Lus10021448 [FLAX]

| External link |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Symbol | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Arabidopsis homologues
|
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Paralogs
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Poplar homologues |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
| PFAM info |
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Representative CDS sequence |
>Lus10021448 pacid=23179251 polypeptide=Lus10021448 locus=Lus10021448.g ID=Lus10021448.BGIv1.0 annot-version=v1.0
ATGACCAACGAAGAGGATCCTCGCCGACGTCGGAAGCGTTCTCGTTCCGTTTCATCGTTACCGGCATTTTCATTGCTGCTACTGGTGGTGGTGGTGGTGT
CATTTTCGCCGTCACCGGTCTCCTGCCAAAGATCCGCCGGCGGCGGTAGCGGTGGCGTTTCCAATTCCGGAGATATTCCTTCCTCCGCCACCGCTGCCGC
AGCAGCAGGTGGAATGGGAAAAAATGACGCGAGGGATCAATTGGTGTCGCAGATGCTCTACAAGAAATTCGCCAATTTCACCGATATCTTCAAGGCCGAC
ATCAAGAAGCATTTTGGCTTCTGCATCACCGACGTGGATGCAGATTGGAATGCGGCGTTCAATTTCTCCAAGAACACCAAATTCATAGCCAATTGCGCTA
AGGCTACTAAAGGGGACATGAACCAGCGCATATGCACAGCAGCAGAGGTGAAGTTCTACTTCAACAGTTTCTTCCAGAAGGGCTCGAAAAAATCGAACTA
TCTGCACCCGAACAAGAACTGTAACTTGACCTCGTGGGTCTCCGGGTGCGAGCCCGGGTGGGCTTGTAGCGTCAACAAAGGAACCAAGGCCGATCTCAAG
AACTCAAAGGAAATGCCTCTCAGAACTTCCAACTGTGATGCTTGCTGTGAAGGCTTCTTCTGCCCTCATGGCCTTACTTGCATGATACCATGCCCATTGG
GGAGTTACTGCCCACTGTCAAAGCTCAACAAGACTACAGGCATGTGTGACCCATACCATTACCAACTTCCAGCAGGGAAGCCTGACCATACCTGTGGAGG
AGCCGATATCTGGGCCGATATCGTGAGGTGTTTCAAGTTAGCAACATGTGTACCTCAATCTGCAAACCAGAATATATCAGCTTATGGACTCTTGCTTTTT
GCTGGACTAGGGTTCCTACTCATAATCATCTACAACTGCTCCGATCAAGTCATCGCAACTCGCGAGAAAAGACAAGCGAAAACCAGAGAGAAAGCGGTAC
AAAGCGTAAAGGAGACTCAAGCGCGCGAGAAATGGAAGTCGGCCAAGGAGACAGCAAAGAAGACCGCCATGGATTTCCAAACCCAATTCTCGAGAACGTT
CTCCCGCGTAAAATCGAAACGGGAAGACACAAGCTCGGGGACAAAGGGCAAGAAGAAAGACAAGGCAAACCTCACGAAGATGCTCCAAGAGATCGAGAAC
AACCCGGATGGCCACCAGGGGTTCAACGTCGAGATCGGAGATAAAAACATCAAGAAACATGCCCCCAAGGGTAGGCAGCTGCACACTCAGAGCCAGATGT
