Lus10022238 [FLAX]

| External link |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Symbol | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Arabidopsis homologues
|
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Paralogs
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Poplar homologues |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
| PFAM info |
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Representative CDS sequence |
>Lus10022238 pacid=23139497 polypeptide=Lus10022238 locus=Lus10022238.g ID=Lus10022238.BGIv1.0 annot-version=v1.0
ATGGGGAGGAGGAGGAAGTTGTTGCGGTTTAGCAAGTTGTATTCTTTTTCATGTTTCAAAGCATCTTTTGAGGATGATCATGCTCAAATTGGGAGGAAAG
GTTACTCCAGGGTAGTGTATTGCAATGACCCTGACAGTCCAGAATCAGTTGAGCTTAATTACAAAGGCAATTACGTCTCCACCACCAAATACACGGCCGC
TAACTTTATTCCCAAGTCTCTCTTTGAGCAGTTCAGGCGGGTTGCCAACATTTATTTTCTTGTTGTAGCTTGTGTCTCTTTTAGTCCATTGGCACCTTAT
AACGCTAAAAGTATTCTTGCACCTCTGGTTGTGGTCATTGGAGCTACCATGGTGAAAGAAGCTGTCGAAGATTGGAGGAGGAGAAAACAGGATGTAGAAG
CTAATAATAGAAAGGTGAAAGTGTTGGGTAAGAATTCCAAATTCACACAGACTAGATGGAAGCATCTCCGAGTTGGAGATATTGTTGAAGTGGATAAGGA
TCAGTATTTCCCTGCTGATCTTCTTCTGCTCTCTTCGAGCTATGATGATGGAGTTTGCTACGTCGAGACGATGAATTTGGATGGAGAGACTAACTTAAAG
TTGAAGCATGCTCTGGAGGTCACTTCCTCGCTGCACGATGAAGGAGGTTTAAAGGAATTCAAGGCTGTGATCAAGTGTGAGGACCCAAATGAGAATCTTT
ACTCATTTGTGGGGACACTTCATTACAATAGAAGTCAGTATCCACTTTCACCGCAGCAGATTCTTTTGAGGGATTCAAAGCTTAAGAATACGGAGTATGT
ATACGGTGTTGTTATCTTTACCGGGAACGACACTAAGGTGATGCAGAACTCCGTGGATCCTCCTTCTAAGAGGAGCAAAATCGAGAAGACAATGGACAAG
ATCATTTATATCCTTTTCAGCGCTCTGATTACTGTATCGTTTATTGGGTCTCTATTTTTCGGTATCGAGACCAGTAGAGATTATGAAGATGGGAAATATA
GGAGGTGGTATCTTCAGCCGGATAACAGAAATGCTCTTTATGGTCCTGAAAGAGCACCACTTGCTGCTTTGCTCCACTTCTTAACAGGACTCATGCTGTA
TGGATATTTAATACCCATATCACTTTATGTGTCTATTGAAATAGTGAAGGTCTTACAAAGCATCTTCATTAACCAAGATCAGGAAATGTACCATGCGGAA
GCTGACAGGCCAGCTCGTGCACGTACTTCTAATTTAAATGAGGAACTTGGGCAGGTTGATACTGTGCTCTCTGACAAGACTGGCACACTGACATGTAATT
CAATGGAGTTTGTGAAATGTTCAATTGCTGGGAATCCCTATGGCAGGGGTATGACAGAAGTGGAATGGGCCTTATTGCAGAGAAAAAATGGCAAGCCAGT
