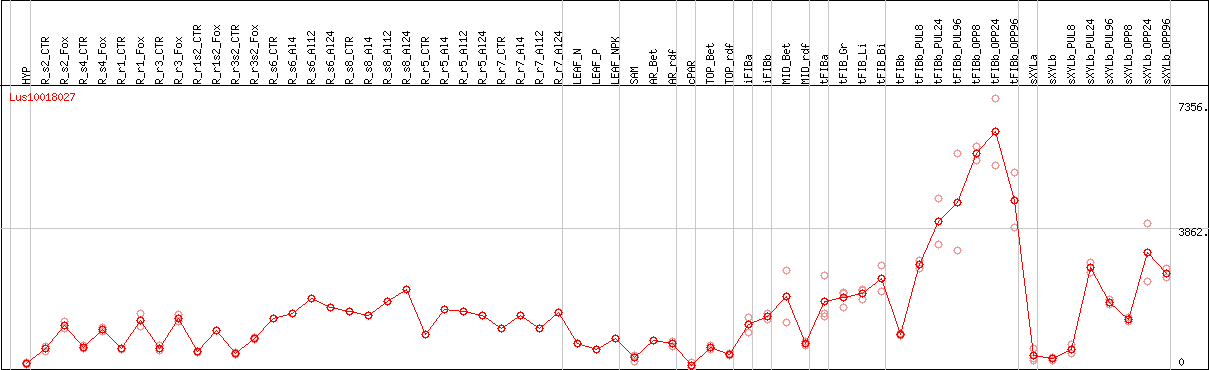
Lus10018027 [FLAX]

| External link |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Symbol | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Arabidopsis homologues
|
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Paralogs
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Poplar homologues |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
| PFAM info |
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Representative CDS sequence |
>Lus10018027 pacid=23147993 polypeptide=Lus10018027 locus=Lus10018027.g ID=Lus10018027.BGIv1.0 annot-version=v1.0
ATGGCCTGGCCGGAGCTCCCCTGTTTCCCTGAGCAGCTTGTCCTGTTTGTCCAGCTTGGTTTCGTCGGAGTCATAGTTTTCAGCTGCCTCACCAAAATAG
TCATCAGGGGAAAGAAGCAGCAAACATGTCCCGATGACGACGATAATAATAATGATATTGATGGAGAACCGCCGCCGCCGTTGCCGCCGGCGGCGACAAC
AACCAGTTGCAGCACGTGTTGCAAAGCAAGCGTGGCATGTTCCATTCTGCTGACGACAATTCACTGCCTCATCCTATTGACGACTCTGTTCCTCCCTTCT
TCTATCCCCCGCCGCCGTAGCCGCTGCAATTCCAGAGCTCTATCCCTCTCATCGGAGGCCAGCCAGCTGGCGTTATGGTTAGCCAGCCTAATAGCAATCT
ACCACATCATCAAGTCCAGAAAGCACGTGACTTTCCCTTGGATCGTAAGGTCATGGTGGATTTCCGGATTCCTCCTGTCGGCAATCCCCGTTTCCATCAG
AGCATATCTCAGATTTGTTGACACCGACGAAGACATCATCAATCTCGAATGGAATGACTACTCCGATCTCCTCGTCTTCCTCTCCTCCGCCTTCCTCTTC
TGCATTTCAGTCAACGGCAAGACTGGCACCAGTACCACTACCAGTACTGATTCATTACAGGAACCCCTCATTGCCAAAACAGCGACGTTACAAAAACGAT
CGCTGTATGGAAATGCAAGCATCCTACAGCTGGTCACCTTCTCTTGGATGAACCCGCTCTTCAGCGACGGATTCAAGAAGGCTCTCGATCAGGACGACAT
TCCTGATGTCGATGTCGGTGACTCTGCCTCGTTCCTATCCTCTGTTTTCACCAATTGCCTCCACAATGCAGCAACAGCTTCGTCCACGAGTCCTTCATTT
TACCACGCAATCTTTCTGCTGGTGAGAAAGAAAGCAGCGCTGAACGGTCTGTTCGCAGTGATCAGCGCCGGCGCGTCCTACGTGGGGCCCTACCTGATCA
ATGGCTTTGTTGACTTTTTAAGTAGAAGGAAAGAGTACAGCTTACGAACCGGCTACCTGATTGCATTAGCATTCCTAGTAGCCAAAACGGTGGAGACCGT
AACGCAGAGACAGTGGATATTCGGTGCTCGCCAGTTGGGACTCCGTCTCCGGTCAGCTTTGAACTCCCAAATCTACTCCAAGGGTCTCGTTCTCTCAGCT
