Lus10010551 [FLAX]

| External link |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Symbol | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Arabidopsis homologues
|
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Paralogs
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Poplar homologues |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
| PFAM info |
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Representative CDS sequence |
>Lus10010551 pacid=23156698 polypeptide=Lus10010551 locus=Lus10010551.g ID=Lus10010551.BGIv1.0 annot-version=v1.0
ATGGAACGCCTCTGCAAATGGCTGTTGAGAAGCAATGGGGCGGCAATGATTCCTTGCAGAAATCGCACCAGCTATCCCACGATGTCTTCTCTTGGTTCCT
CCATTCCAAAGTTGACCGGCTACGACGCTTGCAAAACGACAAAAAAAAGCTGCTACTTCCTTCGATTTAGACACCTTGTTTCAACTTTACCATTTCACAG
TCAGTCCAACGACTGTCTTCTCTTCTCCGGATCCAACTTCCAGGTAGAAACTACTAGTACCACCGCTTCCATCTCCGACAATATCTCTCCGGTCGGTCTT
CTCTCCTCAGCTCCAACTTGTAGCAACGCACTTGTGAGGACTTCACCATGTCGGACCACTTCATCGCTCCTTGGGATTTGCAGGAAGAGCCGGTGGATGA
GTGCGCGCTATGGTTCACCATCTCCGCTGCAGAATGATCAAATTGTGGGGAATGGGATCCAAAATGGTGGTAATCCGTTTGCTGAGAATGGCTCGCCTCA
AGATAAGAAGCTGGTGAATGATGTTATTAATAATGTAATTAGTGAGCTGAACAGTGTCGATGTTATCAACGAGGAAGTGAATAATGAGAATGGGACTAGC
CAGCCTGGGGAGTCCGGTGAGCTTAGGAATATCCATCCTGGTGACACTGGTGAAGGGTTACCGTATGCTCCTGTGGATTGGCCTAACCCAGGTGACAACT
GGACCTGGAAGGTAGGGAGGAGGATTAACGCTGTTGGGTTCTTCCAAGATAGGTTTTTGTATCCACCAAAACATTTCCCCAAAGTGACAGGTCTGAGAGC
TCCGTTTGCAAGCAGGACTGCTGTTACCAACTATATCCGCACGGTCTTTCCAGATTCGAATGTTGATGCATTTTTCTCATCCTTCGCTTGGAAGGTCCCT
GGAAAGCCGCTGTCACCGGCAAAAGTGGAATTTGTCCCTATCACTTCCCCAAAGCCTTCAGACAATGCAAACAAGGAAGTCGAAGGGCAAGGAGAAGTCT
CTCGTCTGAGAAAAAGGAAGCCAAAATCACCACCTCCACCACCATTGCCACCTCCTCCTAAGAAGAAGAAAACACGGAATGCTGCAAAACCATCATCTGT
ACCATCTAAGCAGAAATCGAACCGGAAATCAATCCAGAAAAATGTAGCTGCATCATCATCTGCAGCTAAGCGAAAAACTCGGCATGGTGCTAAGCAAACT
GTTCCGGTTCCTTTTGCTGATGTGAAGGATGGACAGGCTGAGGAGGAAATGTTCAATATTCCTATACCAGAGGACTTCGACAACTATCTCAACTCTTTAG
AAGACATCATCGCTCAGCCACTATCTGGTTCCATGTCTGTTCAGCAGCCTACAACTAGGGAGTCTCCTTTAGCTGATGAGGAGATAGCTGAAGCTAGGCA
CAGGCTTTCTTCCTTGCTTGTTATGGACTTCCCTTCACTCGTTTTGTCGAAAAACTATGCCGAACTTCCAGGACTAGCTACTAAACTTCGCAAGGATCCA
