Lus10011498 [FLAX]

| External link |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Symbol | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Arabidopsis homologues
|
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Paralogs
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Poplar homologues |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
| PFAM info |
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Representative CDS sequence |
>Lus10011498 pacid=23182651 polypeptide=Lus10011498 locus=Lus10011498.g ID=Lus10011498.BGIv1.0 annot-version=v1.0
ATGGAAGAATCCGGTGAGCGGCGTTTGTTGGTTAATCCAGGCGATAACTCATTTAATAATCGCCGTACTAATTATCCACCAACGGAGATTCAAATCGGTA
ACTCATCCTGTCTCCCTTCGCATCTACTGGCTCCTTTACTTCATCGTCGCCGCTCTGCTCTTCTCCTCCGCCGTCACCAGATTCTTCTCCGCCGCCGCGG
GAGCCCACGGCCGCCTGCTCCTTATCGATCCTCTTCTCTCCCGTTCTGGCTATGGATGAATCCACTACTGAGAAAAGGATACAACACCACTCTCCAGCTC
CAAGACATCCCGTCGTTAGCTCCGTACGACAGAGCCGCCACCATCTCCGCCCAATTCGACTCCAGCTGGCCAATCTCCGCCGCCGCTGACAACAAATCCG
CCACCGCCACCACCACCTCCCACCCCGTCGTTGTCACTCTGCTCCGAGTTTTCTGGAAGGAAATCGCCTTCACGGCATTCCTCGCTATAGTCCGCCTCTG
CGTCACATACGTCGGCCCTGTCTTAATCCAAGACTTCGTCGACTACACAGCCGGCAAACGAACCTCGCCGTATGAAGGATTCTACCTTATCGCCATCCTC
CTCGCCGCCAAATTCCTCGAAGTTTTATCCAACCACCACTTCAATTTCAACACCCAGAAGCTCGGCATGCGAATCCGATCCGCCCTCATCACTTCCCTCT
ACAGGAAAGGGCTTCGGCTGTCCTGTTCAGAGCGGCAGGCTCATGGAGTCGGCCAGATTGTGAATTACATGGCGGTCGATGCTCAGCAGCTCTCGGACAT
GATGCTACAGCTCCACTCGATCTGGCTGATGCCCTTCCAAATAGGGGCTGCTCTGTTCTTGCTCTACGGAGCATTGGGAGCTTCGACTCTAACCGCATTG
GTCGGGATAATTGTGGTGCTCGTGTTTGTCTTCTTCGGCACCAAGAGGAATAACAGCTTCCAGTTCAATCTGATGACGAAACGGGATTCGAGGATGAAGG
CCACGAACGAGCTGCTCAACTACATGAGGGTGATCAAGTTCCAGGCATGGGAGGAGCATTTCCAAAGGAGGATTCAGGACTTTCGAGATTCTGAATTCGA
GTGGCTCTCGAAGTTTTTGTACTCGATTGCGGGAAATCTGGTCGTGATGTGGTGTACCCCGCTCGTGATTTCGACCTTCACTTTCGGGACTGCGATCCTG
CTCGGTGTGAAACTCGATGCTGGGACGGTTTTTACTACCACAACGATATTCAAGATCCTTCAGGAGCCGATCAGGACTTTCCCTCAGTCGATGATCTCAC
TCTCGCAGGCGATGATTTCGCTCGGGAGGCTGGATAAGTTCATGTTGAGTAAAGAGCTAATCGAGGAGAGCGTCGAGAGAACGGAAGGTTGCGACGGTAG
AATCGCTGTCGAAATTCAGAATGGTTGTTTCAGTTGGGATGATGAAGCTGTTGATCAGCCGATTCTGAGAGACATTAATCTCAAAGTCCAAAAGGGGGAG
CTTACTGCAATTGTTGGTACTGTCGGGTCCGGGAAATCATCTCTCCTTGGATCGATTCTCGGCGAGATGCATAAGGTTTCCGGGAAGGTTAGGGTGTGCG
