Lus10005582 [FLAX]

| External link |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Symbol | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Arabidopsis homologues
|
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Paralogs
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Poplar homologues |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
| PFAM info |
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Representative CDS sequence |
>Lus10005582 pacid=23139674 polypeptide=Lus10005582 locus=Lus10005582.g ID=Lus10005582.BGIv1.0 annot-version=v1.0
ATGGCGGATCCGGTTTCTTCTACTTCTCCTTCATGTCCTTCTTTCTCCAACGGCCGATCTTTGCTAGGGTTTTCTTTGAGTTCTCCTGATCTGGTTATAT
GCGCTGGTTCACCTGAAATGGAGAGCAACATTTGTGGATGTTCCCCGGAAATTGTAGGTAGTAGGAAGAAGCAGTGTATGGATCTCTCGTTAGACAACGG
CATTGCTGGCTATGAATCTGGTGCCAGAGAAACCAGTAGATCTGTTAAATTCTCCCCTTTTTGTCAAACATTTTACAATAAGGAATTGTCTCCTGAGTCA
TCCATCGAGCTCCTTGCCCGTCCAGTGAAGGGAGAGCAAATTGTGGGAGATGTTCTTCCTGCGTCTGCGGGGATAACCATCAATGTGGGATGCACTGATG
ATCAGACTGTGACTAAGGATGGTTTGAGCTATATGAAGGATAGTTGTTTCCTTGGTGGTGATACTGTGAGGACTAATGCCATAATTGGTGATGGACTAGA
TGAGGATGAGAGCCTTTGTCTATACCAAACAGCTCGGATGGGTGACTTCTCGTACTGTTTTCGGTCATTGGAGCCAGGGGATTACGATGTTGCTCTTCAC
TTTGCAGAGATAGTGTTTACCAATGGGCCTCCAGGGTTAAGGGTGTTTGACGTTTTTCTGCAAGAAAAGAAGGTCGTTTCCAATTTAGACATCTTTGCTC
GAGTAGGAGCAAACAATCCTTTGGTTCTATCCGACCTCAAAGCTTCTGTTGGATTGGGTGAAAAATTATCGATTAGATTAGAAGGTGTAACGGGTACACC
GATTCTATGTGCAATTTCAGTTGCAAAGGATGATTCTGCTAGTACTGGAGAAGCTTCGTTTCCTGAGCATATAAAAAGGTCCCAAGCAGCAGAAATTGAG
TCACAGAAAAATGCTGACTGTGAGATGGAAGATGATTATCAGAAGCTGTTGACTGCTTATGAATGTCAGCAACGGGAACTAACGGAGATGAGAAAGATAG
TAGAGGAACTTAATAGGGAGAACCAGGTAAAAACTAAAGAGTGCCAAAATGCGTTGAAGACTTTGCAGGACCTCCAAAGCGAGTTGATGCGGAAGTCTAT
GCATGTAGGCTCATTAGCTTTTGCTGTTGAGGGGCAAGTCAAAGAGAAGAGTAGGTGGTTCTCAGCACTGAAAGACTTGACAGAAAAAATAGAGATGATG
AAAGGGGACCAAATCAAGCTATCTGAGGAAGCTAGGTCATATAAAGCTTGTTTCGGGGAAATGAGCGAGATTGCATCTACCATTCAGTCCACAATGAAAC
