Lus10011568 [FLAX]

| External link |
|
||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Symbol | |||||||||||||||||||||||||||||||||||||||||
|
Arabidopsis homologues
|
| ||||||||||||||||||||||||||||||||||||||||
|
Paralogs
|
|
||||||||||||||||||||||||||||||||||||||||
|
Poplar homologues |
|
||||||||||||||||||||||||||||||||||||||||
| PFAM info | |||||||||||||||||||||||||||||||||||||||||
|
Representative CDS sequence |
>Lus10011568 pacid=23140386 polypeptide=Lus10011568 locus=Lus10011568.g ID=Lus10011568.BGIv1.0 annot-version=v1.0
ATGGCGAGCCCGATTATGCCGAGCAGCAGTGGTAGTAGTAGGGCGTTGTCGCTGACTCCGGGCGCGAGGGTTAAGCCGGTGAGCGACGATAGCACGATCT
GGATGCGGCTTAAGGAGGCTGGGTTCGATGAGAATTCGATTCAGAGGAGGGACAAGGCTGCTCTGATTTCGTACATCGCTAAGCTCGAAACTGAGAACTT
TGATCTGCAACACCACATGGGTCTTCTACTATTGGAGAGAAAGGAATCGTCTGAAAAGTATACACAACTGGAAGCTACAGCAGAAGCTTCTGACCTGTTG
CGAAGACGTGAACAAGCAGCTCATGCAACTGCCTTGGCAGAGGCAAAGAAAAGAGAAGAAAGTTTGAAGAAGGCTCTAGGAGTTGAGAAAGAGTGTATAT
CTAGTATAGAGAAAACCCTGCATGAGATGCGTGCAGAATGTGCAGAGACCAAAGTTGCAGCTGAATCTAAATTGGTTGAAGCACACAATATGGTAGAAGA
AACCCAGAAAAAGATCGTCGATGCAGAAGAGAAATTGCGCACAGCGGAATCTTTGCAAGTTGAAGCCAACTGTAGTAAGCGAGCTGCTGATAGAAAACTC
CAGGAAGTTGAAGCACGTGAAAGAGATCTTACTAGGCGTATGAGTGAATTTAAATCTGATTGCAATGCTAGAGAGAAGGAAGTTGACCTCGAGAGGCAGC
ACCTGAGTGAAAGGAGGAAGTTTCTCCAACAGGAGCATGAGAGATTGCTGGATGGCCAAATGCTTTTGAACCAGAGGGAAGATTACATTGCCAGTAAATC
TCAAGAGCTTAGCCGGGTGGAAAATGAGTTGGAAGTATCAAGGGCTAAACTTGAAGAAGAACGTAGACGCCTTAAAGAGGAGAAGTCTAAATTGGAGTTG
GCAATGGCGTCTCTGTCTCAACGAGAACAGGCTCTTGCTGAGAGGGAAAATAACTTGAACAAGAGAGAGCGGGATCTACTTGTTATGCAGGAAAAGCTTG
CCTGCAAAGAATCTGCTGCAATAAGAAAGGTCAGTGCCAATCATGAGGCGATTCTGAGAACCAGAAAGTCAGAATTGGAAGCTGAGTTACAAGTGAGGCG
TAAGGAATTTGAAGATGAGCTTGAGTCGAAAAGAAGGGCTTGCGAGTTGAGGGAGGTTGATCTTAGCCAACGTGAAGATGAGTTGCGAGAGAAGGAACAT
GAGTTGGATGCTCAAACTAGAGGTCTAGCAGAGAAAGAGAAGGATGTGGCGGAAAAGATTAGCATTGTTGATGAAAAAGAAATGCGGTTAGTCAATGCTG
AAAAGGATATTGAGATTAAGACAACCCTTTTACATAAAGAAGCAGAAGAAATTAAACGCATCAAACTAGAGCTTCAGGAGTCATTGGTTTCCTTGGAAGA
CAAAAGGTTGCAGGTTGATAGTGCCAAGGATAAGTTGGAGACCATGAAAACTGAAACACATGAGCTGTCGGATCTGGAAGTCAGACTAAAAGAAGAAGTT
GACCTTGTGAGGGCCCAAAAAGTTGAGCTCTTGACTGAAGAGGAGCGACTAAAAGTGGAGAAGTCTAAATTCGAAGCTGAGTGGGAGTTAATTGATGAGA
AAAGAGAGGAGTTGCGTAAAGAAGCCGAACGTGTGGCTGTCGAGAGAGAAGCCATTTCCAAGTTGTTGAAGGATGAGCGTGATAGCTTAAGATTAGAAAA
GGAAACGATGCGTAACGAACATGATCGTGATGTCGAGTTGTTGAATAGTGAGCGGGAGAAATTCATGAATAAGATGATTCATGAGCGCTCCGACTTGTTT
AACAAGATTCAGAAGGAGCACACGGATTTCTTGTTGGGAATAGAGGTGCGGAAGAGGGAATTGGAGAATAGCATTGAAAAGAGACGCGAAGAAGTCGAAT
GTTATCTTAAAGACAAGGAGAAAGCTTTTGATCTCGAGAAAAGGAATGAAATGGAGAACATACACTCTCTCAAAGAAAAGGCAGAGCGAGAACTGAAGCA
