Lus10014384 [FLAX]

| External link |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Symbol | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Arabidopsis homologues
|
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Paralogs
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Poplar homologues |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
| PFAM info |
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Representative CDS sequence |
>Lus10014384 pacid=23143715 polypeptide=Lus10014384 locus=Lus10014384.g ID=Lus10014384.BGIv1.0 annot-version=v1.0
ATGGCGGCGTCATTGACGGGGGACGACCTCGTCGGGTCGACGAGCAGCAGGAGAAGCTTCGGCTCGACGAGCCACCGGAGCTGGATGGCGGCGGCTAGCT
TCCGCGACGTGTTCACCATGGCTCCGGCGACGGATGTTTTCAGCCGAGCCGGAGCGCTGGAGCAAGAGGACGACGAGGAGGAGCTCCGGTGGGCTGCAAT
CGAGCGTCTGCCTACGTTCGACCGGATGAGGAAAGGGATGCTGAAGACTGTGCTCGATAACGGATCAGTGGTTCAGAACGAGGTCGATGTGACCAAGCTG
GGAATGCAGGACCGGAAGCAGTTGATCGAGAGCATACTGAAGGTCGTTGAAGATGACAACGAGAAGTTCCTGAGAAGACTCAGAAATCGAACCGATCGAG
TAGGGATTGAGGTTCCGAAGATTGAAGTGAGATACGAGCATTTATCAGTTGACGGAGAGGTCTACGTCGGCAGCAGAGCTCTTCCCACGCTGGTCAACGC
CGCCATTAACACTGTCGAGAATATTCTGGGATTGATTCGGCTTGCACCGTCGAAGAAGAGGAAGATACAGATTCTTCAAGATGTTAGTGGAATCGTGAGG
CCGTCAAGGATGACGCTGCTTCTAGGTCCACCAGGTGCAGGAAAAACTACAATGCTGCGTGCAATAGCTGGGAAGCTTGATAGTGATCTCAAGTCGTCTG
GAAAGATCACTTACTGCGGCCACGAATTCAGTGAGTTTGTTCCGCAGAGAACGTGTGCGTACATCAGTCAGCACGATCTCCACCATGGCGAGTTGACTGT
AAGGGAAACATTCGACTTCTCAGGACGATGCTTGGGGGTTGGCACTAGATATGAAATGCTGGTGGAACTGTCAAGGCGGGAGAAAGAGGCTGGAATTAAG
CCTGATCCTGAGATCGACGCGGTCATGAAAGCCACTGCAGTTTCTGGCCAGAAGACTAGTTTGGTTACTGATTATGTTCTCAAGATCCTTGGATTGGACA
TATGCGCGGATATCCTCGTTGGGGATGATATGCGGAGAGGAATCTCTGGAGGACAGAAGAAGCGTGTAACTACTGGTATGAATTTATTGTTGACTTGCGA
AGCAGTTGATGATGGAACCATTTCTGAAGGTCTGCTGTCATTGTTTTCCTTAAATGCAGGAGAAATGTTGGGTGGACCGGCAAAGGTCCTTTTGATGGAT
GAAATATCAACTGGGTTGGACAGTTCCACGACTTATCAGATATGCAAGTTCATGAGACAGATGGTCCATATTATGGAAGTAACTATGATCATTTCCCTTC
TGCAACCGGCACCGGAGGCGTTTGACCTCTTTGACGATGTGATCTTACTTTCCGAGGGAAGGATTGTGTATCAAGGACCAAGGGACAAAGTTGTCGACTT
TTTCGAGTTCATGGGGTTCAAGTGCCCCGAGAGGAAAGGAGTTGCGGACTTCTTGCAAGAAGTGACTTCCAAGAAGGACCAAGAACAATACTGGTACAAG
AGGGACGAGCCTTACAGGTTCGTATCGGTACCCGACTTTGTGGAAGGCTTCCACGCTTACCATATTGGTCAACAACTCGGATCGGATCTCGGGGTTCCTT
ACGACAGGTCGAGGGTACACCCTGCTGCACTTGTGAAAAGCAAGTACGGGATTTCAAATTGGGAGCTCTTCAGGGCGTGCTTCTCGAGGGAGTGGCTTCT
