Lus10012867 [FLAX]

| External link |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Symbol | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Arabidopsis homologues
|
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Paralogs
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Poplar homologues |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
| PFAM info |
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Representative CDS sequence |
>Lus10012867 pacid=23162981 polypeptide=Lus10012867 locus=Lus10012867.g ID=Lus10012867.BGIv1.0 annot-version=v1.0
ATGGGTAGAAAGAAGCAATCCAGGCCTCACAGGTCTGGTGGTCTAGTCATACAACCGGGTGAAGATGCTTCTGGATCAGAATTTGAGAAAGGAAAGGCTA
CTGAAGAAGCTGAGGCTACACAACAGAAAGATGATCCCTTTTTCATTCAAGTGGATAGAACTGAGTGGAGTTCAGTGGAGCACTTTGATCTTGCTGAAGT
TGTTCTTACCAATTTGTGTTTAGGTGAACGATATCATACTTTCACAATAGATGCCGACTTTTATCACGAGTCGAAGTACTCGTTACGGATACGTGTTTCC
AGTCTTAATGATAGTGCTCTTAACGGTATAAAGTTTGCTCATTGGCCCGTGGTGTCATCCGACGATGCAAAGCTCGAGTTTGTTGAGAATGGGGAAGAGA
GGGAGAAGTTTGTAGTGATGTCAGGGTGTTTTGATGGGCCGGATGAGGGTGTTTCTGGCCTTAGTCACTTGATAAGATTGAATTTTTTGACATTGAGGCC
TGTTCCGGGGTTCGAATATTCAGAGGGCGGGATGAAGTTGAGGGTTGAGGTGATCAAGGATGCTCTTGATGCTTGTGAGTCACTTCTGGAGAACAACAGG
CAGGACTGGAAGAAAAGTATGATGGATGTGATGGGTTGGCTTCGACCAGAAGTCATGATCTCAGAGGCTAGATATGGAGTGACTAGTAGATCAATGGAGA
TCGACAATGATGGTTCTACCTCCAGGAAGCGTGCAGGTTTTGATGTTGCTGAATTTTATGAAGCAATCAAGCCATCAAAATCGGAGCCGATGCTTGAAGA
TGACTTGCCTGACTTGGTTCCAGTACTTAGACCCTATCAGCGGCGTGCAGCATACTGGATGGTGGAAAGAGAGAAATGGCATACTCTTGATGAAAATGAA
AAAAGTGACTTCTTTTCTCCTGTGAGTTTGCCCGTGAATTTCCTTGATTCATGCACAAGAATGTTCTACAATCCATTCAGTGGCAATATTTCGCTACAGC
CTGAAAGCTCTGCACCACCCATCTTTGGTGGGATTCTTGCTGATGAGATGGGTTTGGGGAAAACTGTCGAAGTGCTTGCCTGTATATTTTCTCATCGACG
ATCCGAATCTAACGGGGACATCATGATTGATCGTGGACAAAAAGATACCGAAAGTCAAAAGGTTCTTAGAAGATTGAAAAACGAGCGAGTGGAGTGCGTT
TGTGGAGCTGTAACGGAAAGTTACAAATACAAAGGACTGTGGGTACAGTGCGACATGTGTGATGCTTGGCAACATGCAGATTGTGTTGGTTATTCACCAA
ATGGAAAACGAAAGAGGTCAACTTCTGTTTTACAAAAGGATCGAAAGAAGACCACTATCAGCTTTGTCGAAAGAGAAGGACAGCATATGTGTCAGATGTG