AGTGGCTCTGGAAATGGAGAAGCTTGATGCTAAGAGACAAGAGCTTCTTGGGGATCGTGAACATATGGAGAAAGAGTGGGCGGTATTAAGCGGCTCTATT
GAGGAACTCAAGAGTCAAACGGAGAGACTGCAGAAGCAGAGGGAATTGCTTCACGTCGAGAGTCAAGAAGTATCTACTCAAATCGAGGATTTGAAAAGGC
TGGAAGATTTGAAACTTAAACTGGAGAATATGGAAGTAGCTCAAATGCAATTGTCGAGCATTGAACGTAGCCAGCAGAAGCTCTCCGAAATAAAGTATCT
CAGGCAACATGCTATAGTGAATAATGGATCCGCGGAGGTTCAAAGACATAATCTTGCTTCACCTGGTAGTTCTTCTGCTCGTTTCTCGTGGATAAAACGT
TGCGCTGATGTTATTTTCAAGAATTCTCCTGAGAACTTGAAGAGTGAAGAGAAAGTGATTGTGGAAGTTCCCTCTGTGCTTAAGGTTGGCTGGAAAAGGA
GAGTAAATGACTCTTCTTTCGAAAATCCCGCTGAGCCCGAGTCCAGCAGCCAGAACCCCAGTAATAAGAAACAACGGCAGCAACCGCTACTGGAAGGGGG
GCNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNN
NNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNN
NNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNN
NNNNNNNNAAGAAAAGGAAAGGGGGGAGAAAACAGTCGGGGGTAGGACAAGGTCAAAAACAGAGGCGGTGGTAGCAGCATAG
|
||||||||||||||||||||||||||||||||||||||||
|
AA sequence
|
>Lus10011568 pacid=23140386 polypeptide=Lus10011568 locus=Lus10011568.g ID=Lus10011568.BGIv1.0 annot-version=v1.0
MASPIMPSSSGSSRALSLTPGARVKPVSDDSTIWMRLKEAGFDENSIQRRDKAALISYIAKLETENFDLQHHMGLLLLERKESSEKYTQLEATAEASDLL
RRREQAAHATALAEAKKREESLKKALGVEKECISSIEKTLHEMRAECAETKVAAESKLVEAHNMVEETQKKIVDAEEKLRTAESLQVEANCSKRAADRKL
QEVEARERDLTRRMSEFKSDCNAREKEVDLERQHLSERRKFLQQEHERLLDGQMLLNQREDYIASKSQELSRVENELEVSRAKLEEERRRLKEEKSKLEL
AMASLSQREQALAERENNLNKRERDLLVMQEKLACKESAAIRKVSANHEAILRTRKSELEAELQVRRKEFEDELESKRRACELREVDLSQREDELREKEH
ELDAQTRGLAEKEKDVAEKISIVDEKEMRLVNAEKDIEIKTTLLHKEAEEIKRIKLELQESLVSLEDKRLQVDSAKDKLETMKTETHELSDLEVRLKEEV
DLVRAQKVELLTEEERLKVEKSKFEAEWELIDEKREELRKEAERVAVEREAISKLLKDERDSLRLEKETMRNEHDRDVELLNSEREKFMNKMIHERSDLF
NKIQKEHTDFLLGIEVRKRELENSIEKRREEVECYLKDKEKAFDLEKRNEMENIHSLKEKAERELKQVALEMEKLDAKRQELLGDREHMEKEWAVLSGSI
EELKSQTERLQKQRELLHVESQEVSTQIEDLKRLEDLKLKLENMEVAQMQLSSIERSQQKLSEIKYLRQHAIVNNGSAEVQRHNLASPGSSSARFSWIKR
CADVIFKNSPENLKSEEKVIVEVPSVLKVGWKRRVNDSSFENPAEPESSSQNPSNKKQRQQPLLEGGXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXEKERGEKTVGGRTRSKTEAVVAA
|
DESeq2's median of ratios [FLAX]
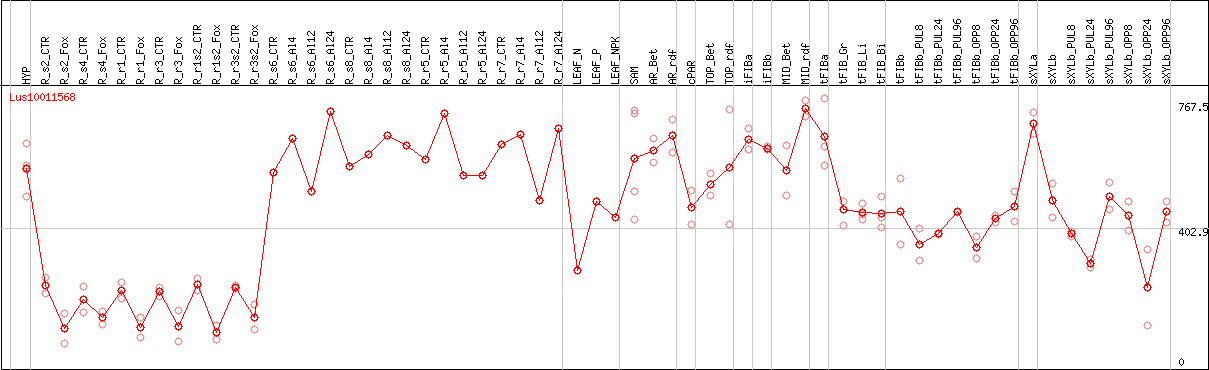
Coexpressed genes
Lus10011568 coexpression network
*The number of genes in the network is adjusted within 50 genes.*Gene name represents symbol(s) of closest Arabidopsis gene if symbol(s) for the gene itself doesn't exist.
*Circle diameter represents the number of connection with other genes within this network.
*Color for gene name represents subnetwork based on the result of network clustering.