CATCTGACTGCCGAACAGCTTGTGAAACTGAAGCTGATCGAGGAAATTCCATCGTTCAGGGAAGTGTTTTTGGAGAGTAGGGATATCATAGACCAGATTG
ACAGGCAGTTTGGGACCCTTGATGCTAACAAGGCAAAGGTTGCTTCTCTCAAGAGTGAGTATAGCGAGCTCAAGTACAAAACTGACGAACTTCGGGCACA
AATAGATAGTAACTCTGCAGCCGTCCAAGAAATCAACAATGAAATTGCGAGGCTCCAGGCACGAAAAGCAGAGCTGATTAAGGCAGCCGAATCAAACAAA
GCAGCTAAGCTGGAGGTGAGCTATGCACAGAAGATGGTGGCGAATGCGATCCCGAATGTGGTCCGTGAAATTCAAAATTCAAACTCCGAGGCTCCAGAGT
GGGATGTGAAGAGGAGCAATGCAGTGAAGAGGGAGGAAGAAATACTGGCCAAGTTTGCACCTTTGCAAGGGTTCTCACTGGTTCCATCACCCTTCCAGGT
TATAATCGTCCAATCTGCCTACCATGGGCTTCGCCAGCGGCAAGGACAAATGGCCGTCTTCAGCCCCAATGCGCTCGCGTCGCTTCTCGAATCCGCCGTC
TCAACTCGCCGCCCCCTTCTCGGCAGAGCCACTCATGCCCAAATCATCAAGACTCTTTTTCTTCTTCCTCCCCACCACCTCCCTCCTTTCCTCTCCAACC
ATCTCGTCAGCATGTACTCCAAATTCGGCCTCCCTGGTCCCGCCGAGCTCCTTCTCCGGCTAGCTCCTTCCCGCTCCGTTGTCACCTGGACTTCTCTCAT
CTCCGGATGCGTCCAGAACGGCCACTTCTCCTCCGCCCTACGTCACTTCTCTAACATGCGCCGCGACGACATTCTCCCCAATGATTTCACCCTTCCCTGC
GCCTTCAAGGCGTCCGCTTTCCTCAAGCTTCGCTTCGTAGGACGTCAAGTTCATGCCTTGTCGACTGGGTTGATAGCCGATGCCGAGAAACTGTTCGATG
AAATGCCTGAACGAAATATTGTCACGTGGAATGCGTTTATTTCTAACACTGTTCTGGACGGGAGGCCCAAGGCTGCTATCCAAGCGTTTGTTGAATTTGT
TCGGGTGGGTGGAGAGCCGGATGGGATAACCTTCTTTGCATTTCTGAATGCATGTGCTGATACATTGAACTTAGTGCTGGGGAAACAATTACATGGGTTG
GTGATGCGTAGTGGGTTTGAGACAGAGGTTTCCGTTTCTAATGGCCTTATTGATTTTTATGGCAAGTGTAAGGAGGTTCGATTGGCTGAGATGGTTTTCG
ATGAAATAAAGAGGAGAAATTTGGTTTCGTGGGGTTCAATGGTAGCTACATACGAACAGAATAATGAAAAGGAGAAAGCTTGTATGGTATTTACGGAATG
CAGGAGATTAGGGGTTGAGCCAACTGATTACCTGATTTCAAGTGTGGTCAGTGCTTGTGCAGAACTCGCTGCGCTTGATTGGGAAGACATGTATGGAAAA
TGCGGAAGCATACGTGATGCCGAGCAGACCTTTCGCGAGATGCCTGAGAAGAACTTGTTTGCTTGGAATGCAATGATCAGTGGGTATGCACACCAAGGAC
ATGCTGATATGGCCATCGGATTGTTTGGAGAGATGACTTCTGTGGTTGCTCCGAATTACGTGACATTCGTCTGTGTCTTATCAGCTTGCAGACCAGAGCA
TTATGCTTGTGTTGTGGACATGTTGGCTCGATCCGGATTAGTAGAGCGGGCCTATGATTTTGTGCAAAAACTGCCAATTAGGCCAACAATTTCCATCTGG
GGAGCTCTTTTAAACGCTTGTAGGGTGCATGGGAAGCCGGAGATAGGGAAAATTGCTGCTGATAACCTATTTGAACTCGATCCAAAGGATTCCGGCAATC
ATGTACTGCTGTCAAATATGTTTGCTGTTGCTGGCAGGTGGGAAGAAGCTACTCTTGTGAGAAAAGAAATGAATGAGGTTGGAATCAAGAAAGGCTACAT
CCCAGATACTAACTACGCGCTGTTTGATTTAGAAGAAGAGAAGAAAACAGAAGTTTGGAATCACAGCGAGAAAATTGATCTGGCGTTCTGTCTCATAGCC
