Lus10019453 [FLAX]

| External link |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Symbol | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Arabidopsis homologues
|
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Paralogs
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Poplar homologues |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
| PFAM info |
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Representative CDS sequence |
>Lus10019453 pacid=23181576 polypeptide=Lus10019453 locus=Lus10019453.g ID=Lus10019453.BGIv1.0 annot-version=v1.0
ATGTGGAGCTCGGCGGAGAACGTGTTTGGTCGCTCATCGTCGTTCCGGGACGCCGGGGAGGACGAGGAGGCCCTCCGCTGGGCGGCGCTGGAACGTCTGC
CGACTTATGCGCGGGTACGAAGAGGCATTTTCAGAAACGTCGTCGGGGATCACAGGGAGATTGATTTGAGCGAGCTCGTCGTCGAGGAGCAGAGGCTGGT
TATCGATCGGCTTGTTACTGCTGTGGATGATGATCCCGAGCTGTTCTTCGACCGGATGCGAAAGCGATTCGACGCGGTCGAGTTAGAATTCCCAAAAATT
GAGGTGCGGTTTCAGAATTTGAAGGTTGAATCATTTGTACATGTTGGAAGTAGGGCTCTTCCCACCATCCCCAACTTCCTTTTCAATATGAGCGAGGCAT
TGCTGAGGACGCTGGGAATCTATAGAGGAAACAGAACCAAGTTAACGATTCTAGACGATCTTAGTGGGATCATTAGGCCGTCAAGAATGACGCTTCTGGT
CGGACCTCCTAGCTCTGGCAAGACGACTCTGCTCTTGGCTCTAGCTGGCCGCCTTGGAAATGATTTGCAGATGTCTGGAAAAATTACGTACAATGGACAT
GGTCTGGCCGAGTTCGTTGCTCCAAGGACATCAGCTTATGTCAGTCAACACGACAGCCATATTGCAGAGATGACTGTCAGGGAAACGTTAGAATTAGCAG
GACGGTGTCAAGGTGTTGGTTCAAAATATGATATGCTTATGGAACTTGCAAGGAGAGAAAAGATGGCAGGGATAAAACCAGATGAAGATCTCGATATATT
CATGAAGTCGTTAGCTTTGGGGGGACAGGAAACAAACCTTGTGGTGGAGTATATCATGAAGGTATTCTGGTTGGATGTATGCGCGGACACCTTAGTTGGT
GATGAAATGATTAAGGGAATCTCCGGGGGTCAGAAGAAGCGGCTCACAACAGGAGAGCTACTTGTTGGCCCGGCAAGAGTACTTTTCATGGATGAAATCT
CGAATGGGCTAGACAGTGCGACCACCTATCAAATCATCAAGTACCTAAGGCATTCAACACATGCACTTGATGGAACTACCATGATTACCTTGCTGCAGCC
GGCTCCTGAGACATTTGAGCTTTTCGATGATGTCATACTTTTATCAGAAGGTCAGATTGTGTACCAGGGACCCCGTGAATCCGTCCTTGACTTTTTCTCA
TCTGTTGGATTTAGCTGTCCTGAAAGAAAGAATGTTGCCGACTTCTTGCAAGAAGTCACGTCGAAAAAGGATCAGCAGCAATACTGGTCTGATCCTTACC
GTCCCTACCGATATATTTCTCCTAGGAAGTTCGTTGAGGCTTTTCGTTCATTCCAAACGGGTAAACAATTGCAAAGAGAGCTAGAAGTTCCTTTCGATAA
ACGATACAATCATCCAGCGGCACTGTCGACTTCTCCATACGGGGTCAGGAAAAGTGAAGTTTTCAGGACATGCTATAACTGGCAGAGGCTTCTAATCAAA
AGGAACTCATTTATCTATGTATTTAAATTTATTCAGCTCTTTATCGTCGCTTTGATCACAATGAGTGTATTCTTCCGGACAACAATGCATCACAGTTCAG
TTTATGATGGAGGCTTGTACCTAGGATCTATATACTTCTCCATGGTCATTATCCTTTTCAATGGTTTTACGGAGGTGTCAATGCTCGTGGCCAAGCTGCC
