Lus10022454 [FLAX]

| External link |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Symbol | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Arabidopsis homologues
|
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Paralogs
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Poplar homologues |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
| PFAM info |
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Representative CDS sequence |
>Lus10022454 pacid=23171633 polypeptide=Lus10022454 locus=Lus10022454.g ID=Lus10022454.BGIv1.0 annot-version=v1.0
ATGGATCCGAAAGGATTCAATTCGAAGGAAGGCGAGGCCTTGGTATTGTGCGGAGACAGGAATATGGGAACCGGAATCGAGTTGTGGGATTTAGAGTCAG
GAGATCGTATTCTTCACATCCCAACTTGCGCCTCTCCTCCTCACGGACTATCCTGCTTGAGATCCCAGGTTCTCTTCGCTTCTCAGGCCAATAAGCATGG
CTCTGTTGGCGGTGGAGCCATTTTCTCTTGGCATTTAAACAAGCCTCACTCACCGATAAGGAGCTACCAGATTGAAGCCATTGGGCCACTTGCTGCCACC
TACAACGGGATGTATCTGGTAGCTGGTGCTCTTTCAGGAAATGCTTATATATGGGAGGTGACTAGTGGGAGATTGCTCAAAACTTGGAGAGCCCATCATA
GATCTTTCAAGTGCATTGCTTTCTCTAATAATGATTCCCTTGTTATTGTTGGATCCGATGATGGGACTATTCTTGCGTGGCCATTAATTAGTTTGCTGGT
CGTTGAAGATGGTGGAAGCTCGTCGTCATTGTTACACTATTCGATGGAGCATAAGTCCTCTATAACATCACTATTAATGCCGCCTGGCAGTACAAACTCC
TTGTTTATATCTACTTCTCTTGATGCCACTTCCAAGGTGTGGGAGCTCGTCTCTGGTAGGTTGATGCAAACACTCGAGTATGCGACGGGAATAGCTGCAG
CTACCCTGCATCCAGATGAGCCACTTCTGTTCACTGGTAGCAGTATAGATGGAAGAATATTTGTTAATGTTGTTGATCTTGGACTGATACATGATCATGA
ATCTATTACTGGGGTACAAGGACAGATGGGTGTGCTAAAAGGACACAATGGGTCAATAACAGCATTAACGTTTAGCAGATCTGGCCTCATATCTGCATCT
GAAGATTGCACTGTCTGCCTTTGGGATGTAGGTTCTCAGCAGATTGTATGGAGAATCAACCATAAAAAAGGACCTGTTACGAATCTCGTACTAGTTCCAC
ATTCTTCAATGCTTTCCACTCCAAATCATCACCAAAGAGTTTCTAGTCGGTTTTGCATTTCTTTGCTCGACAAGTGCCATCGGCAGGCCGATCCATCTAA
AGGAGTGATTGCTTTTCTCCCATCATATTCTTTACCTATTGATGGCGGACAAAGTAGTACTTCATTAGAGTTACAGATAAACAATTCAGTGGATCGTCAA
