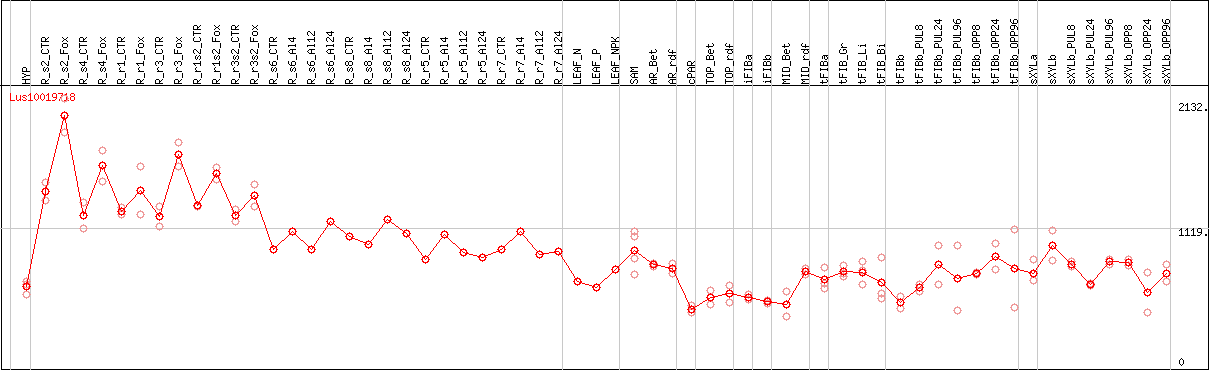
Lus10019718 [FLAX]

| External link |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Symbol | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Arabidopsis homologues
|
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Paralogs
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Poplar homologues |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
| PFAM info |
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Representative CDS sequence |
>Lus10019718 pacid=23139279 polypeptide=Lus10019718 locus=Lus10019718.g ID=Lus10019718.BGIv1.0 annot-version=v1.0
ATGAAGAGGCTGAGATCGAGTGATGATCTTGATTCCTACAGTGAGAAGAGCTCCTCCCTCAAGGATTTGGGCGCAAATCGATCCAATTCGCGGAGCTTTT
ACCACAAATCCGATGGTGTAAGGAAGGGTGGTATAGTGTCAGCTTCATCTCCCTCCAGCAGGTATGATCGGGATAGATCTATTGACGATGATTCCCGAGA
CAGTCCGAGGTTTGTTCGGAAGCGAAGTGATTACGATTTGGATAGCTTTGATAGAAGGAAAGGAATGGGATCTTCTTCTGGGTTTGATCGGTATGGAGGT
AGTAGAGAAGGGTACAGTGGTGGTGGAGTTGGCAGCAATGGTGGTGGGATTAGTGCTGATAGAGCTGTTCATCGATCCGAGAGCTTCTCCGGTTCGAGGA
GGGAGTTTCCGAAGGGATTTAGGTCGGAGAGGGATCGGTCCAGAAGGGAAGGGAGTGTGTCCTCCTGGAGGAGGTTTGGCAGTGGGAGCAAGGATTTTGA
GGAAGGGAGAGGGAGCAGAAGTGGGAATGAGGATAAAATGGCGGTAACTAGGATTTCTCCTAAAGGTTTGAAGGAGGTAAAGTCGCCGACTTGGTCAAGG
GACTCGAGCAGTGAGCAGTCGAAAATGTTTAGGGGCAGTGATAGGGATGAAGGTAAGGGAAAGTCTTGGACTTCCAAGTCGAGGTCATCGCCATCTTGGT
CGAAAGAGTCTGGTAGCGAGCAACAATCAAAGAGTGTGGAGGTCGGGAAGAGGAATGTTGATGTCGAGGTGAAAAGTGTTGAAATTGAAGCGACGAAAAG
TATTGAAGTGGAAGCAACGAGAAGTATTGAAGTGGAAACGCGTAGTGCTGAGGTGGAGACGAGAAGTGTTGAAATGGAGGTGAAGAGTGTCCAGAGTGGC
AGCAGTAGTGAGATGGAGGAAGGTGAGCTCGAGCCGGAGCCTGACTTGAAGCAAGAGGTTGACAAGGAGAATGAGAATGAATCCCTAAAAGGAGTGAAGA
TTGACACTGAAGTGAAGGAACTAGAGAACGAAGTCACAAAAATCGAGATAAAGGATATTGACAAGGCAGTTGAGCTGTCAAACTGTGAGGAAATCTTGAA
TAAGGAACCTGGCATCGATGTTGATGGGATCAGAAATCGGGGTTATCAAGTAACTGAAGAGGTCAAGAACTCAGAGGAACTCAGTAGTGGTCAAGCTAAG
GCGGTTGAGAAGGCGAAGGACGCAGTTGACAAGAATGTGCTCGAGAATCGGTTTGATCTAGAAGCTAAAGTTGACCAAGCTGATATCGAGAGATCGAAAA
ATGAAGTTGTGCAAGACAATGAAGAAGCTCCGCTGAACTCGAATATTGTTACTCAGAATTTGGCTCAAAACATGAAGGATAAAGGTAAGAGTGTGATTGT
TTCACCCGCTCGTGTTGTTGCCGATGATGTTCTTTCATCCAGGGACAGAGAAGTTGATATGGAGGGACCAAGTAACCGGGGATTCGAGCTTTTCGGTAAC