AGCAATCCGGTTTGCATGGAGATCTTATGAAGAAATTCATGGAAGGAGTCAGAGAACGGAAGGAACTATATAACAAGGTGTTAGAACTGAAAGGAAATAT
AAGGGTCTTTTGCAGGTGTAGGCCTTTGAATAGTGAAGAAATTGCAGCAGGAGCTGCAATGGCTATTGATTTTGAATCAGCTAAAGATGGAGAACTTACT
GTTTTCTCAAATGGGGTTCCAAGAAAGACCTTCAAGTTCGACTCCATTTTCAGCCCTCAAGCAAACCAAGCTGATGTCTTTGAAGATACAGCCGCATTTG
CAACCTCAGTGTTGGACGGTTACAACGTGTGCATATTTGCTTATGGGCAGACCGGAACTGGAAAAACGTTTACAATGGAAGGCACAAAAGAGGCTCGTGG
AGTGAATTATAAAACTCTGAATGAATTGTTTCACATGATAAAGGAGCGGGAGAAAATTTTCAAATATGAAGTATCAGTGAGTGTCTTAGAAGTTTACAAT
GAGCAAATACGGGATTTGCTCGTCTCAAACTCACAGCCAGCAACTGTGAAAAGGCTAGAAATAAGACCAGCAGGAGATGGACTGCATTGTGTTCAAGGTT
TGGTTGAAGCACGTGTAAACAATGTAAATGAAGCCTGGGAAGTTTTACAGACTGGTAGCAATGCCAGGGCTGTCGGTTCAACCAGTGCAAATGATCACAG
CAGCAGGTCTCATTGCATACACTGTGTGATGGTCAAGGGGGAGAATCTGTTAAATAAGGAATGCACGAGGAGCAAATTATGGTTGGTAGACCTAGCTGGA
AGCGAGCGAGTGGCGAAAACAGAAGTCCAAGGAGAGAGATTAAAGGAAACTCAGAATATCAATAGATCATTGTCGGCATTAGGGGACGTCATATTCTCTC
TTGCAACTAAGAGCCCTCATATTCCCTTCAGGAATTCGAAGCTGACCCATTTGCTTCAAGATTCTTTAGGAGGAGATTCAAAAGCACTTATGTTTGTACA
GATCAGCCCAAACGAGAGTGACCTAAGCGAAACACTATGCTCGTTGAACTTTGCAAGCAGGGTTCGGGGCATAGAGTTGGGCCCTGCAAAGAGACAATTT
GACATGCCTGAGCTTGTAAGATATAAACAACTGGCTGAGAAAACTAGACAAGAGTTGAAGCTCAAAGATGTTCAAATAAGAAAGATGGACGATACGGTCC
AAGGACTGGAGCTGAAGGTCAAAGAGAAGGACATAAAGAACAAACATTTGCAGGAAAAGATAAAGGAGCTGGAGTCCCAACTGCTAGTTGAAAGGAAGCT
GGCACGTCAGCATGTGGACACAAAGATTGCTGAGCAGCATTCGAAACAATCAGATGATCAAACTTGTCCCCCACCAAGACCGCCACTTGGAACTCGGTTA
TTAGGGAATAGTAGTAACAAGGCTTCTTCAAATGGATCTGCAAATGTTGCATTGAACAAGGAAACAATGGATGCTGAGAACTTCCTTCCCTCGACGGATG
TCATCTTCAAGATCCCCGACCCTATGGAGAAGGAAAACAATCCTGACATGGCTGAGAATCTGGGAATGCAAAAGAGAACAACTGGCAGGTTCTCAATTTG
TCCAGCTCCTAGAAGAAACTCACTCATTCCGTTCTCAAGTCCATCGCCATTACCATTATTACCAGTTTCTCTGAATCAAGATGCAGAGAAAGGAGTGTGT
GAAAGTCAGAAAGAAGGGAAAACCGGGACCAGGAAGCGAAATAGCGTGCTGAGACGAAGCGTGCATAAAAAGTTGCAGAGCAGATCGCCAATGCAGCAGC
AGATTGCAAGGAAAGGAGGGATAAATGTCGGGATGGAGAAGGTGAGATTATCGATAGGAAGTCGAGGGAGGATGGCGCAGAGAGTGGTGCTGCACGGAAG