CGTGCTTTACAAACACAGAGACCTGCATTTCTACCCGAGTTGGGCATACACAATTCCTTCTTGGGTCTTAAGTATTCCAACTTCTCTTATGGAGTCTGGT
CTTTGGGTTGCAGTTACATATTATGCGATTGGTTATGATCCCAACTTTACAAGATTTTTGCTCCAGTTTGTGCTGTATTTCTTTCTGCACCAAGTGTCTA
TAGCGCTATTCCGAGTTATGGGGTCACTGGGGCGCAACATGATCGTGGCCAACACCTTTGGTTCATTTGCTATGTTGGTTGTCATGGCCCTTGGAGGATA
CATCATCTCAAGAGATCATATACCGCGCTGGTGGATATGGGGATTCTGGGTTTCTCCTCTAATGTATGCGCAAAATGCTGCTTCAGTCAACGAGTTCCTT
GGCCACTCTTGGCATAAGAAATCTGGGAATAACAGCACCATTAACCTCGGGGAGAGTCTACTCAAAGCACGCAGTTTGTTTCCAGAAAGCTACTGGTACT
GGATTGGTCTTGGAGCTTTGCTTGGATATGCAGTTCTTTTCAACTCCCTGTTCACATTGTTTCTCTCCTACCTCAATCCATTAGGGATGCAACAGGCTGT
TGTCTCTAAAGAAGAGCTGCAAGAGAGAGAGAAGAGTAGGAAAAGTGGAGATGTCATTGTCGAACTAAGACATTACCTCGATAATTCAAACTCGTCAAAA
GGAAAATATTTCAAGCAGAAAGGCATGGTCCTTCCATTTCAACCTCTTTCAATGTGTTTCAGCAACATCAATTACTTCGTCGATGTACCACTGGAATTGA
AACAACAAGGGATAGCAGAAGATAGGTTGCAGCTATTGGTTAATGTTACTGGAGCATTTAGACCCAGTGTTCTCACCGCACTGGTCGGGGTCAGTGGTGC
TGGAAAGACCACCCTCATGGATGTCCTAGCTGGCAGGAAAACAGGAGGTGTCATAGAAGGGACCATAAACTTATCTGGTTTCCCGAAAAAGCAGGAAACT
TTCGCTCGAGTTTCTGGTTACTGTGAGCAAACTGATATCCATTCTCCTTGCATGACTGTTATTGAATCACTCCTTTTCTCTGCTTGGCTACGGTTATCAC
CCGAAATTAAACTCGAGACTCAACAGGCATTTGTTGAAGAGGTGATGGAACTTGTTGAGCTTACTACATTGAGTGGTGCATTAATTGGACTCCCGGGAGT
GCATGGTCTTTCAACAGAACAGAGGAAAAGGTTAACCATTGCTGTGGAGTTGGTAGCAAACCCATCTATAGTGTTCATGGATGAACCTACTTCTGGGTTG
GATGCGAGGGCTGCAGCCATTGTAATGAGGACAGTTAGGAATATTGTAAACACTGGTCGAACAATCGTGTGTACCATCCACCAGCCAAGCATAGACATCT
TCGAGTCCTTTGATGAGCTGTTGTTCATGAAGCGTGGAGGAGAAGTTATATATGCTGGACCACTTGGTACTAAATCTTGTGAACTGATCAAGTACTTTGA
GGGAATTGAAGGAGTGAAGAAGATAAGGCCAGATTACAACCCTGCAGCCTGGATGCTTGAAGTTACTTGTTCAGCTGAAGAAACCCGCCTGGACATCGAC
TTCGCAGAAATTTACAGGAAATCTCGACTGTACCAGCACAATAAAGAATTGGTTGAAAATCTAAGCAAACCACAGGCGGATACAAAAGAGTTGAACTTCC
CAACCAAGTACTCCCAGTCATTTTTCAACCAGTTTCTGGCGTGCCTTTGGAAACAGAACATGTCCTACTGGAGAAACCCACAATACACTGCAGTTCGCTT
CTTCTACACCATTGTCATCTCACTAATGCTCGGATCCATATGCTGGAAGTTCGGTTCCAAGAGGGAAACCGTTCAAGAGCTTTTCAACGCCATGGGATCC
ATGTATGCAGCAGTTCTCTTCATTGGAATCACCAATGCTACCGCAGTTCAACCTGTGGTCTCCATCGAGAGGTTCGTCTCGTATCGCGAAAGAGCTGCCG
GGATGTACTCAGCCTTGCCCTTTGCATTTGCTCAGGTTGTGATTGAGTTTCCTTACGTTTTTGGACAGACAATCATATACTGCTCGATATTCTACTCCAT
GGCTGCATTTGAGTGGACCGCTCTCAAGTTCATCTGGTACACATTCTTCATGTACTTCAGCATGCTCTACTTCACTTTCTACGGCATGATGACGACCGCC
CTGACTCCAAATCATAACGTTGCCGCCGTCATCTCCGCGCCCTTTTACATGCTCTGGAATCTCTTCAGCGGTTTCATGATCCCCCACAAGAGAATCCCAA