TCCCCCGTGAGGAAAGTAGAGAAAGAGGAGCAATCTGGTGGTGGTAACAACAAACAGAAAGATGAAAGGCGAGTTTTAGAGCCACTTGATCTCTCTCTGA
GCTTACCCAATGTGTTGTTACCTATCGGTGCTACGAAAGATACAACTCAAGCCCCCCGGGGTGCTCAGAGTGATGCAAGAAGTCTTCATTCTTTCAGCTC
ATTCCGAACAAACTCCGATGGATTCACTGCTTCCATGTCTTGCTCAGGCTCACAGTCGTTTTTCCACAACCCGAGCTGTTCGCTAACTCATAACTCGTTG
GATCTCGACAATATCGAACAATCTGTTCACAGCCGCCCCCTATTCCAGGGGATTGATTGGCAGGCTCAGGCTCAGAATCAAAACGATTCGAATTCAAAGC
ACAAGGATACTCCGTCCTTGTACCAGAAAATCTTGATGAATGGAAATGGGTCACTTCATCAGGGCATATCAAATGGTCAACCAGTTCATGGAAGCTCGAA
AACATCGAACGGTCTCGAAAGACAAATGAGTTTGCATAAGCAATCTTCTACTTCGCAGAGCATTGGTTCTCAAGATATGGTTCCGAGTAGCTATAGCTTC
GACAAGAAGCGAGCAGCGAGGGAGAAGCATAATAGCAGTAGCCTGTACAGGAGTAACAGTCAGAAAGAGGAACGATTTTCAATAGGTGGAGCCGATTTCG
TCGAGACTGTAATCAGCAGAATAGTCTCTGATCCAATCCACGTCATGGCTCGAAAGTTTCACGAGATGACAGCACAGTCCGCATCTTGTTTGAAGGAGAG
CATCCGAGAGATAATGCTGAACGCTGATCGGCAAGGCCAGTTGTGTGCTTTTCAAACTGCTCTCCATAACCGGTCCGATTTAACATTGGACACCATTCTA
AAGTCTCACAGGGCACAGCTCGAAATACTCGTGGCTCTGAAATCCGGACTGGTGGAATATCTTAAAGTGGACACCAGCGTCTCCTCCTCTGACCTGGCAG
AGGTTTTCTTGAATTTGAAATGTCGAAATCTCGCTTGTCGGAGTCCTTTACCTGTAGACAACTGTGACTGCAAGGTTTGCACGAAAAAGACCGGTTTTTG
CAGCACTTGTATGTGTCTGGTGTGCTCGAAATTCGACATGGCATCGAATACTTGTAGCTGGGTGGGTTGTGATGTCTGTCTTCATTGGTGTCACGCCGAT
TGCGCTTTACGAGAAGCTTACATAAGAAATGGGAGGAGTCCGACCGATGTCAACCAAGGGAGTACAGAGATGCAGTTCCATTGTGTGGCTTGTGATCATC
CTTCTGAGATGTTTGGTTTCGTTAAGGAAGTGTTTCAGAACTTTGCGAAAGAATGGACGGCAGAGACGTTGTGCAAAGAGCTCGAGTATGTCAAGAGGAT
TTTCGGGGGCAGTAAAGATGCAAGGGGGAGGCGGCTTCATGAGATTGCGGATCAGATGCTCGCGAAAATGGCTAATAAGTCGAATTTTCGACAGGTTTAT
AGTCACATCATGGGGTTCCTCACTGACAGTGATTCTTCGAAGTTCGCAAATGCTACTGCTGCTTACAGCGGCAAGGAACAATTGAAAGGCGGTATTTCTA
GCAGCGTACCGGGCCCTAGTCAGGACGGAAATTGGCGGAAGTTAGTCAGTTCCGAGAAGGGACCTAAACTGGAGAGATCATCCAGTTTGCTTCCTACATT
TCCACCCGATCTGAACGACAAACGTCCAGTTGATACCGAGTTGCTCCCAAGAAGCAGCAGCCTGAAAGAACCGGTTTTCGACGAACTCGAAGGCATCGTG
AGGATCAAACAAGCGGAAGCTCAAATGTTCCAAACCCGTGCTGATGACGCTAGAAGAGACGCAGAAGGTACTGCTGCTTACTGCGGCAAGGAACAATTGA
AAGGCGGTATTTCTAGCAGCGTACCGGGCCCTAGTCAGGACGGAAATTGGCGGAAGTTAGTCAGTTCCGAGAAGGGACCTAAACTGGAGAGATCATCCAG
TTTGCTTCCTACATTTCCACCCGATTTGAACGATAAACGTCCAGTCGACACCGAGTTGCTACCGAGAAGCAGCAGCCTGAAAGAACCGGTTTTCGACGAA
CTCGAAGGCATCGTGAGGATCAAACAAGCGGAAGCTCAAATGTTCCAAACCCGTGCTGATGACGCTAGAAGAGACGCAGAAGGGCTGAAACGAATCGCGA