TCCGGTATGCTTACGGACAGATCGAGAAGGAGAAGGCGATGCAGGAGCAAAACAAGAACCTGACATTCTCCGGGGTTATATCGATGGCTAGCGATGTCGA
GATGCGGAAGAGGCTTACTATTGAGGTTTATTTTAAGGATCTAACCCTAACTTTAAAAGGTAAGAACAAGCGTTTGTTGAGATGTGTTACTGGCAAGCTT
TCACCGGGCCGAGTTTCGGCTGTTATGGGGCCATCTGGTGCTGGCAAAACTACCTTCCTCTCTGCCTTGACTGGCAAAGCACCTGGATGTAGTGTGTCCG
GTATGGTTCTGGTCAACGGTAAAGCGGAACCGATCCAAGCGTACAAGAAGATCATCGGTTTCGTGCCTCAGGACGATATCGTCCATGGTAACTTGACCGT
TGAAGAGAATCTTTGGTTCAATGCAAGCTGCAGGCTGTCTGCTGATCTACCAAAACCGGACAAGGTTCTAGTGGTCGAACGAGTGATAGAGTCCTTAGGC
CTCCAACCGGTGAGGGACTCGCTCGTGGGGACTGTCGAGAAACGAGGGATTTCGGGTGGTCAACGGAAACGAGTGAACGTGGGAATGGAGATGGTGATGG
AACCTTCACTTCTTATCCTAGATGAGCCAACATCCGGCTTGGACAGCTCGTCGTCCCAGCTACTGCTTAAGGCTCTTCGGCGCGAAGCTCTCGAAGGGGT
GAACATTTGCATGGTTGTCCATCAACCAAGCTACACGCTATTCAGGATGTTCGACGACTTGATCCTTCTTGCGAAAGGTGGCTTGACAGCGTACCATGGG
CCGGTAAAGAAAGTAGAAGAGTACTTTGCAGGACTCGGAATCACTGTTCCAGATCGAGTTAACCCACCGGATTACTTCATCGACATCCTCGAAGGTATAC
TCAAACCTGCCTCAGGGGTACACTACAAGCAACTTCCGGTTCGATGGATGCTTCACAATGGATACCCGGTCCCCATGGACATGCTCCAGAGCACAGAAGG
ACTCGGAGGGCCTGCAGGAGAAGGCTCTGGCCATGGAGAAGCAGGAAGGCTCAGCGAGGTGGGGTCGGAGGCTCAGTCGTTTGCTGGAGAGTTCTGGCAG
GATATGAAGTCCAATGTTGAGATCAACAAGGATAACGTGCAACATAATTTCTTGCATACGGTCGATTTATCCGGTAGAGTGACTCCCGGGATCTTTCAGC
AGTATAGATACTTCCTTGGCAGGGTCGGTAAGCAGAGATTACGAGAAGCAAGGACGCAAGCAGTAGACTATCTGATCTTATTGCTCGCCGGTATCTGCTT
AGGAACGCTAGCAAAAGTGAGCGACGAGACTTTTGGAGCGCTTGGTTACACATATACCGTCATTGCAGTTTCTCTATTGTGCAAGATTTCGGCTTTGAGA
TCATTTTCACTGGACAAGTTACACTACTGGAGAGAAAGAGGCTCCGGCATGAGTTGCTTGGCTTACTTCCTTGCGAAGGACACGATCGATCATTTCAACA
CCATCATCAAGCCTATTGTCTACCTCTCCATGTTCTACTTCTTCAACAATCCGAGATCTAGCATCTACGACAACTACATCGTCTTGGTGTCCCTCGTTTA
CTGCGTCACTGGCTTAGCCTATATCCTAGCTATTGCCTTCGAAGCCGGTCCAGCTCAATTGTGGTCAGTACTGCTTCCGGTCGTATTGACCCTGATTGCA
ACCCGGAACGATGGTGGCTTGGCCGGTCGCCTCTCCGACGTATGCTACACCAAATGGGCGTTGGAAGCCTTTGTTATATCTAATGCCAAGAGATACAACG