AGATGTCGGTGACAGGCCGGATGACTCAGGTGCCTCGGGAAAGCCAGTGAAGGGATTTAACTTCAGAGACGAACGCATAATGAATGGACAGTGGATTCAT
GAACAATATTCCGACTGTATACGGATGTTCTTTCAAGTATTAGCACTATGCAATACAGCTGTTCCAGAGGAAAACAAAGAGTCTCATGAAATTTCTTATG
AAGCTGAATCACCAGACGAGGCAGCCTTTGTCGTAGCTGCTAAGGAGATGGGATTCGAGTTATATGAAAGAACACAAACGACTATATCATTGCATGAGTT
GGATCCTGCGTCTGGCAGACGAGTTGATAGAGTATACAAGGTTCTTCATGTTTTGGAATTCAGTAGTTCGCGCAAAAGAATGTCTGTGATCATAAGGAGC
ATGGAAAATCAACTGTTACTTCTATCCAAGGGTGCAGACAGCGTGATGTTTGATAGGCTGTCGAAGCATGGGCGCCTATTTGAGGCAGAGACGAAGGAGC
ACATAAAAAAATATGCCGAGGCTGGTCTTCGAACCCTGGTCATTGCCTTCCGTAAGCTTGATGAAACTGAGTATGGTAATTGGGAAGCAGAATTTACAAA
AGCCAAAACAGCAGAAACGGCAGACCGTGATGTTTTGGTGGATGAGCTCGCTGATAAGATTGAAAAGGATTTAGTTCTGCTTGGCGCTACTGCTGTCGAG
GACAAACTGCAAAAAGGGGTTCCAGAATGCATTAACAACCTTTCACAGGCAGGGATTAATATATGGGTCATAACTGGTGATAAGATGGAGACGGCGATAA
ATATCGGGTATGCTTGTAGTCTGCTAAGACAAGGAATGAAACAAATCACAATCTCGTTAGACTTGCCAGAGATTGAAGCCTTGGAGAAACAGGGGGATAA
AGAGGTCGCTTCTAAGGCTTCTCTGGAAAGTGTAACGAAGCAAATCAACGACGGAAGAGCCCTGTTGAATTCTGCCAAAGGAAGCTCAATGGAGTTTAGT
TTAGTGATTGATGGGAAGTCTTTGGGTTATGCCCTTAACGAAAGCCTAGAGAAGTCGTTTCTGGAGCTTGCGCTTGATTGTGCTTCTGTCATATGTTGCA
GGTCTACTCCTAAACATAAGGCTCTTGTCACAAGATTGGTAAAAACAAGAACAGGTAAGATAACATTGGCCATTGGTGACGGGGCAAATGATGTAGGTAT
GCTTCAGGAAGCTGACATAGGAGTCGGCATAAGTGGTGCTGAAGGAATGCAGGCTGTGATGGCAAGTGATTACTCGATAGCACAATTCCGTTTTCTAGAA
CGTTTGTTACTGGTTCATGGTCATTGGTGCTACAGGAGAATAGCTATGATGATTTGTTACTTCTTCTACAAGAACATTGCATTCGGATTTACATTATTTT
GGTATGAAGCTTATGCTTCGTTCTCCGGTCAGCCTGCATATAACGACTGGTATATGTCATTCTACAACGTCTTCTTCACATCATTTCCAGTAATCGCACT
TGGAGTTTTCGATCAGGATGTTTCCGCTAGGCTTTGCCTTAAGTATCCGGTATTATATCAAGAAGGCGTACAGAACGTCCTCTTCAGCTGGTCCCGTATC
CTAGGTTGGATGTGCAATGGAGTCCTGACATCCATTATCATCTTCTTCTTCACCACCAACTCCTTGATCAATCAAGCACTCCGAGAAGATGGGCAAGTAA
CCGACTATGCGATCCTGGGAGCAACAATGTACACATGCGTGGTGTGGACAGTAAACTGCCAAATGGCACTCTCCATCAATTACTTCACTTGGATTCAGCA
CTTCTTCATCTGGGGAAGCATAGCATTCTGGTACATATTTCTCTTGATCTACGGCTACATTGACCCAACAATATCCACAACAGCTTACATGGTACTCATA
GAAGCCTGCATCCCAAGTCCTCTCTATTGGCTCGTAACGCTTCTCGTTGTGGTGTCTGCTCTGCTGCCTTGCTTTGCGTACCGAGCCTTCCAGTCCAGAT
