCTCGAATTTGGAGCAACTTCAGCTCCAAGGCAACGGCTTCACCGGAAGGGTACCG
GATCTGGGGAGCGCTCGTAACCTTCTACGATTGATCATCAACAACAACTCCCTCGGTACTGGTGGAGGCAACAACGATGATCTCGGATTCATTTCTTCTT
TGACCAATGCCACCAATTTACAAGCGTTGATCATTGACCAGAACAACTTCGGAGGTAGCTTGCCTTCACACGCAAGCAACCTATCCGCCTTGCAGATTCT
CTACATAAGTGATAACAAACTATCAGGTGAATTGCCAGCTGGCATCCACAATCTCAAGAACTTGCAGAGACTTGTGGCATTTAACAACAGATTCTCAGGT
AATATCCCATCCACCATTGCGAATCTAAGAAATCTAGAGGAGTTTGATTTGAGTAACAATAGTTTCACCGGGAATCTGCCATCATCAATTGGAAACCTGA
CAAGATTACTAGAGCTGAAACTGGCAAGGAACAATTTTCAAGGAAGAATTCCTTCAAGCATTTCGGATTGCGAAAAGCTGATAACTTTGGATCTTTCTCA
TAACAACTTCAGTGGTGCAATTCCTGAAGGAGTTATGAATCTTGTTTCCTTGTCAGTTTTCCTGAATTTGTCTAACAACCTTTTGAGTGGTTCATTTCCG
GCCGAAGTTGGAAACCTGAAGAACTTGGGCGCGTTGGATCTATCTCGTAATATGTTGTCAGGAAGCATTCCGAGAAGTCTAGGTAGTTGTGTCAGGTTGG
AATCGGTGAACTTGCAGGGGAATCTTTTCCAGGGAGATATTCCTTCTTCTTTGAGTTTGTTGAGAGGTATTCAAGAGCTGGACGTCTCGGGGAACAACTT
ATCTGGTCAAATTCCGAAACTTTTCGAAGGCATGAACTTGTTGCGAGTTTTGAATTTGTCGCACAATAATTTCGAGGGTGAGGTGCCGAAAGGAGGAATC
TTTACGAATGGGAGCATCGTTTCGTTCGTTGGGAATGGAAAACTCTGTGGTGGCATAGCTGGTCTAAATCTTCCGCCTTGCAAGTTTAGTGACCGAAAGA
AGACACTAAGCCGTAAGTGGAAGATCGTTATATCCACAGTTTCAAGTCTAATTTTCTTGGCTTTCTTGATAGCTTCTTGCTTGCTCGTCTTCTGGATTAA
AAAGAGAGGACGAAAACAACATTCAGTTTCAGCCGGTGGTGATTCGATGTCCTACCAAAGGCTCTACAAAGCAACAGATGGTTTCTCCTCGTCGAATTTG
GTTGGTGTGGGCGGTTTTGGTTCTGTGTACAAGGGAGTCCTTGATCACGAGAATGAAACTACCACTATTGCTGTTAAGGTATTCAACCTTCAGCGTCAGG
GAGCTTCCAAGAGTTTTATAGCGGAATGTGAAGCGTTGAAGAATATTAGGCACAGAAACCTTGTGAGGATAGTGACGGTGTGTTCGAGCGTTGACTATCA
AGGGAACGATTTCAAGGCTCTGATATATGAGTTCTTGGCTAAAGGAAGTTTAGAAGAGTGGTTGCATCCCGTACTCGAAAGTGTTGATGGTCGGCATCCT
ACTCCTAAGATGTTGAGCTTCCTCCAAAGGTTGAATGTTGCAATTGATATAGCTTCTGCAATGGATTATCTTCACCATCAATGCGGGACACCCATTGTTC
ACTGTGATCTCAAGCCTAGCAATGTTCTCCTCGACGAGGATAAGGTGGCTCATGTTAGTGATTTCGGATTAGCAAGAATTCTTCTATCGCCAGTTGCTAC
CATGCCATCTTCAGCTGGCATGGCATCATCCATTGGCGTTAAAGGAACTGTTGGCTATGCTCCTCCAGAATATGGAATGGGGAATGAAGTTTCGATACAA
