Lus10022858 [FLAX]

| External link |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Symbol | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Arabidopsis homologues
|
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Paralogs
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Poplar homologues |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
| PFAM info |
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Representative CDS sequence |
>Lus10022858 pacid=23160069 polypeptide=Lus10022858 locus=Lus10022858.g ID=Lus10022858.BGIv1.0 annot-version=v1.0
ATGGGTTCTTCGTATTGGGTGGTTGATAATCACTATTGGCTACCATTTCATCACACTCTCTGGGAAGCAATCCACGGCATTCCCGTCTTGGAACTCACTT
CAATTTGCGTCAATTTGACACTCTTTCTGGTGTTCTTGTTGATCATCTTTGCGAGCAAGCTTTCTTTATGTGTTGGAAGGACCAGGCTGCTCAAAGATGA
TGCCTCTTCGGTTGCCAGCTCTAGCCCAATTCGACGGGCTAGTATTGTGGATGGAGAGACTCGTGAGATTGTTGTCGGCACTATGTTCAAGTTCTCTTTG
TTTTGCTGCTTCTATGTCTTGTTTCTCCAGCTTTTGGTGCTGGGATACGATGGTTTTGTTCTGGTTAGAGATTCGGTTGGTGGGGAAGTCCAGGACTGGA
CCGTGCTTTGCTTGCCTGCTTCTCAAGGCTTAACATGGCTTCTCTTGAGCTCTTGGGCTCTTCATTGTAAATTCCACGCATGTGAGAAGTTCCCGGCGCT
GCTAAGAATATGGTGGGTGTTCTCATTTCTGATGTGCTTGTGTACTTTGTATGTGGACTGGAGGAGCCTTCTGACGGACGGTTACGGGCATCTGAATGCT
ACAGTTGTGGTGAATTTTGCTGCAACACCTGCCATGGCTTTTCTATCTTTTCTTTCGACCAGAGGGGTTACTGGCATAGAAGTTCTGAGAAACTCTGACC
TTCAAGAGCCATTGCTTCTGGAAGAAGACCCTGCATGTCTCAGGATAACTCCTTACAGTGATGCTGGGTTCTTTAGCGTGCTCACTCTCTCTTGGTTGAA
CCCACTACTGTCCACTGGTGCAAAGAGACCGCTAGAGCTGAAGGACATTCCCTTGCTTGCACCAGAAGATCGAGCGAAAGCCAATTTTAAGCTTTTGAAT
TCAAACTGGGAGAAAATGAAGGCTGATAATCCTTCAAAGCAACCTTCTTTAGCTATGGCAATTCTGAAGTCTTTTTGGAGGGAAGCATTTCGTAATGCCA
TCTTTGCCCTGTTGAACACTGTTGTCTCTTATGTTGGCCCATACTTGATTAGCTACTTTGTGGAGTATCTGGGAGGGCAGCAGACTTTTCAATATGAGGG
GTACATTCTGGCTGGAATATTTTTCTCCGCCAAGCTTGCTGAGACTGTAACGACCCGCCAATGGTATCTTGGGGTTGACATATTAGGCATGCATGTGAGA
TCGGCTTTGACTGGCATGGTTTATCGTAAAGGGCTCAAGCTCTCGAGCTTGTCTAAGCAAAGTCATACCAGTGGAGAAATTGTCAACTATATGGCAGTTG
ATGTCCAGAGAGTAGGGGATTACTCTTGGTATCTTCACGATATATGGATGCTTCCCTTGCAGATTATATTGGCTCTGGCAATTTTGTATAAGAATGTTGG
AATTGCTGCAGGAGCAACTTTACTTGCCACCATCTTCTCTATTGTGGTAACCATTCCTCTTGCTAGGCTGCAAGAAAACTATCAGGACAAACTAATGGCT
GCAAAGGATGAAAGAATGAGGAAGACTTCTGAGTGCCTGAGGAACATGAGGATCCTGAAGCTGCAGGCTTGGGAGGATAGGTATCGACTGCAGTTGGAGG
AAATGCGGAGTGTGGAATTCAAGTGGCTCCAAAAAGCCCTTTATTCGCAATCCTTCATAACTTTCTTCTTCTGGAGCTCTCCTATATTTGTTGCTGTTGT
CACTTTTGGTACTTCTATATTGCTGGGTGGTCAGCTAACAGCTGGAAGCGTGCTTTCATCACTGGCCACTTTCAGAATTCTACAGGAGCCACTCAGAAAC