CGGTCACGTCAGGGTCATACAAGCGGCGAGATTATAAACTACATGAGCGTTGATGTCAATAGGGTTACGGATTTCATATGGTACCTCAACACTATCTGGA
TGTTACCGATTCAAATCTCGCTAGCGATTCTCATCTTGAACACGAATCTAGGTGCATCAGGATCGGTGGCTGCTCTGGCTGCAACTATGATCGTTATGTC
GTGCAACATTCCTGTTACTCGTATCCAGAAATGGTACCAGGGTAAGATTATGGAGGCGAAGGACGGAAGGATGAAGGCTACTTCGGAAGTTCTACGTAAC
ATGAAGACCATAAAGCTTCAAGCTTGGGACTCGCAGTTTCTTTCGAAGCTGGAGGGGTTAAGAGAGGTTGAGCGTAGCTGGCTGTGGAAAAGTCTGAGGC
TTTCCGCTACTACGGCGTTCATCTTTTGGGGGTCTCCTGCTTTCATCTCGACCGTTACTTTCGGTGCCTGTTATGTGATGGGGGTGCAGCTTACGGCTGG
GAGAGTTCTATCTGCGTTGGCTACTTTTCGGATGTTGCAGGACCCGATATTCAACTTGCCTGATCTTTTGTCCACGATAGCGCAGGCAAAAGTTTCGGCC
GACAGGATCACTTCCTACATGCAGGAGGAAGAGATTCAGGAGGATGCTGTTACTCTCATTCCTCCAGAGGAGGAATCAGAGTGTGGTGTTGAAATTAAAG
GAGGGATTTTTACGTGGACTCCCGAATCGAAAAATAACATCACGCTAAGCGGGATCGATCTCAATGTGAAGAGAGGAATGAGAGTGGCGGTTTGCGGGAC
GGTGGGGTCTGGGAAATCGAGCCTGCTCTCTTGCATCCTGGGAGAGATACACAAGCTGTCAGGAAATGTCAGGATTCGAGGCACCAAGGCGTACGTAGCT
CAGTGTCCGTGGATACTGACGGGGAGCATTCGAGACAACATTTTGTTCGGGAAGGCTTATGATAGCGAGAAGTATCGGAGGACCGTGGAGGCTTGCGCTC
TGGTGAAAGATTTCGAGCTTTTCTCTTGCGGTGACATGACGGAGATTGGGGAGAGAGGGATCAATATGAGCGGAGGGCAAAAGCAGAGGATACAGATTGC
TCGTGCGGTTTATCAAGATGCTGACGTTTACTTGCTGGACGACCCTTTCAGCGCTGTGGATGCTCACACCGGATCTCACCTCTTTCAGGAGTGCCTAATG
GGAATATTGAAAAGCAAAACAATACTTTATGTTACCCACCAGGTTGAATTTCTTCCTGCAGCAGATCTCATTGTGGTAATGCAAAATGGAAAGATAGTGC
AAACCGGGAAGTTCGACCAACTTGTGGAGCAGAATGATGTAGGATTCGAAGCATTAGTTGGTGCCCACAGCCATGCTCTAGAGTCAGTTCTTGCAGTCGA
GAATTCGACAACGAGGATTCAACCTGTGGAGGAGGAAGAAGAAGAAGAGGAAAAGAAAGAAAATGCCCAACCAGAAGAATCAGATAATGCAGTAGGCCAT
CAGCAGGATCAGAGTGGGAAACTTGTGCAGGACGAGGAAAGAGAAAAAGGAAGCATTGGGAAACAAGTGTATTGGGCATATTTGACTTGTGTCAAAGGTG
GAGTCTTGGTTCCGATCATCATCTTGGCGCAATCGTCGTTTCAGGTGTTGCAGATTGCTAGTAACTACTGGATGGCTTGGGCTACTCCTCCCACAACCGA
CACCAGTAGTGTTCCAGTGGGGATGGGAACCGTTTTACTTGTTTATATGCTGTTGGCTGCTTCGAGTTCCCTCTGCGTGCTTCTCAGGGCGATGTTGGTT