CTTGGAACTATTACAAGCTACCGACTCTCCTGTTCCCTCTGGTGCCACTCTTATCGTATGTCCGGCCCCTATACTGTCTCAGTGGCATTCTGAAATTATC
CGGCATACGCAATCCGGTTCCCTAAAAGTTTGTATTTACGAGGGTGTACGAAAGGCATCTCTTTCAAACACACCTGGGATTGATATTGGGGAGCTTGTTG
GTGCAGACATTGTACTAACTACATATGATGTGCTTAGAGAGGACCTCTCCCATGACTCAGATAGGCATGAAGGTGATCGACGCCTCTTGAGATTCCAGAA
GAGGTACCCTGTTACTCCAACTCATCTTACAAGAATATTTTGGTGGAGGCTTTGCTTGGATGAGGCACAAATGGTAGAAAGTAATTCTTCAGCTGCAACA
GAGATGGCTCTCCGGCTATCTGCTAAGTATCGTTGGTGTGTTACAGGGACTCCTATACAACACCGACTCGATGACTTATATGGACTTCTGAGATTCCTTA
AAGCAAGCCCCTTTGATGTTTGTAGGTGGTGGATTGATGTTATAAGAGATCCATACCAGAGGCAAGACGCAGGAGCTATGGAATTTACACACAAGTTCTT
TAAACAAATCATGTGGCGTTCTTCAAAAGCTCACGTAGCAGATGAGTTGCAAATTCCGCCTCAGGAAGAGTGCATATCATGGCTTGCTCTTTCGCCAACT
GAGGAACATTTTTACCAAAGACAGCATGAGACTTGTGTGATTTATGCTCATGAAGTTATCGGTCGTTTGAAAGCTGATATTGCGAAAAGAGAAACCTCCG
GAGGTATCGATCGTCCTCCTCCTTTATTTGAATTAAGAATAACATTTTACCTTCGCCTAAGCAGCTTCCTTTTCTCTATGCTTTTTTTTCAAGCAGATTG
CAAATCTTCTAGTTTGACCAATCCACTCATCACCCACTCAGAAGCTGCAAAGTTACTCACCTCTCTCTTGAAGCTTCGTCAGGCTTGCTGCCACCCTCAA
GTAGGAAGTTCGGGATTGCGTTCTCTACAGCAATCGCCGATGACAATGGAGGAAATCTTACAGGTTCTTGTTAGTAAGACCAAGATAGAAGGGGAGGAGG
CTCTCAGGAAGCTAGCTGTCGCTTTAAACGCCCTTGCAGGAATAGCTATCATCAAACAGAATTTCAGTGATGCTGTAACATTGTACCGAGAAGCATTGGC
TCTTGCCGAGGAGCATTCCGAAGATTTCCGCCTTGACCCTTTATTGAATATTCACATTCATCACAACCTTTATGACGTGCTTCTCAAGGAATCTGGCCAC
AGTTCAGAAACCTCTTCACATGGAGACCATTCTGACCAGGACAAGTCTCTGAGTGTAGCATGTGAGAGTTTGAAACAGAAATATCTTTCTGTGTTTAGCT
CAAAGCTCTATGTAACTCAGCAGGACTTCAAAAAATCACACATGCAGGTTGTTAACGAGTTTGGCAAGTCGAAAGATCAACATTCCTTTTGGTGGTTGGA
TACGCTCGATCATTCTGAACAAAACAAGGGCTCAGCAAATGAACTGATAACAAAGATTGAAGAAGCCATCTCTGGAAGTCAAAAAGCTTCGAAGTCAACA
AGAGTTCCATCTCGTTTCCGGAGCATTGCAGCCCTGAAGTACCACATTCAGGCTCGTTTCGACCAAGTGGTAACGTCCAGAGAATCATTGCTTGACCGAG
TGCTGGAAATCGATCGATCAATGGAGAATCCGAAAGAAGAGGATATAGAACGTGTAAGATACTGTCGAGTTTGTCAAGCTGTTGATGATGGCCCCACATG
TGTTCATTGTGAACTGGAAGAACAATTCAAGGATTATGAAGCAAGGCTGTTTCGTCTCAACAAAGCAGATGGAGAAATCATATCTTCTGCTGAAGAAGCA