TTGCCAAGAACGAAAAGATCGAAGAGGAGTATGCAAGCAGGATAGCCAAGCTGCGGTTATCAGAGACCGAAGAGCTTCGGAAACAGAAGCTGCAAGAGTT
CCAGGCGCTGGAGAGAGCTCACCGGGAGTATTTCGGGATGAAGATGAGGATGGAAGCGGATATCAAGGATCTGTTGCTGAAAATGGAAGCGACGAAACGG
AATCTCGCCATTTGA
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
AA sequence
|
>Lus10019718 pacid=23139279 polypeptide=Lus10019718 locus=Lus10019718.g ID=Lus10019718.BGIv1.0 annot-version=v1.0
MKRLRSSDDLDSYSEKSSSLKDLGANRSNSRSFYHKSDGVRKGGIVSASSPSSRYDRDRSIDDDSRDSPRFVRKRSDYDLDSFDRRKGMGSSSGFDRYGG
SREGYSGGGVGSNGGGISADRAVHRSESFSGSRREFPKGFRSERDRSRREGSVSSWRRFGSGSKDFEEGRGSRSGNEDKMAVTRISPKGLKEVKSPTWSR
DSSSEQSKMFRGSDRDEGKGKSWTSKSRSSPSWSKESGSEQQSKSVEVGKRNVDVEVKSVEIEATKSIEVEATRSIEVETRSAEVETRSVEMEVKSVQSG
SSSEMEEGELEPEPDLKQEVDKENENESLKGVKIDTEVKELENEVTKIEIKDIDKAVELSNCEEILNKEPGIDVDGIRNRGYQVTEEVKNSEELSSGQAK
AVEKAKDAVDKNVLENRFDLEAKVDQADIERSKNEVVQDNEEAPLNSNIVTQNLAQNMKDKGKSVIVSPARVVADDVLSSRDREVDMEGPSNRGFELFGN
SPVRKVEKEEQSGGGNNKQKDERRVLEPLDLSLSLPNVLLPIGATKDTTQAPRGAQSDARSLHSFSSFRTNSDGFTASMSCSGSQSFFHNPSCSLTHNSL
DLDNIEQSVHSRPLFQGIDWQAQAQNQNDSNSKHKDTPSLYQKILMNGNGSLHQGISNGQPVHGSSKTSNGLERQMSLHKQSSTSQSIGSQDMVPSSYSF
DKKRAAREKHNSSSLYRSNSQKEERFSIGGADFVETVISRIVSDPIHVMARKFHEMTAQSASCLKESIREIMLNADRQGQLCAFQTALHNRSDLTLDTIL
KSHRAQLEILVALKSGLVEYLKVDTSVSSSDLAEVFLNLKCRNLACRSPLPVDNCDCKVCTKKTGFCSTCMCLVCSKFDMASNTCSWVGCDVCLHWCHAD
CALREAYIRNGRSPTDVNQGSTEMQFHCVACDHPSEMFGFVKEVFQNFAKEWTAETLCKELEYVKRIFGGSKDARGRRLHEIADQMLAKMANKSNFRQVY
SHIMGFLTDSDSSKFANATAAYSGKEQLKGGISSSVPGPSQDGNWRKLVSSEKGPKLERSSSLLPTFPPDLNDKRPVDTELLPRSSSLKEPVFDELEGIV
RIKQAEAQMFQTRADDARRDAEGTAAYCGKEQLKGGISSSVPGPSQDGNWRKLVSSEKGPKLERSSSLLPTFPPDLNDKRPVDTELLPRSSSLKEPVFDE
LEGIVRIKQAEAQMFQTRADDARRDAEGLKRIAIAKNEKIEEEYASRIAKLRLSETEELRKQKLQEFQALERAHREYFGMKMRMEADIKDLLLKMEATKR
NLAI
|
DESeq2's median of ratios [FLAX]
Coexpressed genes
Lus10019718 coexpression network
*The number of genes in the network is adjusted within 50 genes.*Gene name represents symbol(s) of closest Arabidopsis gene if symbol(s) for the gene itself doesn't exist.
*Circle diameter represents the number of connection with other genes within this network.
*Color for gene name represents subnetwork based on the result of network clustering.