TTTGGTGGAGATGGTACTACTGGGCAAACCCGATAGCTTGGACGTTATACGGACTGTTGACATCCCAGTACGGAGACGACGGGAGGGCCATGAAGCTGCC
GGACGGGAATCAGATGGCGCCGGTGAAGATGGTGCTCCGGGAACTGCTTGGTTACAAACATGAATTCTTGGGAGTTGCAGGTGTAATGGTGGTTGGTTTC
TGTTTGATGTTCGCCGTCATTTTCGCTTTCGCAATCAAAGCCTTCAATTTCCAGAGGAGATAA
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
AA sequence
|
>Lus10019453 pacid=23181576 polypeptide=Lus10019453 locus=Lus10019453.g ID=Lus10019453.BGIv1.0 annot-version=v1.0
MWSSAENVFGRSSSFRDAGEDEEALRWAALERLPTYARVRRGIFRNVVGDHREIDLSELVVEEQRLVIDRLVTAVDDDPELFFDRMRKRFDAVELEFPKI
EVRFQNLKVESFVHVGSRALPTIPNFLFNMSEALLRTLGIYRGNRTKLTILDDLSGIIRPSRMTLLVGPPSSGKTTLLLALAGRLGNDLQMSGKITYNGH
GLAEFVAPRTSAYVSQHDSHIAEMTVRETLELAGRCQGVGSKYDMLMELARREKMAGIKPDEDLDIFMKSLALGGQETNLVVEYIMKVFWLDVCADTLVG
DEMIKGISGGQKKRLTTGELLVGPARVLFMDEISNGLDSATTYQIIKYLRHSTHALDGTTMITLLQPAPETFELFDDVILLSEGQIVYQGPRESVLDFFS
SVGFSCPERKNVADFLQEVTSKKDQQQYWSDPYRPYRYISPRKFVEAFRSFQTGKQLQRELEVPFDKRYNHPAALSTSPYGVRKSEVFRTCYNWQRLLIK
RNSFIYVFKFIQLFIVALITMSVFFRTTMHHSSVYDGGLYLGSIYFSMVIILFNGFTEVSMLVAKLPVLYKHRDLHFYPSWAYTIPSWVLSIPTSLMESG
LWVAVTYYAIGYDPNFTRFLLQFVLYFFLHQVSIALFRVMGSLGRNMIVANTFGSFAMLVVMALGGYIISRDHIPRWWIWGFWVSPLMYAQNAASVNEFL
GHSWHKKSGNNSTINLGESLLKARSLFPESYWYWIGLGALLGYAVLFNSLFTLFLSYLNPLGMQQAVVSKEELQEREKSRKSGDVIVELRHYLDNSNSSK
GKYFKQKGMVLPFQPLSMCFSNINYFVDVPLELKQQGIAEDRLQLLVNVTGAFRPSVLTALVGVSGAGKTTLMDVLAGRKTGGVIEGTINLSGFPKKQET
FARVSGYCEQTDIHSPCMTVIESLLFSAWLRLSPEIKLETQQAFVEEVMELVELTTLSGALIGLPGVHGLSTEQRKRLTIAVELVANPSIVFMDEPTSGL
DARAAAIVMRTVRNIVNTGRTIVCTIHQPSIDIFESFDELLFMKRGGEVIYAGPLGTKSCELIKYFEGIEGVKKIRPDYNPAAWMLEVTCSAEETRLDID
FAEIYRKSRLYQHNKELVENLSKPQADTKELNFPTKYSQSFFNQFLACLWKQNMSYWRNPQYTAVRFFYTIVISLMLGSICWKFGSKRETVQELFNAMGS
MYAAVLFIGITNATAVQPVVSIERFVSYRERAAGMYSALPFAFAQVVIEFPYVFGQTIIYCSIFYSMAAFEWTALKFIWYTFFMYFSMLYFTFYGMMTTA
LTPNHNVAAVISAPFYMLWNLFSGFMIPHKRIPIWWRWYYWANPIAWTLYGLLTSQYGDDGRAMKLPDGNQMAPVKMVLRELLGYKHEFLGVAGVMVVGF
CLMFAVIFAFAIKAFNFQRR
|
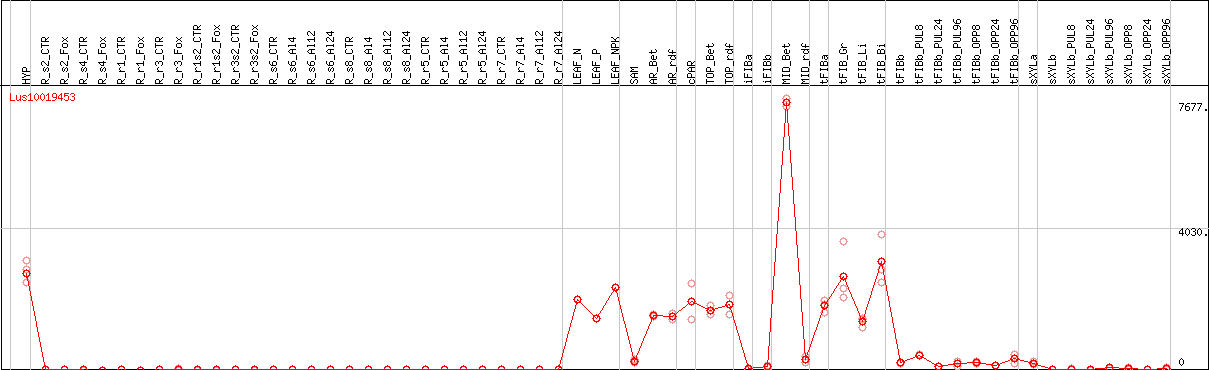
DESeq2's median of ratios [FLAX]
Coexpressed genes
Lus10019453 coexpression network
*The number of genes in the network is adjusted within 50 genes.*Gene name represents symbol(s) of closest Arabidopsis gene if symbol(s) for the gene itself doesn't exist.
*Circle diameter represents the number of connection with other genes within this network.
*Color for gene name represents subnetwork based on the result of network clustering.