GATGAAACGAAACAGCTTTGTGTACATATTCAAGATATGCCAGATAACAATTATGTCGATCTTCGCCTTCACTGTGTTCTTGAGATCAACGATGAAAGTT
GGGACTGTGAAGGATGGGAATAAGTTCTTGGGTGCAATGTTTTTCAGTCTGGTCAATTTGATGTTTAATGGGATGTCTGAACTTGCAATGACCGTCTTCA
GGCTTCCCGTCTTTTATAAACAAAGAGATTTCTTGTTCTATCCTGCTTGGGCTTTTGGACTGCCGATATGGATCCTTAGAATTCCGATATCGCTCATTGA
GTCCTGCATATGGATTGCTCTAACATACTACACAATAGGATTTGCTCCAGCTGCTAGCAGGTTTTTCAAACAGTTTCTGGCATATTTCGGCATACATCAG
ATGTCTCTCTCGCTTTTCCGCTTCATTGCTTCTGTTGGGAGGACACCAGTTATGTCAAACACACTGGGGACATTCGCATTGCTCATCTTTTTTGTTATGG
GAGGATTCGTTATTTCCAAAGATGACATCGATGATTGGATGATCTGGGGATACTATATTTCTCCTATGATGTACGCTCAAAATGCGATAGTCGTGAATGA
ATTTCTCGACGATAGATGGAATATGCCTAATCTGGACCCTCGAATTAACGTAACAACAGTTGGGAGAGCCGTGCTGAAATCCAGAGGCTTCTTTACTGAC
GACAGTTGGTATTGGATCTGCATTGCAGCACTCTTTGGGTTTTCGGTTCTGTTCAATGTTTGGTTTATTGCAGCATTGAGTTTCTTGAACCCAATTGGCG
ATGGAAAAGCTGTAATACAAGATGGAGATACAGACAAGAAAGAGGAAACAGAAGGTATTGATATGGTCATCAGAAGTTTATCAGCAAGTGGTGGTTCTGG
CACTGACTCAACAAAAAGAGGAATGGTTTTGCCCTTCCGGCCACTTTCACTAGCATTCAACCATGTGAACTACTCTGTGGATATGCCTGCTGAAATGAAG
TCTAAGGGAGTTGCAGAAGATCGACTCCAACTGTTACGTGATGTCAGTGGCGCTTTTCGGCCAGGAATACTAACTGCTTTGGTAGGTGTAAGTGGAGCAG
GGAAGACTACATTAATGGATGTGTTGGCTGGAAGGAAAACTGGTGGATACATAGAAGGAAGTGTCAATATTTCAGGCTATCCTAAAAACCAATCGACATT
CGCTCGTGTCAGTGGCTACTGCGAACAGAACGACATTCATTCCCCATATGTCACTGTGCACGAATCTCTCATGTACTCGGCCTGGCTCCGACTTCCTCAA
GATATCGATTCTAAAACAAGAAAGGCATTTATGGACTTGGTTGAGTTGAATCCACTAAGAGATGCCTTAGTTGGACTTCCAGGAGTAGATGGTCTTTCTA
CAGAGCAAAGGAAGAGGTTGACAATAGCTGTGGAGTTGGTTGCTAATCCTTCTATCATATTTATGGATGAACCGACATCTGGTCTCGATGCGAGAGCAGC
CGCCATTGTTATGCGTACTGTAAGGAACACTGTAGACACAGGGAGAACTGTTGTGTGTACAATTCACCAGCCGAGTATAGACATTTTCGAAGCTTTTGAT
GAGCTACTATTGATGAAAAGAGGAGGTCAAGTAATCTATGCTGGACCTCTTGGTCGCCAGTCTCATAAGCTCGTTGAGTATTTCGAGGCTGTCCCGGGAG
TTCCTAAGATCAAAGATGGATACAACCCAGCAACATGGATGCTTGAAGTCAGTTCACCTGCAATGGAAGTTCAGCTAGATGTGGACTTCGCGCAAATTTA
CGCAAATTCTACTCTTTATCAAGGGAAACAACAGGATTTGATGAACATTCTGGGAGCAATTTATGCTGCAGTGTTTTTCCTGGGAGCAACAAATGCTTCT
TCTGTGCAGCCAGTTGTTTCGGTCGAAAGAACAGTTTTCTATCGTGAAAGAGCGGCTGGAATGTACTCTGCATTGCCTTATGCATTCGCCCAGGTGTCCA
TAGAAGCAATCTACGTTGCATTCCAAACGTTAATTTACCACCTTCTTCTCTACTCCATGATTGGCTTCGAATGGAAAGTCGACAAATTCTTGCTATTCTA
CTACTACATCTACATGGCATTTGTCTACTTCACACTCTACGGCATGATGGTTGTGGCACTCACCCCCGGCCACCAAATCGCCGCCATTTGCATGTCCTTC
TTCTTATCCTTCTGGAACTTGTTCGCCGGCTTCCTCATTCCTCGAATCCAAATACCGCTATGGTGGAGATGGTACTACTGGTGCTCCCCTGTAGCTTGGA