GTGGATTTACAAAAGAAGAACTCCGAGCTGAACCGTTTCTATTGGAATTTATCACGGCAAGAGAAAAACACAATCGTGTCCGGTGATGGAAACGATGAAT
CGAGGAAGAGAGATATAGGGGAAAGAGTTGTGGTTTCAAAGATGCCATCTGAACTCGAGGTTGTGTTTGGAGTTGTAAAAAGCTATTGTAAGGCTCATTT
GAGCAAGGAGCACTTATTAGCAGCCAATAAGCAGCTTCATTTACTGGAGAGCATGAGGAAGGAGTACAGTTCTTCAAGGTCGCTGGCGGTTACTCAAGCT
CAGTTTCTGCGTGCTCATGACGAAATTAGGATGGCAACATCGAGACTGCATCTAAGAGAGGACGAGAACGATAATTCTCTCGACGCATTAGGTCCAGAGG
AACTCGATACAGCTAGTGTGCAGCAATCTAGTGACAAGTTCTTGGCTCTGACTTCTTTGTCGAGCATTAAAGGAAAACTACGTTACTTGAAGGGTTTGGT
GCAATCAAAACAGAAAGTTCCTTCTGATAGTTCAAATAACTTGTTATCAAAAACTCAAGAAACAACCTCAGTATCGGTATCGACAGACACGAGAAATGAC
GTTCTACCTAAAGACGATGAAGAAGCATGCCCTATCTGTCATGAAAAGCTAAGCGATGAAAAGATGGTCTTCCAATGCGGGCACTTTATTTGCTGTAAAT
GCTTATTGGCGATGACAGAACCGAAAGAGCCTCAGGATCGCAAGTTCCAGTCGCTAAAATGGGTGATGTGCCCAACATGTCGACAGCATACCGATTATCG
GAATATTGCTTATGTCGACGACAGAAAAGGCAAAAAATCCTCGAATTCAGGTAATCTGCCAACCACACAAGATTCCTTGAGGGGCGAAGCATCCTTAATT
GTCCACGGTTCGTATGGTACTAAGCTCGAAGCTGTGACACGAAGAATACTGTTGATAAAATCATCAGATTCCAACGCCAAAGTTCTCGTTTTCTCAAGCT
GGAACGACGTCCTGGATGTATTAGAACATGCTTTCAAGGCAAACGGGATAACGTATATCCGAATGAAAGGTGGCAGGAAATCAGATGATGCCATTAGTGA
GTTTAGAGGGCAGAACAAGAAAAAGGCAGAATCGATCCAAGTTCTATTGCTGTTGATTCAACATGGAGCGAATGGACTCAATCTGTTGGAAGCGCAGCAT
GTTGTGCTTGTTGAGCCATTGCTGAATCCCGCTGCAGAAGCACAAGCAATCGGCAGAGTGCACCGAATCGGGCAGGATAAGAGGACACTCGTGCATCGTT
TCATTGTTAAAAATACTGTGGAAGAGAGCATACACCAACTGAACAGGAGCAGGAACACGAAATCGTTCGTGAGCGGGAAGACTAAGAACCAAGATCAGCC
TGTTTTGACGCTGAAAGATGTCGAGTCTCTCTTTGCCTCTTCTTCTTCGACGTTCAAGAATGGCGAAGAAGAGCCGAATGGGAACAGTAGTAGTAGCTTA
AGACAGCTTCCGCCAGGCGTGGCAGCTGCCATGGCAGCTGAGAGGAGACTCCTGGAGAATGGAATCTCAACTTCTTCAGTATTATCTTCATCTCCAGCTC
CAAATCTCAAATTCTTAAGAATCTGTGACTTCTCGTATGACTACTACGCACGTGACTCCCAGAAGTTCACGCAGGAGGAATTCAATGAGATTACTTCCAA
TCTGCCGTCTCTGGAGTCTCTTTCTATTGCAGACAAGAGATTCGCAAGCGGTAAGTGCTGGCTAAGGATTTCGAATCCGCCTTACAAGCTTAGAGAGTTC
AGCTTGATAAGTAGTATGACTCCAAATCTAGCCGTTGTTGAACATTTGATATTGGAGACCAGTCATGAGACAAATATGTGGAGAGATTCTCAATTTAGCC
AAGAAGGACATGTTCTCCATGGTTGTGTTTCTATGTGTCCTCCTAAGCTTATGTCGGCCTTTCAGATTCGCCAAATACAGTTACAAAATGGTATGCACTT