GGAGATGTGTACAGTTATGGAATCCTCCTGCTCGAGATGTTCACAGGAAAGAGGCCAACTGATGAATCTTTTCGAGAAGGTTCGAACCTTCATATCTTTG
TCAGAAGCGCTTTATCCGAAAATAAGACAACACAAGTTGTGGATCCAGTTCTACACACCGACTTACTTCTTAGTCAGTCAACCCCTAGCAGTACTAGCAA
CAAAAACAAAGGACAAATTCCCGATGAGGCTCTAATTTCCATCCTCAAAATTGGTGTCATTTGTTCTTCGGATTTCTCACAGGACAGGATTAGCATGACT
GCTGTTTTCTCCGGTTCCATCTCACCGCACATTAGCAATCTCAGCTTCCTGACGTGGATCAATCTCTCAAACAATAGTTTCAGTGGAACAATTCCTGCTG
AAATCGGCCGCCTTCGTAGCTTGGAACTGCTGCTGCTTTCAAACAACTCTTTCACCGGTGAGATCCCCTCCAATATCTCAGCATGCTCTAATCTCACCAA
ATTCGTCGCACCGAGTAACAACCTGGTGGGAGGATTGCCGGTATTAGAAATGTCGTCATTGAGTAAACTCGAAGTTTTCGACGTGTCACTGAACAAACTA
TCCGGAAGCATCCCTCCGTCTTATGGCAACTTGTCATCTCTCAAGGTGTTTCGTAGCTGGAAACAACAACTTGAGCGGGATGTCATGGGTCTTACTTCCT
TGTCAATCCTCCTTAACTTGTCTCATAATCGTCTCATCGGAGCCCTTCCGGTGGAAATGGGGAGTCTGACGAACTTGGGCGTTTTGGATCTGTCACAGAA
CATGTTGTCGGACAGCATTCCAAGCAGTATTGGTAGCTGTGTCAGCCTGGAGGCGGTTTACTTGCAAAACAATCTACTGCAAGGTGATATTCCTTCTTCT
TTGGGTTCATTGAGAGGGATTCAACAATTAGACATCTCTGCCAATAACTTAACAGTAACCGGAAATAGCAAGCTTTGTGGAGGGATGGCGGACCTTAAAC
TTCCATCTTGTAACTCGAGACATGGAAACAAGACATTCACCCATAAGTTGAAGATTGTCGTATCAACAATCTCCGGTCTAATTTTTTTTGGCTTCCGTAG
GTTGTTGCTTACTTATCTTCTGGATAAGTGCATGCAGTTCCACCAAAGACTTGATGCCGCAATTGATATAGCTTCAGCAGTGGATTATCTTCACCGTCAA
AGCGGTACACCCACAGTTCACTGTGATCTCAAGCCTAGCAACGTTTTTCTTAACAAGGATATGGTGGCTCATGTCAGTGATTTCGGATTAGCAAGAATCC
TTCCGTCACTATTTCCTAATCCCTCTACAGCTGGTCATACATCATCAAGCTCCGTCGGCATAAAAGGAACTGTTGGCTATGCACCTCTAGAATATGGCAT
GAGAAACGGAATCTCGATACAAGGCGATGTCTACAGCTACGGAATTCTGTCACTTAAGATGTTCACAGGAAAGAGGCCAACAGGCGAATCTTTCAAAGAA
GGGAAGCGCTTTATCCGAATATTTGGCAGCAGAAGTTGTGGATCCAGATCTACGCAACGAGCTACTGCTTAG
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
AA sequence
|
>Lus10004388 pacid=23151929 polypeptide=Lus10004388 locus=Lus10004388.g ID=Lus10004388.BGIv1.0 annot-version=v1.0
MAFHLCFSCFNGVDAAASNETDRQALLHFKSMISSDPLGALSSWNDSSSFTNFCQWQGVTCSTRHQRITVLDLRSLQLSGSVSPHIGNLSFLKELYLVNN