GAGTGTGGCTGATAACACGATGCGGTTCACTCATGGAAAACGGGTACGATCTCAACCATTGGAACCGTTGCCTAATCCTTCTCGGCCTAACCGGTTTCGC
TAGTCGGGTCGTTGCCTTCATCGTCCTTGTTACCTGGCAGAAGAGGTGA
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
AA sequence
|
>Lus10021448 pacid=23179251 polypeptide=Lus10021448 locus=Lus10021448.g ID=Lus10021448.BGIv1.0 annot-version=v1.0
MTNEEDPRRRRKRSRSVSSLPAFSLLLLVVVVVSFSPSPVSCQRSAGGGSGGVSNSGDIPSSATAAAAAGGMGKNDARDQLVSQMLYKKFANFTDIFKAD
IKKHFGFCITDVDADWNAAFNFSKNTKFIANCAKATKGDMNQRICTAAEVKFYFNSFFQKGSKKSNYLHPNKNCNLTSWVSGCEPGWACSVNKGTKADLK
NSKEMPLRTSNCDACCEGFFCPHGLTCMIPCPLGSYCPLSKLNKTTGMCDPYHYQLPAGKPDHTCGGADIWADIVRCFKLATCVPQSANQNISAYGLLLF
AGLGFLLIIIYNCSDQVIATREKRQAKTREKAVQSVKETQAREKWKSAKETAKKTAMDFQTQFSRTFSRVKSKREDTSSGTKGKKKDKANLTKMLQEIEN
NPDGHQGFNVEIGDKNIKKHAPKGRQLHTQSQMFRYAYGQIEKEKAMQEQNKNLTFSGVISMASDVEMRKRLTIEVYFKDLTLTLKGKNKRLLRCVTGKL
SPGRVSAVMGPSGAGKTTFLSALTGKAPGCSVSGMVLVNGKAEPIQAYKKIIGFVPQDDIVHGNLTVEENLWFNASCRLSADLPKPDKVLVVERVIESLG
LQPVRDSLVGTVEKRGISGGQRKRVNVGMEMVMEPSLLILDEPTSGLDSSSSQLLLKALRREALEGVNICMVVHQPSYTLFRMFDDLILLAKGGLTAYHG
PVKKVEEYFAGLGITVPDRVNPPDYFIDILEGILKPASGVHYKQLPVRWMLHNGYPVPMDMLQSTEGLGGPAGEGSGHGEAGRLSEVGSEAQSFAGEFWQ
DMKSNVEINKDNVQHNFLHTVDLSGRVTPGIFQQYRYFLGRVGKQRLREARTQAVDYLILLLAGICLGTLAKVSDETFGALGYTYTVIAVSLLCKISALR
SFSLDKLHYWRERGSGMSCLAYFLAKDTIDHFNTIIKPIVYLSMFYFFNNPRSSIYDNYIVLVSLVYCVTGLAYILAIAFEAGPAQLWSVLLPVVLTLIA
TRNDGGLAGRLSDVCYTKWALEAFVISNAKRYNGVWLITRCGSLMENGYDLNHWNRCLILLGLTGFASRVVAFIVLVTWQKR
|
DESeq2's median of ratios [FLAX]
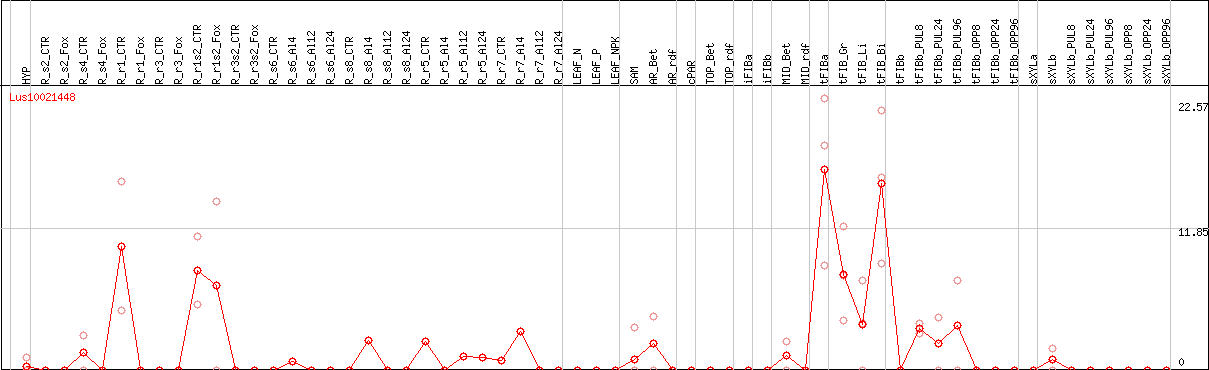
Coexpressed genes
Lus10021448 coexpression network
*The number of genes in the network is adjusted within 50 genes.*Gene name represents symbol(s) of closest Arabidopsis gene if symbol(s) for the gene itself doesn't exist.
*Circle diameter represents the number of connection with other genes within this network.
*Color for gene name represents subnetwork based on the result of network clustering.