CCCTGAGGAGGAGAAGAAACCAGCGGCGGAATCGGAAGTAGAGAAAAAAACAGAGGACGAGGAGAAAAAACCAGAGGAAGAGAAAAAAACAGACGAGAAA
CCGGCAGGAGAGGAGAAGAAGCAGGAGGAGGCGCCGCCGCCGCCGCCGCCGCCAACGCCAACGCCAACGCCGCCGCAGGAGATTGTGTTGAAAGTGTTCA
TGCATTGCGAGGGATGCGCGCGTAAGGTGCGGCGATGTCTTAAAGGGTTTGAGGGGGTTGAGGAAGTGACGACGGACTGCAAAAGCAACAAGGTTGTAGT
GAAGGGGGAGAAAGCAGATCCGATCAAGGTTCTGGAGAGAATACAGAGGAAGAGCCATAGGCAAGTTGAGCTCATTTCCCCTGTTCCCAAACCACCTGAG
GTTGAAGCAGACGAGAAACCCAAGCCTCCTGCTGAAGAACCCAAACCGGAGCAGCCTCCACCGGTGGTGATCACAGTTGTGCTGCAGGTTTACATGCATT
GTGAAGCTTGTGCTATGGAGATCAAGAAACGGATTCAGAGAATGAAAGGCATGCTGCTCTCTTTCATTAATTGTTTTCCGTTGAGGTTTTCTAGTCCACC
CGATTTTTTTTTCTTAACCACTGATTTTAAAATTGACCTCGGGGTGGAATCGGCGGAACCAGAGCTGAAGAGTTCTCAGGTGACGGTGAAGGGAGTATTC
GAAGCTGAGCAGCTGGTGGAATACGTCCGCAAACGGACAGGGAAGCAAGCTGTGATCGTGAAGCAAGAGCCGGAAAAGAAGGAAGAGAAAGCCGGGGAAG
ATAAAGAAGGCAAAGAGGATTCTTCTAAGGAGGAGGAGAAGAAGAAAGGCGACGAATCACCCTCCGACGACAATGCTAAGAAGGAGGAAGTAGACAAGGG
GAAGCCAGCTGAGGAGGGGGATAAGCAGAAAAAGGAAGAAGGGGATGCCAAAGAGACAGAGGCACCGGCCGCGGCAGGAGAAGAGACTACTACTAAAGTG
GTGGAGGTGAAGAGGAATGAGTGCTACTATTACCCTCCGAGGTACGCCATGGAATTGTACGCTTACCCTCCTCAGATCTTTAGCGACGAAAATCCTAATG
CTTGTGCCGTTATGTGA
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
AA sequence
|
>Lus10012867 pacid=23162981 polypeptide=Lus10012867 locus=Lus10012867.g ID=Lus10012867.BGIv1.0 annot-version=v1.0
MGRKKQSRPHRSGGLVIQPGEDASGSEFEKGKATEEAEATQQKDDPFFIQVDRTEWSSVEHFDLAEVVLTNLCLGERYHTFTIDADFYHESKYSLRIRVS
SLNDSALNGIKFAHWPVVSSDDAKLEFVENGEEREKFVVMSGCFDGPDEGVSGLSHLIRLNFLTLRPVPGFEYSEGGMKLRVEVIKDALDACESLLENNR
QDWKKSMMDVMGWLRPEVMISEARYGVTSRSMEIDNDGSTSRKRAGFDVAEFYEAIKPSKSEPMLEDDLPDLVPVLRPYQRRAAYWMVEREKWHTLDENE
KSDFFSPVSLPVNFLDSCTRMFYNPFSGNISLQPESSAPPIFGGILADEMGLGKTVEVLACIFSHRRSESNGDIMIDRGQKDTESQKVLRRLKNERVECV
CGAVTESYKYKGLWVQCDMCDAWQHADCVGYSPNGKRKRSTSVLQKDRKKTTISFVEREGQHMCQMCLELLQATDSPVPSGATLIVCPAPILSQWHSEII
RHTQSGSLKVCIYEGVRKASLSNTPGIDIGELVGADIVLTTYDVLREDLSHDSDRHEGDRRLLRFQKRYPVTPTHLTRIFWWRLCLDEAQMVESNSSAAT
EMALRLSAKYRWCVTGTPIQHRLDDLYGLLRFLKASPFDVCRWWIDVIRDPYQRQDAGAMEFTHKFFKQIMWRSSKAHVADELQIPPQEECISWLALSPT