GCAACGGTTGGCCTCTCAACAGCTGAGAAACTCTTCAGCAGTATGCTTCACAGTATCATTCGTGCTCCGATGCATTTCTTTGACTCAACTCCCACCGGCA
GAATTATGAACCGGGCGTCAACAGACCAAAGTGTGCTGGACTTGGAAATGGGACAGAGATTAGGTTGGTGCGCTTTCTCGATCATACAAATATTGGGGAC
GATTGCTGTTATGTCTCAGGTTGCTTGGGAAGTATTTGTAATCTTCATCCCAGTCACTGCAGTCTGTATATGGTACCAACAATACTACACACCAACAGCC
AGGGAATTGGCTCGGTTATCAGGAATACAATTAGCACCAATACTTCACCATTTCTCCGAGTCACTAGCCGGTGCAGCCACGATCCGCGCCTTTGGTGAAG
GGGAAAGGTTCATTGCTTCCAATCTTGGTCTTATAGACAACTACTCGAGGCCGTGGTTCCACAATGTATCGGCTATGGAATGGTTGTCTTTCAGACTGAA
TTTGCTCTCCAATTTCGTATTTGCTTTCTCTTTGGTTTTGCTCGTCTCGCTACCGGAAGGGATCATCAGCCCAAGCATTGCAGGACTAGCTGTGACATAC
GGCATAAATCTGAATGTTCTCCAGGCTTCGGTTATATGGAACATATGCAATGCTGAGAACAAGATGATCTCTGTAGAAAGAGTGTTACAGTACACAAAAA
TAAAAGGCGAAGCCCCCCTTGTGATTGAAGAGTGCAGACCGCCGGCTAATTGGCCTGAAACAGGAACAATTTGTTTCAAAGACTTGCAGATTCGATATGC
GGAGCATTTACCATCGGTGTTGAAGAACGTAAGCTGCACATTTCCAGGGAGAAGGAAAGTAGGGGTGGTTGGGAGGACAGGGAGCGGGAAGTCGACTTTA
ACACAGGCATTGTTTAGAATGGTACAAGTGCGAGAAGGAAGCATAATCATCGACGGGGTTGACATTTCAAAGATCGGACTCCATGACTTGAGATCCAGGC
TGAGCATCATCCCCCAGGATCCAACCATGTTTGAAGGCACAGTAAGAGGGAATCTTGACCCATTAGGCCACTATTCAGACTTCCAAGTTTGGGAGGCATT
GGAGAAATGCCAGCTTGGAAGCTTGGTGAGGGAGAAAGATGGGAAGCTGGATGCCACTGTGACGGAGAATGGAGAGAATTGGAGTGCAGGGCAAAGGCAA
TTGTTCTGCCTGGGAAGAGCTCTGTTGAAGAAGAGCAGTATTCTTGTGCTGGACGAAGCAACAGCTTCCGTGGATTCAGCAACGGACAGTGTCTTGCAGA
AGATCATCAGCCAAGAGTTTCAGGATCGGACGGTTGTGACGATAGCTCACAGGATCCATACGGTTATTGATAGCGATCTCGTGTTGGTGCTTAGTGATGG
AAGGATTGCTGAGTATGATAGCCCGAAAATGTTGCTGCAGAGAAAGGATTCCTTCTTCTCCAAACTGATAAAAGAATATTCTGCAAGATCGTCGAACCTG
AATTCTTCTGCTAGCTAG
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
AA sequence
|
>Lus10018027 pacid=23147993 polypeptide=Lus10018027 locus=Lus10018027.g ID=Lus10018027.BGIv1.0 annot-version=v1.0
MAWPELPCFPEQLVLFVQLGFVGVIVFSCLTKIVIRGKKQQTCPDDDDNNNDIDGEPPPPLPPAATTTSCSTCCKASVACSILLTTIHCLILLTTLFLPS