ATATTGGAGATAGAGATGAGCATAGGGAAGCAGATGTGGGCTTTGCAAATGACGAAGCACGTTATGAAAATGAACAAGCATTTGCAGAGTCGACTGCTAG
ACCTGATGCAGAGCAGATTACTGCTGGCTTGCCACAACACAGATGTCCCTAGGATAAATAATAAGAAGAAGAAGACGACGAATAAAACACAGCTGAAGAC
TCAAAGTAGATGTTCATCTGAAGAGGAGCTGTCCTTCCAACCGGGGAACGCTTCCTTGTACGTTTTTCTAACAAGTTCCCGCTCCAAGCTGCAGCTCAGT
ACTTTTCTAAAACCCTGCTGCCGCTCTCTACTCCCCTATCTGGATTTTTTCTTGTTAGGATTATCGGCAAGGCCCTATCTGGGTCCGTCGGCACAAATGC
GTTTGGAGCTTTTAGGGATTTCTTCTCCCTCACCTTCCTTCAACTCACTCTCCTCTCTCAACCCAAACATGTCCACTTTCAGTCTCACTGCTCCCTCGCT
CTGCCCTTATTACCGCCCTGGTCTTGCCAAGTTCTCTGTTTCTTGCGGCACTGGTTCCCCGACCAAGATAGGAAGCAGCCGGGTATCCAAAGCAACACCA
CGTAAAAGACCAAGTAGAAGAATGGAAGGGGTAGGGAAAAGTATGGAGGATTCTGTTAAACGCAAAATGGAACAGTTCTATGAAGGAGCTGATGGCCCAC
CGCTACGTATTGTTCCAATTGGTGGACTTGGCGAGATTGGAATGAATTGCATGCTGGTCGGGAATTACGATCGCTATATTCTAATTGACGCTGGTGTTAT
GTTTCCTGACGATGAAGATCTCGGCGTTCAAAAGATTTTGCCAGACACCACGTTTATCAAAAGATGGAGTCACAAAAGTATCCACAAAGTTGGGGCGGTT
GTTATAACTCATGGCCATGAAGATCACATCGGTGCGTTGCCATGGGTGATTCCGGCTTTGGATGCAAATACCCCGATATTCGCTTCATCTTTTACAATGG
AGCTGATCAAAAAACGTCTGAAGGAGCATGGTTTCTTTCTTCCTTCCAGACTAAAAGTTTTCAGAACAAGGAAGAGATTCACTGCTGGGCCTTTTGAAAT
AGAGCCAATCACAGTGACCCACTCAATTCCTGATTGTAGTGGTCTCATTCTTCGTTGTTCTGATGGTATAATCCTTCATACTGGTGATTGGAAGATAGAT
GAATCACCATTGGATGGCAAACCATTTGATCGTGAAGCTCTAGAAGAACTCTCAAAGGAAGGAGTGACATTGATGATGAGCGATTCAACAAATGTGTTAT
CGCCAGGAAGGACAACTAGTGAAACTGTTGTAGCGGATTCACTGTTGAGACATATTTCTGCTGCTAAAGGAAGGGTTATTACTACTCAATTTGCGTCAAA
TATATGGCGGCTAGGAAGTGTGAAAGCTGCTGCTGATTTGACAGGAAGAAAGCTTGTTTTTGTTGGCATGTCCTTAAGGACATACTTGGATGCTGCTTGG
AAGGATGGAAAAGCACCTATTGACCCTGCCACTCTGGTGAAAGCAGAAGATATTGATCAATACGCACCTAAAGATTTATTGATTGTAACAACTGGGTCAC
AAGCAGAACCTCGAGCCGCACTAAATCTTGCATCGTATGGAACTAGCTATGCTTTCAAACTGAAAAAGGAAGATATAATTCTTTATTCAGCTAAGGTTAT