GGTCGACTGCTTATGTTGCGCAGACGTCGTGGATTCAGAACGGGACCATCGAAGAGAATATCCTGTTCGGGTTGGCGATGGATCGGAGTAAGTACAACGA
GGTTGTTAGGGTTTGTAGCCTCGAGAAGGACTTGGAAATGATGGAGTTTGGAGATCAGACCGAGATTGGAGAGAGGGGGATCAACCTTAGTGGCGGACAG
AAGCAGAGGATTCAGCTTGCTAGAGCTGTATATCAGGATTCTGATATTTATCTTCTTGATGATGTTTTCAGTGCTGTTGATGCTCATACTGGAACTGACA
TCTTTAAGGAATGCGTGCGAGGTGCACTGAAAGGCAAAACAATCTTGCTAGTGACCCACCAAGTAGATTTCTTGCACAATGTGGATCTCATCACGGTGAT
GAGAGACGGTAAGATTGTACAATCGGGGAAGTACAACGAGTTGCTCGAGTCCGGAACGGATTTCGAGACACTAGTTGCCGCTCACGACACTGCTATGGAG
CTCGTCGAAGCCGGTACGAGTAATGCAATTATCGATGAACATGATGTTGTCCCCAAAACTCCGAAATCTCCTGGAGGAGAAGCAAATGGAGGAGTGGACA
AGGTGGTGTCATCTTCGGAACAACAGCCGAAATCGGACCAAGGGACCTCGAAGCTGATCGAAGAGGAGGCTCGAGAGACAGGCAAAGTTGGTGGCAACGT
CTACAAGCAGTACTGCACCGAGGCGTTTGGATGGTGGGGTGTTGTGGGTGCGGTCGGGTTGTCGCTTGTCTGGCAAGCATCTCTGATGGCCGGAGATTAC
TGGCTAGCTTACGAGACTTCGGCTGACAGAGCTGAAACTTACAATCCAAGTTTCTTCATTTCTGTGTATGCAATCATTGCGGCTGCATCGGTAGTGATCT
TGGCGTTAAGAGCGGTGTTTGTTACCGTCATGGGACTCAGGACTGCACAGATTTTCTTCCATGGCATCCTTAACAGCATCTTGCGAGCTCCGATGTCCTT
CTTCGATACCACGCCCTCTGGCAGAATCCTGAGCAGGGCGTCAACCGATCAAGCAAACATCGATCTCTTCCTGCCGTTCATCCTAGGCTTGACGCTGGCG
ATGGACGCGGCACTTTCGGACATCTTTGTCGTGGTTTGCCAAAAACCTTGGGCCAAGGAAGTAAAAAAAAAAAAACCAGTGATCCATCATTTCTCGGAGA
GCATTGCCGGGGTGATGACGATCAGGTCATTCAGGAAGGTTGGGAGGTTCTGCCAAGAGAATGTGATCAAAGTTGACTCCAACCTCCGGATGGATTTCCA
TAACAACAGCTCGAATGAGTGGCTAGGGCTCCGGCTCGAGCTTATTGGCAGCGCCATCCTCTGCTCTTCTGCTGTCCTCTTGATTGTCTTGCCTAGCAGC
ATCGTCAATCCAGCAAACGTTGGGCTCTCCCTATCTTACGGGCTGTCCCTAAACTCGGTCCTCTTCTTCGCAATATACACGAGCTGCTTCGTGGAGAACA
GGATGGTTGCAGTGGAGAGGATAAAGCAATTCACAAACATAGCATCAGAAGCAGCTTGGAGGATTCCTGACAGGAAACCTCCACCAAGCTGGCCAACTCA
GGGCAGAGTGGACCTTCAGGATTTGCAAGTCCGGTACCGACCCAACACTCCTTTAGTTTTGAAAGGGATCACCCTCAGCATCAATGGCGGGGAGAAAGTG
GGGATCGTGGGGCGGACCGGGAGTGGAAAGTCAACTCTGGTTCAAGTGTTCTTCAGGCTTGTGGAGCCTTCTTCAGGGAAAATCATCATCGACGGGCTCG
ACATCTCCACCCTGGGCCTCCATGATCTCCGGTCTCGATTCGGGATCATCCCTCAGGAGCCTGTTCTGTTCGAAGGGACTGTCAGGAGTAATGTCGACCC
CGTTGGTTTGTACTCCGACGACGACATTTGGAAGAGTCTTGAACGGTGCCAACTGAAGGATGTTGTAGCTGCCAAGGCTGAGAAGCTGGATGCTGCTGTG
AGCGACAGCGGGGAGAACTGGAGCGTGGGGCAAAGGCAGCTGCTATGCCTAGGGAGGGTGTTGCTAAAGAAGAGCAGACTTCTATTCATGGACGAAGCAA