SIPRRRSRCNSRALSLSSEASQLALWLASLIAIYHIIKSRKHVTFPWIVRSWWISGFLLSAIPVSIRAYLRFVDTDEDIINLEWNDYSDLLVFLSSAFLF
CISVNGKTGTSTTTSTDSLQEPLIAKTATLQKRSLYGNASILQLVTFSWMNPLFSDGFKKALDQDDIPDVDVGDSASFLSSVFTNCLHNAATASSTSPSF
YHAIFLLVRKKAALNGLFAVISAGASYVGPYLINGFVDFLSRRKEYSLRTGYLIALAFLVAKTVETVTQRQWIFGARQLGLRLRSALNSQIYSKGLVLSA
RSRQGHTSGEIINYMSVDVNRVTDFIWYLNTIWMLPIQISLAILILNTNLGASGSVAALAATMIVMSCNIPVTRIQKWYQGKIMEAKDGRMKATSEVLRN
MKTIKLQAWDSQFLSKLEGLREVERSWLWKSLRLSATTAFIFWGSPAFISTVTFGACYVMGVQLTAGRVLSALATFRMLQDPIFNLPDLLSTIAQAKVSA
DRITSYMQEEEIQEDAVTLIPPEEESECGVEIKGGIFTWTPESKNNITLSGIDLNVKRGMRVAVCGTVGSGKSSLLSCILGEIHKLSGNVRIRGTKAYVA
QCPWILTGSIRDNILFGKAYDSEKYRRTVEACALVKDFELFSCGDMTEIGERGINMSGGQKQRIQIARAVYQDADVYLLDDPFSAVDAHTGSHLFQECLM
GILKSKTILYVTHQVEFLPAADLIVVMQNGKIVQTGKFDQLVEQNDVGFEALVGAHSHALESVLAVENSTTRIQPVEEEEEEEEKKENAQPEESDNAVGH
QQDQSGKLVQDEEREKGSIGKQVYWAYLTCVKGGVLVPIIILAQSSFQVLQIASNYWMAWATPPTTDTSSVPVGMGTVLLVYMLLAASSSLCVLLRAMLV
ATVGLSTAEKLFSSMLHSIIRAPMHFFDSTPTGRIMNRASTDQSVLDLEMGQRLGWCAFSIIQILGTIAVMSQVAWEVFVIFIPVTAVCIWYQQYYTPTA
RELARLSGIQLAPILHHFSESLAGAATIRAFGEGERFIASNLGLIDNYSRPWFHNVSAMEWLSFRLNLLSNFVFAFSLVLLVSLPEGIISPSIAGLAVTY
GINLNVLQASVIWNICNAENKMISVERVLQYTKIKGEAPLVIEECRPPANWPETGTICFKDLQIRYAEHLPSVLKNVSCTFPGRRKVGVVGRTGSGKSTL
TQALFRMVQVREGSIIIDGVDISKIGLHDLRSRLSIIPQDPTMFEGTVRGNLDPLGHYSDFQVWEALEKCQLGSLVREKDGKLDATVTENGENWSAGQRQ
LFCLGRALLKKSSILVLDEATASVDSATDSVLQKIISQEFQDRTVVTIAHRIHTVIDSDLVLVLSDGRIAEYDSPKMLLQRKDSFFSKLIKEYSARSSNL
NSSAS
|
DESeq2's median of ratios [FLAX]
Coexpressed genes
Lus10018027 coexpression network
*The number of genes in the network is adjusted within 50 genes.*Gene name represents symbol(s) of closest Arabidopsis gene if symbol(s) for the gene itself doesn't exist.
*Circle diameter represents the number of connection with other genes within this network.
*Color for gene name represents subnetwork based on the result of network clustering.