CCCTGGTAATGAATCAAGAGTAATGAAAATGATGAATCGCATAACAGAAATTGGGTCAACCATAGTAATGGGTAGAAACGAGCAACTGCACACTTCTGGT
CATGGGTATCGTGGAGAGCTGGAGGAGGTACTTAAAATCGTGAAACCGCAGCACTTTCTCCCTATACATGGAGAACTCTTGTTCTTGAAAGAACATGAAT
TGCTTGGAAAGTCAACTGGAGTGCATCATACTACTGTCATTAAGAACGGGGAGATGCTCGGGGTATCACATTTAAGGAATAGAAGAGTGTTATCTAATGG
TTTCATTTCTCTCGGAAAGGAGAATTTACAGCTAATGTATAGTGATGGTGATAAAGCATTTGGCACAGCAACTGAGCTTTGCATCGAGGAGAGGCTAAGA
ATTGCAACCGATGGAATCATAGTGGTCAGCATGGAAATCTTGCGACCTCAGGGCGTAGATAGTGTGAGCGAAAATAACATAAAAGGCAGAATAAGAATCA
CAACACGGTGCTTGTGGTTGGACAAGGGGAAGCTTTTAGATGCACTCCACAAAGCTGCCCACGCCGCCCTTTCAAGTTGCCCTTTAAACTGTCCTTTAGC
GCACATGGAAAGAACAGTAGCCGAGGTATTAAGGAAGATGGTGAGGAAGTATAGTGGCAAAAGGCCTGAGATGATTGTTATTGCCATGGAAAACCCAGCA
GGGGTTCTTTCTGAAGAACTGTCTGCAAAGCTTGCTGGCAAATCAGAAATGGGGTTTGGGATATCAGCATTGAGAAAAGTAATCGACAAACATCCTGAAA
GAAGAAACAACAAGTCACAAATTGACGAAAATGGATATGGTTACATTGAGGATGCACCACTAGAGGATTCTGAAGAAGAGGATGCAGTTGAGGAAGATAA
CACTAATTCAAGTGAGAGGTTGGATGGAAGGACTGAGGAGGATGATAATTTTTGGCGTTCAATGATCTCATCACTGCCTGGTGACCCTTCAGAAGAAGAA
GCTAATGTGAGAGGTGGTGGTAATGACAGTAGTGAAGATAATGACGCAGAGAAAACTAGGCAGAAATCTGGTAAGCGTAATAAGTGGAAACCGGAGGAGA
TCAAGAAGCTAATTAAAATGAGAGGGATTTTCCATAGCAGGTTTATAAGTGTAAAGGGAGGAAGGATGGCCCTCTGGGAAGATATATCTAGTAGCTTGAT
GGAAGAGGGGATCGAACGCACTCCAGGACAATGCAAATCGCTGTGGGCATCTCTGGTACAAAAATACGAGGAAAGCAAAAACGGGCCTGAGAGTGGAAAA
GAATGGCAATATTTTGAACAAGTGAAGAGCATTCTATCTGATCACGAGCCTGAGCCAACAGCAGCGGCTAAATGA
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
AA sequence
|
>Lus10022454 pacid=23171633 polypeptide=Lus10022454 locus=Lus10022454.g ID=Lus10022454.BGIv1.0 annot-version=v1.0
MDPKGFNSKEGEALVLCGDRNMGTGIELWDLESGDRILHIPTCASPPHGLSCLRSQVLFASQANKHGSVGGGAIFSWHLNKPHSPIRSYQIEAIGPLAAT
YNGMYLVAGALSGNAYIWEVTSGRLLKTWRAHHRSFKCIAFSNNDSLVIVGSDDGTILAWPLISLLVVEDGGSSSSLLHYSMEHKSSITSLLMPPGSTNS