ATTCCACCTGGAGTACCAATTAGGATAACGAAGAACCTCAGGATTTGTGGGGATTGCCACAGTGCCTTCAAACTCATATCGGCCATTGTTCGCAGAGAAA
TTTTGGTCAGGGATATCATTTCCGGGATGGTCAATGCTCCTGAAATGATTATTGGTGACTCGTTCACTATTCTATCAAATTTTCGCCGTTCAGAGGTTTG
A
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
AA sequence
|
>Lus10010551 pacid=23156698 polypeptide=Lus10010551 locus=Lus10010551.g ID=Lus10010551.BGIv1.0 annot-version=v1.0
MERLCKWLLRSNGAAMIPCRNRTSYPTMSSLGSSIPKLTGYDACKTTKKSCYFLRFRHLVSTLPFHSQSNDCLLFSGSNFQVETTSTTASISDNISPVGL
LSSAPTCSNALVRTSPCRTTSSLLGICRKSRWMSARYGSPSPLQNDQIVGNGIQNGGNPFAENGSPQDKKLVNDVINNVISELNSVDVINEEVNNENGTS
QPGESGELRNIHPGDTGEGLPYAPVDWPNPGDNWTWKVGRRINAVGFFQDRFLYPPKHFPKVTGLRAPFASRTAVTNYIRTVFPDSNVDAFFSSFAWKVP
GKPLSPAKVEFVPITSPKPSDNANKEVEGQGEVSRLRKRKPKSPPPPPLPPPPKKKKTRNAAKPSSVPSKQKSNRKSIQKNVAASSSAAKRKTRHGAKQT
VPVPFADVKDGQAEEEMFNIPIPEDFDNYLNSLEDIIAQPLSGSMSVQQPTTRESPLADEEIAEARHRLSSLLVMDFPSLVLSKNYAELPGLATKLRKDP
HLTAEQLVKLKLIEEIPSFREVFLESRDIIDQIDRQFGTLDANKAKVASLKSEYSELKYKTDELRAQIDSNSAAVQEINNEIARLQARKAELIKAAESNK
AAKLEVSYAQKMVANAIPNVVREIQNSNSEAPEWDVKRSNAVKREEEILAKFAPLQGFSLVPSPFQVIIVQSAYHGLRQRQGQMAVFSPNALASLLESAV
STRRPLLGRATHAQIIKTLFLLPPHHLPPFLSNHLVSMYSKFGLPGPAELLLRLAPSRSVVTWTSLISGCVQNGHFSSALRHFSNMRRDDILPNDFTLPC
AFKASAFLKLRFVGRQVHALSTGLIADAEKLFDEMPERNIVTWNAFISNTVLDGRPKAAIQAFVEFVRVGGEPDGITFFAFLNACADTLNLVLGKQLHGL
VMRSGFETEVSVSNGLIDFYGKCKEVRLAEMVFDEIKRRNLVSWGSMVATYEQNNEKEKACMVFTECRRLGVEPTDYLISSVVSACAELAALDWEDMYGK
CGSIRDAEQTFREMPEKNLFAWNAMISGYAHQGHADMAIGLFGEMTSVVAPNYVTFVCVLSACRPEHYACVVDMLARSGLVERAYDFVQKLPIRPTISIW
GALLNACRVHGKPEIGKIAADNLFELDPKDSGNHVLLSNMFAVAGRWEEATLVRKEMNEVGIKKGYIPDTNYALFDLEEEKKTEVWNHSEKIDLAFCLIA
IPPGVPIRITKNLRICGDCHSAFKLISAIVRREILVRDIISGMVNAPEMIIGDSFTILSNFRRSEV
|
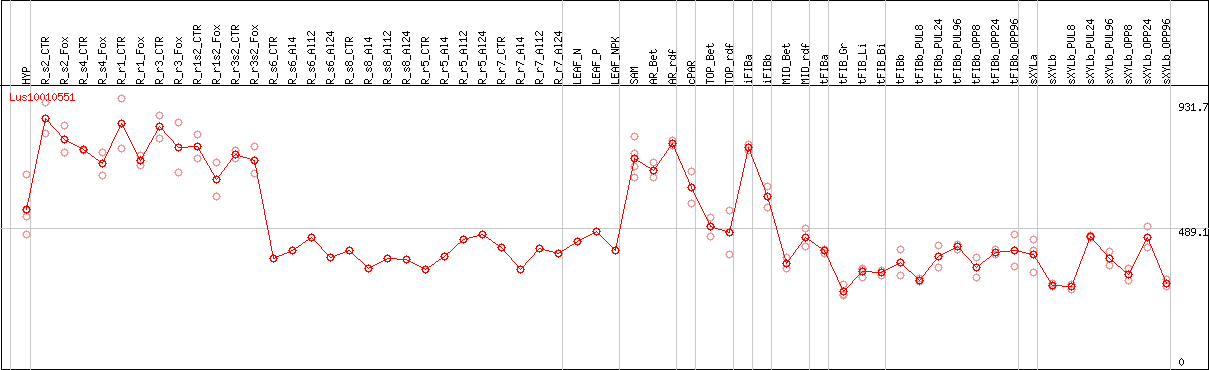
DESeq2's median of ratios [FLAX]
Coexpressed genes
Lus10010551 coexpression network
*The number of genes in the network is adjusted within 50 genes.*Gene name represents symbol(s) of closest Arabidopsis gene if symbol(s) for the gene itself doesn't exist.
*Circle diameter represents the number of connection with other genes within this network.
*Color for gene name represents subnetwork based on the result of network clustering.