TGCTGCAGCGAAGAGGGTAGTAAGTAAGGAGATCACAACACAGCAGAAGCAAGTGAGCCATAAGGAGAAGGAAAGAGGATGGAATAATGCAACAACAACG
GCAAGGTTGTGA
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
AA sequence
|
>Lus10005582 pacid=23139674 polypeptide=Lus10005582 locus=Lus10005582.g ID=Lus10005582.BGIv1.0 annot-version=v1.0
MADPVSSTSPSCPSFSNGRSLLGFSLSSPDLVICAGSPEMESNICGCSPEIVGSRKKQCMDLSLDNGIAGYESGARETSRSVKFSPFCQTFYNKELSPES
SIELLARPVKGEQIVGDVLPASAGITINVGCTDDQTVTKDGLSYMKDSCFLGGDTVRTNAIIGDGLDEDESLCLYQTARMGDFSYCFRSLEPGDYDVALH
FAEIVFTNGPPGLRVFDVFLQEKKVVSNLDIFARVGANNPLVLSDLKASVGLGEKLSIRLEGVTGTPILCAISVAKDDSASTGEASFPEHIKRSQAAEIE
SQKNADCEMEDDYQKLLTAYECQQRELTEMRKIVEELNRENQVKTKECQNALKTLQDLQSELMRKSMHVGSLAFAVEGQVKEKSRWFSALKDLTEKIEMM
KGDQIKLSEEARSYKACFGEMSEIASTIQSTMKQQSGLHGDLMKKFMEGVRERKELYNKVLELKGNIRVFCRCRPLNSEEIAAGAAMAIDFESAKDGELT
VFSNGVPRKTFKFDSIFSPQANQADVFEDTAAFATSVLDGYNVCIFAYGQTGTGKTFTMEGTKEARGVNYKTLNELFHMIKEREKIFKYEVSVSVLEVYN
EQIRDLLVSNSQPATVKRLEIRPAGDGLHCVQGLVEARVNNVNEAWEVLQTGSNARAVGSTSANDHSSRSHCIHCVMVKGENLLNKECTRSKLWLVDLAG
SERVAKTEVQGERLKETQNINRSLSALGDVIFSLATKSPHIPFRNSKLTHLLQDSLGGDSKALMFVQISPNESDLSETLCSLNFASRVRGIELGPAKRQF
DMPELVRYKQLAEKTRQELKLKDVQIRKMDDTVQGLELKVKEKDIKNKHLQEKIKELESQLLVERKLARQHVDTKIAEQHSKQSDDQTCPPPRPPLGTRL
LGNSSNKASSNGSANVALNKETMDAENFLPSTDVIFKIPDPMEKENNPDMAENLGMQKRTTGRFSICPAPRRNSLIPFSSPSPLPLLPVSLNQDAEKGVC
ESQKEGKTGTRKRNSVLRRSVHKKLQSRSPMQQQIARKGGINVGMEKVRLSIGSRGRMAQRVVLHGSAAAKRVVSKEITTQQKQVSHKEKERGWNNATTT
ARL
|
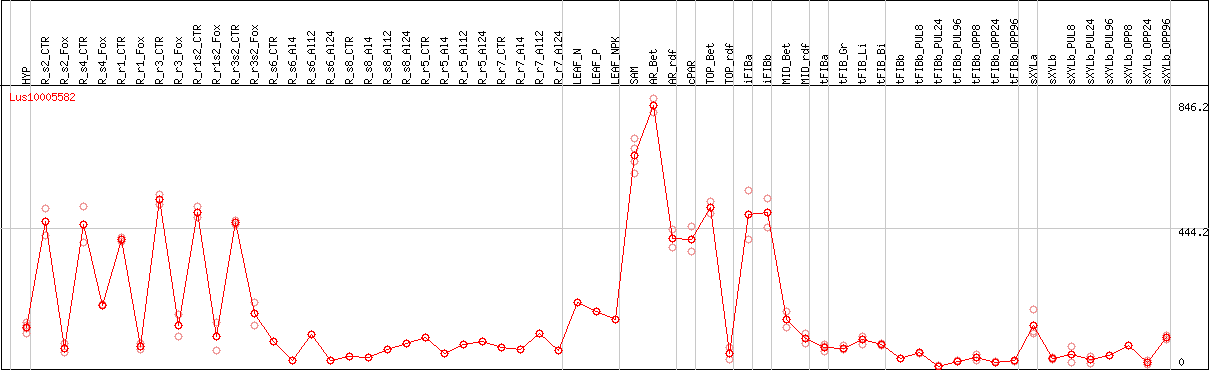
DESeq2's median of ratios [FLAX]
Coexpressed genes
Lus10005582 coexpression network
*The number of genes in the network is adjusted within 50 genes.*Gene name represents symbol(s) of closest Arabidopsis gene if symbol(s) for the gene itself doesn't exist.
*Circle diameter represents the number of connection with other genes within this network.
*Color for gene name represents subnetwork based on the result of network clustering.