LFISTSLDATSKVWELVSGRLMQTLEYATGIAAATLHPDEPLLFTGSSIDGRIFVNVVDLGLIHDHESITGVQGQMGVLKGHNGSITALTFSRSGLISAS
EDCTVCLWDVGSQQIVWRINHKKGPVTNLVLVPHSSMLSTPNHHQRVSSRFCISLLDKCHRQADPSKGVIAFLPSYSLPIDGGQSSTSLELQINNSVDRQ
ILEIEMSIGKQMWALQMTKHVMKMNKHLQSRLLDLMQSRLLLACHNTDVPRINNKKKKTTNKTQLKTQSRCSSEEELSFQPGNASLYVFLTSSRSKLQLS
TFLKPCCRSLLPYLDFFLLGLSARPYLGPSAQMRLELLGISSPSPSFNSLSSLNPNMSTFSLTAPSLCPYYRPGLAKFSVSCGTGSPTKIGSSRVSKATP
RKRPSRRMEGVGKSMEDSVKRKMEQFYEGADGPPLRIVPIGGLGEIGMNCMLVGNYDRYILIDAGVMFPDDEDLGVQKILPDTTFIKRWSHKSIHKVGAV
VITHGHEDHIGALPWVIPALDANTPIFASSFTMELIKKRLKEHGFFLPSRLKVFRTRKRFTAGPFEIEPITVTHSIPDCSGLILRCSDGIILHTGDWKID
ESPLDGKPFDREALEELSKEGVTLMMSDSTNVLSPGRTTSETVVADSLLRHISAAKGRVITTQFASNIWRLGSVKAAADLTGRKLVFVGMSLRTYLDAAW
KDGKAPIDPATLVKAEDIDQYAPKDLLIVTTGSQAEPRAALNLASYGTSYAFKLKKEDIILYSAKVIPGNESRVMKMMNRITEIGSTIVMGRNEQLHTSG
HGYRGELEEVLKIVKPQHFLPIHGELLFLKEHELLGKSTGVHHTTVIKNGEMLGVSHLRNRRVLSNGFISLGKENLQLMYSDGDKAFGTATELCIEERLR
IATDGIIVVSMEILRPQGVDSVSENNIKGRIRITTRCLWLDKGKLLDALHKAAHAALSSCPLNCPLAHMERTVAEVLRKMVRKYSGKRPEMIVIAMENPA
GVLSEELSAKLAGKSEMGFGISALRKVIDKHPERRNNKSQIDENGYGYIEDAPLEDSEEEDAVEEDNTNSSERLDGRTEEDDNFWRSMISSLPGDPSEEE
ANVRGGGNDSSEDNDAEKTRQKSGKRNKWKPEEIKKLIKMRGIFHSRFISVKGGRMALWEDISSSLMEEGIERTPGQCKSLWASLVQKYEESKNGPESGK
EWQYFEQVKSILSDHEPEPTAAAK
|
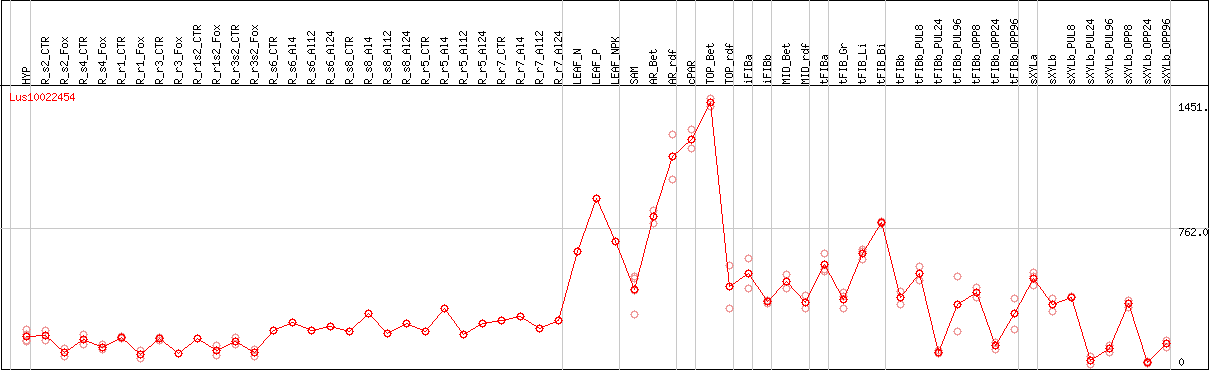
DESeq2's median of ratios [FLAX]
Coexpressed genes
Lus10022454 coexpression network
*The number of genes in the network is adjusted within 50 genes.*Gene name represents symbol(s) of closest Arabidopsis gene if symbol(s) for the gene itself doesn't exist.
*Circle diameter represents the number of connection with other genes within this network.
*Color for gene name represents subnetwork based on the result of network clustering.