TCCGGCCAATGTACCATGACATTATACAGATACGGAGAGCAGAAGGCTCGGAGATTGAAACTTCTTCCGGTGCAGGCGAGTTGCCTACAGACGTTAAGTT
AAGAGTGCATCATCTCAAGGAAGGGTTGAGGCAGAGGAACTCGTAA
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
AA sequence
|
>Lus10022238 pacid=23139497 polypeptide=Lus10022238 locus=Lus10022238.g ID=Lus10022238.BGIv1.0 annot-version=v1.0
MGRRRKLLRFSKLYSFSCFKASFEDDHAQIGRKGYSRVVYCNDPDSPESVELNYKGNYVSTTKYTAANFIPKSLFEQFRRVANIYFLVVACVSFSPLAPY
NAKSILAPLVVVIGATMVKEAVEDWRRRKQDVEANNRKVKVLGKNSKFTQTRWKHLRVGDIVEVDKDQYFPADLLLLSSSYDDGVCYVETMNLDGETNLK
LKHALEVTSSLHDEGGLKEFKAVIKCEDPNENLYSFVGTLHYNRSQYPLSPQQILLRDSKLKNTEYVYGVVIFTGNDTKVMQNSVDPPSKRSKIEKTMDK
IIYILFSALITVSFIGSLFFGIETSRDYEDGKYRRWYLQPDNRNALYGPERAPLAALLHFLTGLMLYGYLIPISLYVSIEIVKVLQSIFINQDQEMYHAE
ADRPARARTSNLNEELGQVDTVLSDKTGTLTCNSMEFVKCSIAGNPYGRGMTEVEWALLQRKNGKPVDVGDRPDDSGASGKPVKGFNFRDERIMNGQWIH
EQYSDCIRMFFQVLALCNTAVPEENKESHEISYEAESPDEAAFVVAAKEMGFELYERTQTTISLHELDPASGRRVDRVYKVLHVLEFSSSRKRMSVIIRS
MENQLLLLSKGADSVMFDRLSKHGRLFEAETKEHIKKYAEAGLRTLVIAFRKLDETEYGNWEAEFTKAKTAETADRDVLVDELADKIEKDLVLLGATAVE
DKLQKGVPECINNLSQAGINIWVITGDKMETAINIGYACSLLRQGMKQITISLDLPEIEALEKQGDKEVASKASLESVTKQINDGRALLNSAKGSSMEFS
LVIDGKSLGYALNESLEKSFLELALDCASVICCRSTPKHKALVTRLVKTRTGKITLAIGDGANDVGMLQEADIGVGISGAEGMQAVMASDYSIAQFRFLE
RLLLVHGHWCYRRIAMMICYFFYKNIAFGFTLFWYEAYASFSGQPAYNDWYMSFYNVFFTSFPVIALGVFDQDVSARLCLKYPVLYQEGVQNVLFSWSRI
LGWMCNGVLTSIIIFFFTTNSLINQALREDGQVTDYAILGATMYTCVVWTVNCQMALSINYFTWIQHFFIWGSIAFWYIFLLIYGYIDPTISTTAYMVLI
EACIPSPLYWLVTLLVVVSALLPCFAYRAFQSRFRPMYHDIIQIRRAEGSEIETSSGAGELPTDVKLRVHHLKEGLRQRNS
|
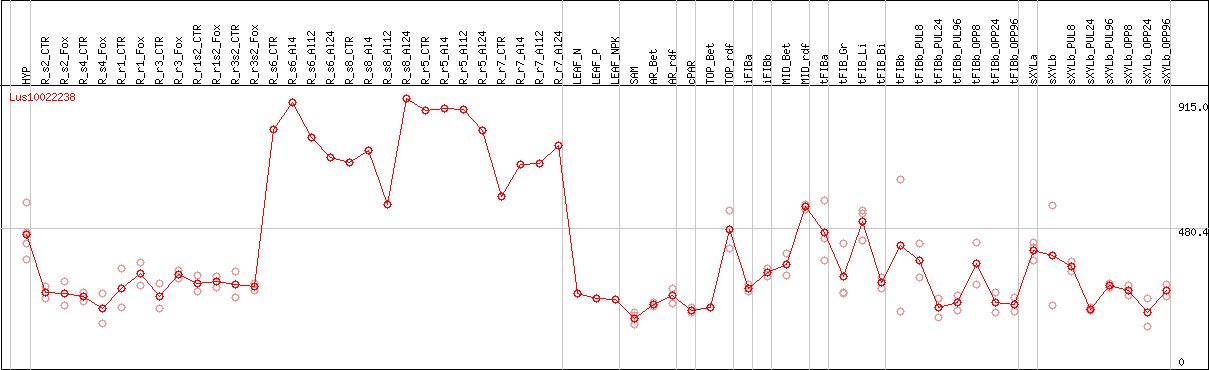
DESeq2's median of ratios [FLAX]
Coexpressed genes
Lus10022238 coexpression network
*The number of genes in the network is adjusted within 50 genes.*Gene name represents symbol(s) of closest Arabidopsis gene if symbol(s) for the gene itself doesn't exist.
*Circle diameter represents the number of connection with other genes within this network.
*Color for gene name represents subnetwork based on the result of network clustering.