SLTQQIPPEIGRLHRLERLLILNNSFSGEIPPTLSNCSNLVMFNAANNLLVGEIPREIGSLKNLRNFVVSFNRLTGSIPASLGNLSSLMVLSASNNQLSG
DIPSSLGQLKNLSILYLPMNSLSGVIPSSIFNLSSLTYLYFGFNQLRGTLPSDLGISLPNIQSFDVALNYLTGNIPASFSNSSNLEQLQLQGNGFTGRVP
DLGSARNLLRLIINNNSLGTGGGNNDDLGFISSLTNATNLQALIIDQNNFGGSLPSHASNLSALQILYISDNKLSGELPAGIHNLKNLQRLVAFNNRFSG
NIPSTIANLRNLEEFDLSNNSFTGNLPSSIGNLTRLLELKLARNNFQGRIPSSISDCEKLITLDLSHNNFSGAIPEGVMNLVSLSVFLNLSNNLLSGSFP
AEVGNLKNLGALDLSRNMLSGSIPRSLGSCVRLESVNLQGNLFQGDIPSSLSLLRGIQELDVSGNNLSGQIPKLFEGMNLLRVLNLSHNNFEGEVPKGGI
FTNGSIVSFVGNGKLCGGIAGLNLPPCKFSDRKKTLSRKWKIVISTVSSLIFLAFLIASCLLVFWIKKRGRKQHSVSAGGDSMSYQRLYKATDGFSSSNL
VGVGGFGSVYKGVLDHENETTTIAVKVFNLQRQGASKSFIAECEALKNIRHRNLVRIVTVCSSVDYQGNDFKALIYEFLAKGSLEEWLHPVLESVDGRHP
TPKMLSFLQRLNVAIDIASAMDYLHHQCGTPIVHCDLKPSNVLLDEDKVAHVSDFGLARILLSPVATMPSSAGMASSIGVKGTVGYAPPEYGMGNEVSIQ
GDVYSYGILLLEMFTGKRPTDESFREGSNLHIFVRSALSENKTTQVVDPVLHTDLLLSQSTPSSTSNKNKGQIPDEALISILKIGVICSSDFSQDRISMT
AVFSGSISPHISNLSFLTWINLSNNSFSGTIPAEIGRLRSLELLLLSNNSFTGEIPSNISACSNLTKFVAPSNNLVGGLPVLEMSSLSKLEVFDVSLNKL
SGSIPPSYGNLSSLKVFRSWKQQLERDVMGLTSLSILLNLSHNRLIGALPVEMGSLTNLGVLDLSQNMLSDSIPSSIGSCVSLEAVYLQNNLLQGDIPSS
LGSLRGIQQLDISANNLTVTGNSKLCGGMADLKLPSCNSRHGNKTFTHKLKIVVSTISGLIFFGFRRLLLTYLLDKCMQFHQRLDAAIDIASAVDYLHRQ
SGTPTVHCDLKPSNVFLNKDMVAHVSDFGLARILPSLFPNPSTAGHTSSSSVGIKGTVGYAPLEYGMRNGISIQGDVYSYGILSLKMFTGKRPTGESFKE
GKRFIRIFGSRSCGSRSTQRATA
|
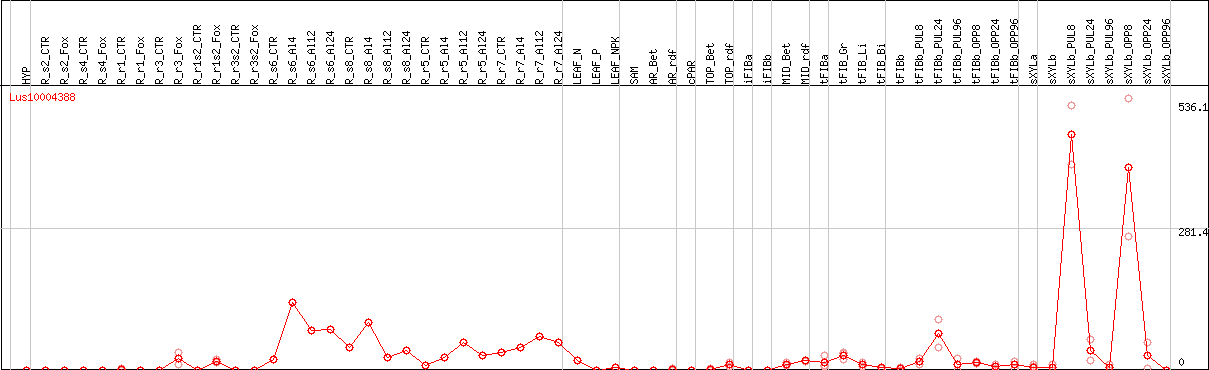
DESeq2's median of ratios [FLAX]
Coexpressed genes
Lus10004388 coexpression network
*The number of genes in the network is adjusted within 50 genes.*Gene name represents symbol(s) of closest Arabidopsis gene if symbol(s) for the gene itself doesn't exist.
*Circle diameter represents the number of connection with other genes within this network.
*Color for gene name represents subnetwork based on the result of network clustering.