EEHFYQRQHETCVIYAHEVIGRLKADIAKRETSGGIDRPPPLFELRITFYLRLSSFLFSMLFFQADCKSSSLTNPLITHSEAAKLLTSLLKLRQACCHPQ
VGSSGLRSLQQSPMTMEEILQVLVSKTKIEGEEALRKLAVALNALAGIAIIKQNFSDAVTLYREALALAEEHSEDFRLDPLLNIHIHHNLYDVLLKESGH
SSETSSHGDHSDQDKSLSVACESLKQKYLSVFSSKLYVTQQDFKKSHMQVVNEFGKSKDQHSFWWLDTLDHSEQNKGSANELITKIEEAISGSQKASKST
RVPSRFRSIAALKYHIQARFDQVVTSRESLLDRVLEIDRSMENPKEEDIERVRYCRVCQAVDDGPTCVHCELEEQFKDYEARLFRLNKADGEIISSAEEA
VDLQKKNSELNRFYWNLSRQEKNTIVSGDGNDESRKRDIGERVVVSKMPSELEVVFGVVKSYCKAHLSKEHLLAANKQLHLLESMRKEYSSSRSLAVTQA
QFLRAHDEIRMATSRLHLREDENDNSLDALGPEELDTASVQQSSDKFLALTSLSSIKGKLRYLKGLVQSKQKVPSDSSNNLLSKTQETTSVSVSTDTRND
VLPKDDEEACPICHEKLSDEKMVFQCGHFICCKCLLAMTEPKEPQDRKFQSLKWVMCPTCRQHTDYRNIAYVDDRKGKKSSNSGNLPTTQDSLRGEASLI
VHGSYGTKLEAVTRRILLIKSSDSNAKVLVFSSWNDVLDVLEHAFKANGITYIRMKGGRKSDDAISEFRGQNKKKAESIQVLLLLIQHGANGLNLLEAQH
VVLVEPLLNPAAEAQAIGRVHRIGQDKRTLVHRFIVKNTVEESIHQLNRSRNTKSFVSGKTKNQDQPVLTLKDVESLFASSSSTFKNGEEEPNGNSSSSL
RQLPPGVAAAMAAERRLLENGISTSSVLSSSPAPNLKFLRICDFSYDYYARDSQKFTQEEFNEITSNLPSLESLSIADKRFASGKCWLRISNPPYKLREF
SLISSMTPNLAVVEHLILETSHETNMWRDSQFSQEGHVLHGCVSMCPPKLMSAFQIRQIQLQNGMHFPEEEKKPAAESEVEKKTEDEEKKPEEEKKTDEK
PAGEEKKQEEAPPPPPPPTPTPTPPQEIVLKVFMHCEGCARKVRRCLKGFEGVEEVTTDCKSNKVVVKGEKADPIKVLERIQRKSHRQVELISPVPKPPE
VEADEKPKPPAEEPKPEQPPPVVITVVLQVYMHCEACAMEIKKRIQRMKGMLLSFINCFPLRFSSPPDFFFLTTDFKIDLGVESAEPELKSSQVTVKGVF
EAEQLVEYVRKRTGKQAVIVKQEPEKKEEKAGEDKEGKEDSSKEEEKKKGDESPSDDNAKKEEVDKGKPAEEGDKQKKEEGDAKETEAPAAAGEETTTKV
VEVKRNECYYYPPRYAMELYAYPPQIFSDENPNACAVM
|
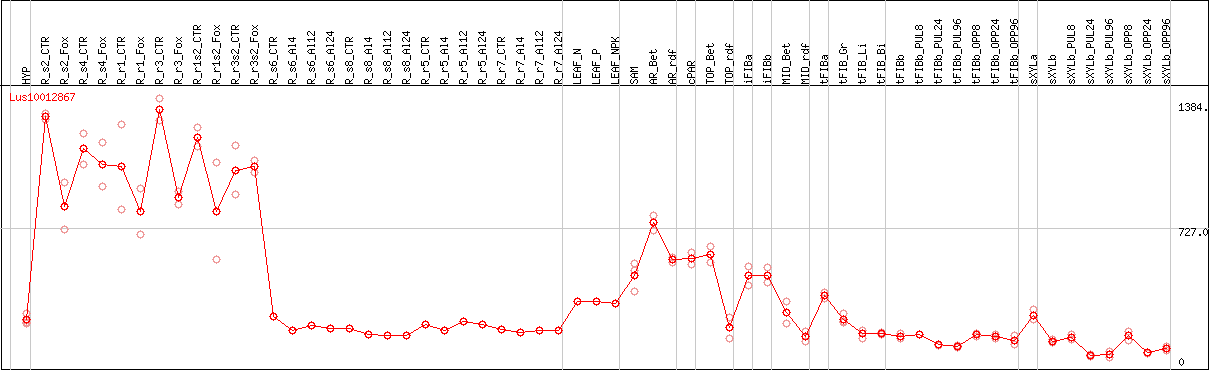
DESeq2's median of ratios [FLAX]
Coexpressed genes
Lus10012867 coexpression network
*The number of genes in the network is adjusted within 50 genes.*Gene name represents symbol(s) of closest Arabidopsis gene if symbol(s) for the gene itself doesn't exist.
*Circle diameter represents the number of connection with other genes within this network.
*Color for gene name represents subnetwork based on the result of network clustering.