CGGCATCGGTGGATTCGAAGACCGACGCGGTGATACAGAGGATAATAAGGGAGGATTTCGGTTCGTGCACGATCATCAGCATCGCTCACAGGATCCCAAC
AGTCATGGACTGCGATCGTGTCCTTGTCGTTGATGCCGGTCTGGCGAAAGAGTACGACAAGCCGGCCAAGTTGCTGGAGAGGCAGTCGCTGTTTGCAGCG
TTGGTTCAGGAGTATGCGAACCGGTCGGCCGGTCTATGA
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
AA sequence
|
>Lus10011498 pacid=23182651 polypeptide=Lus10011498 locus=Lus10011498.g ID=Lus10011498.BGIv1.0 annot-version=v1.0
MEESGERRLLVNPGDNSFNNRRTNYPPTEIQIGNSSCLPSHLLAPLLHRRRSALLLRRHQILLRRRGSPRPPAPYRSSSLPFWLWMNPLLRKGYNTTLQL
QDIPSLAPYDRAATISAQFDSSWPISAAADNKSATATTTSHPVVVTLLRVFWKEIAFTAFLAIVRLCVTYVGPVLIQDFVDYTAGKRTSPYEGFYLIAIL
LAAKFLEVLSNHHFNFNTQKLGMRIRSALITSLYRKGLRLSCSERQAHGVGQIVNYMAVDAQQLSDMMLQLHSIWLMPFQIGAALFLLYGALGASTLTAL
VGIIVVLVFVFFGTKRNNSFQFNLMTKRDSRMKATNELLNYMRVIKFQAWEEHFQRRIQDFRDSEFEWLSKFLYSIAGNLVVMWCTPLVISTFTFGTAIL
LGVKLDAGTVFTTTTIFKILQEPIRTFPQSMISLSQAMISLGRLDKFMLSKELIEESVERTEGCDGRIAVEIQNGCFSWDDEAVDQPILRDINLKVQKGE
LTAIVGTVGSGKSSLLGSILGEMHKVSGKVRVCGSTAYVAQTSWIQNGTIEENILFGLAMDRSKYNEVVRVCSLEKDLEMMEFGDQTEIGERGINLSGGQ
KQRIQLARAVYQDSDIYLLDDVFSAVDAHTGTDIFKECVRGALKGKTILLVTHQVDFLHNVDLITVMRDGKIVQSGKYNELLESGTDFETLVAAHDTAME
LVEAGTSNAIIDEHDVVPKTPKSPGGEANGGVDKVVSSSEQQPKSDQGTSKLIEEEARETGKVGGNVYKQYCTEAFGWWGVVGAVGLSLVWQASLMAGDY
WLAYETSADRAETYNPSFFISVYAIIAAASVVILALRAVFVTVMGLRTAQIFFHGILNSILRAPMSFFDTTPSGRILSRASTDQANIDLFLPFILGLTLA
MDAALSDIFVVVCQKPWAKEVKKKKPVIHHFSESIAGVMTIRSFRKVGRFCQENVIKVDSNLRMDFHNNSSNEWLGLRLELIGSAILCSSAVLLIVLPSS
IVNPANVGLSLSYGLSLNSVLFFAIYTSCFVENRMVAVERIKQFTNIASEAAWRIPDRKPPPSWPTQGRVDLQDLQVRYRPNTPLVLKGITLSINGGEKV
GIVGRTGSGKSTLVQVFFRLVEPSSGKIIIDGLDISTLGLHDLRSRFGIIPQEPVLFEGTVRSNVDPVGLYSDDDIWKSLERCQLKDVVAAKAEKLDAAV
SDSGENWSVGQRQLLCLGRVLLKKSRLLFMDEATASVDSKTDAVIQRIIREDFGSCTIISIAHRIPTVMDCDRVLVVDAGLAKEYDKPAKLLERQSLFAA
LVQEYANRSAGL
|
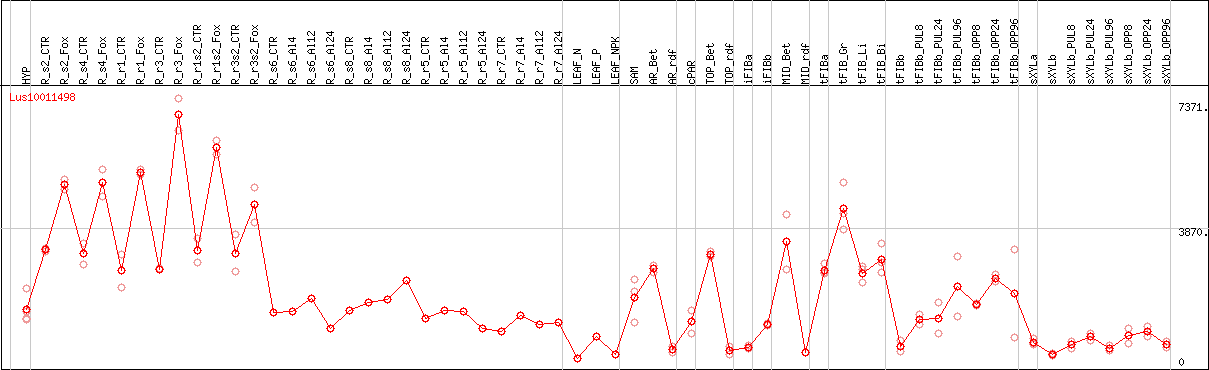
DESeq2's median of ratios [FLAX]
Coexpressed genes
Lus10011498 coexpression network
*The number of genes in the network is adjusted within 50 genes.*Gene name represents symbol(s) of closest Arabidopsis gene if symbol(s) for the gene itself doesn't exist.
*Circle diameter represents the number of connection with other genes within this network.
*Color for gene name represents subnetwork based on the result of network clustering.