CGCTATACGGGATGATTACAAGTCAAGTTGGGGACAAAGATAACCTAGTTGAGATACCTGGTGCTCCAAGTATGCCCATAAAGCAGTTCCTGGAGACTGG
AATGGGGTTTAAACACAGTTTCCTCCCTGCTGTTGCTGTTGCTCACTTGGCGTTTGTTTGTTTGTTTTTCTTTGTTTTTGCTTTTGGTATCAAGTACCTT
AACTTCCAAAGAAGATAG
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
AA sequence
|
>Lus10014384 pacid=23143715 polypeptide=Lus10014384 locus=Lus10014384.g ID=Lus10014384.BGIv1.0 annot-version=v1.0
MAASLTGDDLVGSTSSRRSFGSTSHRSWMAAASFRDVFTMAPATDVFSRAGALEQEDDEEELRWAAIERLPTFDRMRKGMLKTVLDNGSVVQNEVDVTKL
GMQDRKQLIESILKVVEDDNEKFLRRLRNRTDRVGIEVPKIEVRYEHLSVDGEVYVGSRALPTLVNAAINTVENILGLIRLAPSKKRKIQILQDVSGIVR
PSRMTLLLGPPGAGKTTMLRAIAGKLDSDLKSSGKITYCGHEFSEFVPQRTCAYISQHDLHHGELTVRETFDFSGRCLGVGTRYEMLVELSRREKEAGIK
PDPEIDAVMKATAVSGQKTSLVTDYVLKILGLDICADILVGDDMRRGISGGQKKRVTTGMNLLLTCEAVDDGTISEGLLSLFSLNAGEMLGGPAKVLLMD
EISTGLDSSTTYQICKFMRQMVHIMEVTMIISLLQPAPEAFDLFDDVILLSEGRIVYQGPRDKVVDFFEFMGFKCPERKGVADFLQEVTSKKDQEQYWYK
RDEPYRFVSVPDFVEGFHAYHIGQQLGSDLGVPYDRSRVHPAALVKSKYGISNWELFRACFSREWLLMKRNSFVYIFKICQITIMSIFAFTVFLRSTMKV
GTVKDGNKFLGAMFFSLVNLMFNGMSELAMTVFRLPVFYKQRDFLFYPAWAFGLPIWILRIPISLIESCIWIALTYYTIGFAPAASRFFKQFLAYFGIHQ
MSLSLFRFIASVGRTPVMSNTLGTFALLIFFVMGGFVISKDDIDDWMIWGYYISPMMYAQNAIVVNEFLDDRWNMPNLDPRINVTTVGRAVLKSRGFFTD
DSWYWICIAALFGFSVLFNVWFIAALSFLNPIGDGKAVIQDGDTDKKEETEGIDMVIRSLSASGGSGTDSTKRGMVLPFRPLSLAFNHVNYSVDMPAEMK
SKGVAEDRLQLLRDVSGAFRPGILTALVGVSGAGKTTLMDVLAGRKTGGYIEGSVNISGYPKNQSTFARVSGYCEQNDIHSPYVTVHESLMYSAWLRLPQ
DIDSKTRKAFMDLVELNPLRDALVGLPGVDGLSTEQRKRLTIAVELVANPSIIFMDEPTSGLDARAAAIVMRTVRNTVDTGRTVVCTIHQPSIDIFEAFD
ELLLMKRGGQVIYAGPLGRQSHKLVEYFEAVPGVPKIKDGYNPATWMLEVSSPAMEVQLDVDFAQIYANSTLYQGKQQDLMNILGAIYAAVFFLGATNAS
SVQPVVSVERTVFYRERAAGMYSALPYAFAQVSIEAIYVAFQTLIYHLLLYSMIGFEWKVDKFLLFYYYIYMAFVYFTLYGMMVVALTPGHQIAAICMSF
FLSFWNLFAGFLIPRIQIPLWWRWYYWCSPVAWTLYGMITSQVGDKDNLVEIPGAPSMPIKQFLETGMGFKHSFLPAVAVAHLAFVCLFFFVFAFGIKYL
NFQRR
|
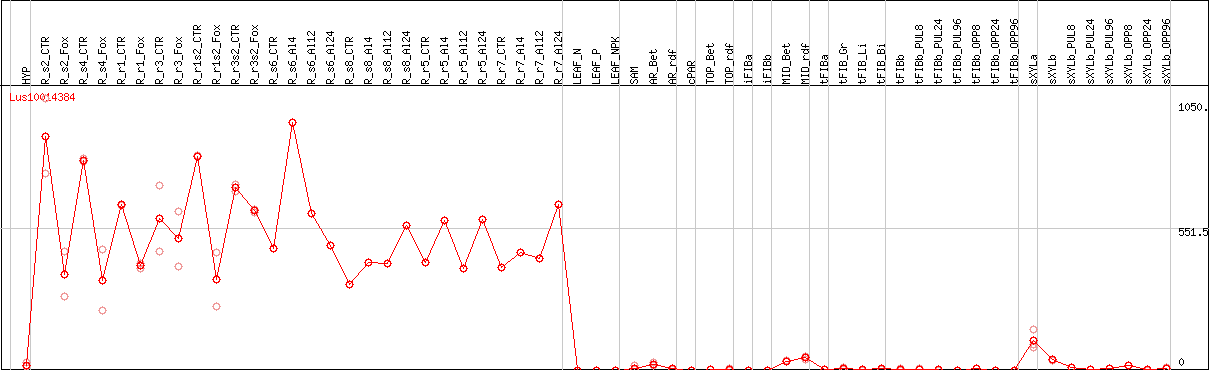
DESeq2's median of ratios [FLAX]
Coexpressed genes
Lus10014384 coexpression network
*The number of genes in the network is adjusted within 50 genes.*Gene name represents symbol(s) of closest Arabidopsis gene if symbol(s) for the gene itself doesn't exist.
*Circle diameter represents the number of connection with other genes within this network.
*Color for gene name represents subnetwork based on the result of network clustering.