TTCCCTGACTTGGTTTCTATGATGGCCCAGACTAAAGTATCCCTTGATCGACTTTCTACATTCCTGCAAGAGGAAGAGTTGAGCGAAGATGCCACTATTG
TGCTACCACGAGGTACAACTCCCTTTGCAATTGAGATTAAAGATGGTGAGTTCTCCTGGACCCCTACGGTTCCAATGCCCACCTTATCGGGGATACAAAT
GAAAGTGCAAAAAGGAATGCGTGTAGCTGTTTGTGGAAAAGTTGGCTCTGGTAAATCAAGCTTCCTCTCGTGCATTCTGGGCGAGATACCAAAATTATCT
GGTGAAGTGCGAATATGTGGGTCTGCTGCTTATGTTCCCCAGTCTGCTTGGATACAATCTGGAAATATTGAAGAAAATATCCTATTTGGCAGTCCAATGG
ACAAGCCCAAGTATAAAGCAGTTATTCATGCTTGTTCACTCAAAAAGGATTTGGAACTTTTCTCACACGGGGATCAGACCATTATTGGGGATCGGGGTAT
AAATTTAAGCGGTGGTCAAAAGCAAAGAGTTCAGCTTGCAAGAGCGCTTTATCAAGATGCAGATGTTTATTTGCTTGATGATCCTTTCAGTGCTGTTGAT
GCACATACTGGTTCAGAATTGTTTAAGGAATATATATTAACAGCACTAGCAGCTAAAACTGTGATTTATGTGACTCACCAAGTTGAGTTCTTGCCAGCTG
CAGATCTAATATTGGTTCTTAAGGAAGGTCAGATTACGCAAGCAGGTAGGTACGAGGAGCTTCTACGAGCAGGAACTGATTTCATCAGTTTGGTCTCTGC
TCACCAGGAAGCAATTGGAGCTATGGACATTCCTATTCATTCGACAGACGATTCAGATGACGGTGTAGCTTTGGATGGTCCTATCATGCTTCATAAAAAG
TGTGAAGCATCTGTAAGTAATGTTGACAATCTTGCAAAAGAAGTGCAAGAAACTGCAGCTTCTTCTGATCAGAAAGCAGTGAAAGAGAAAAAGAAAGTAA
AACGTTCGAGGAAGAAACAGCTTGTTCAAGAGGAGGAAAGGGTTAGGGGAACAGTAAGCATGAAAGTTTATTTGTCATATATGGCTGCAGCATATAAGGG
GATGTTGGTTCCCCTCATACTCCTGTCACAAGCACTATTTCAGTTTCTTCAAATAGCTAGTAATTGGTGGATGGCTTGGGCAAATCCCCAGATGGAAGGA
GGAGAAGCGAAAGTGAGTCCGATGGTCCTACTTGGTGTTTATATGGCCCTTGCTTTTGGGAGCTCTGTGTTTATACTTTCCAGGGCTGTTTTGGTTGCTA
CATTTGGTTTAGCTGCTGCACAGAAGTTGTTTCTGATGATGCTTAGAAGTGTGTTTCGATCGCCTATGTCTTTCTTCGACTCTACTCCAGCTGGACGGAT
CTTGAATCGTGTATCTGTTGACCAAAGTGTTGTTGATCTGGATATACCTTTTAGACTCGGTGGCTTTGCTTCAACAACAATACAGCTTATTGGAATCGTT
GCTGTAATGACACAAGTGACTTGGCAAATTTTGCTTCTTGTTATTCCAATGGCTGTAGCATGCCTATGGATGCAGAAATACTACATGGCTTCATCAAGGG
AACTAGTTCGCATCGTCAGCATCCAGAAGTCTCCTGTCTTCCATCTTTTCAGCGAGTCCATTGCTGGAGCCGCCACTATAAGAGGTTTTGGGCAAGAGAA
AAGGTTCATGAAAAGGAATCTTTATCTTCTTGACTGTTTCACTCGCCCGTTCTTCTGCAGTCTGGCGGCTATCGAGTGGCTCTGTCTGCGCATGGAACTA
CTGTCAACCTTCGTATTTGCTTTCTGCATGCTTTTGCTCGTAAGCTTTCCCCATGGAAGCATCGACCCAAGTATGGCAGGCCTTGCTGTGACATATGGCC
TTAATCTTAATGCTCGTCTGTCACGATGGATACTTAGCTTTTGCAAGGTTGAAAACAAAATAATTTCCATAGAAAGGATATATCAATATAGCAGAATTTC
GAGTGAAGCACCAGCAATTATAGAGGAGTCTCGCCCACCGTCCTCATGGCCGGAGAATGGACAAATTGACATAATTGATTTGAAGGTCCGTTATGGTGAG
AATCTCCCTATGGTGCTTCATGGGGTATCCTGCAGCTTTCCTGGTGGCAAGAAGATTGGAATTGTTGGGAGAACCGGTAGTGGAAAATCTACACTGATCC
AGGCCTTGTTTCGGTTAATCGAACCAGCTGGTGGAAGAATCATTATAGACAACATTGATATTTCAAAGATTGGGCTCCATGATCTTCGTAGCCGCCTCAG
TATCATTCCTCAAGATCCAACCTTGTTTGAAGGAACCATTAGGGGAAATCTCGACCCTCTTGAGGAGCACACTGATCAGGAAATCTGGCAGGCTCTAGAT
AAGTCTCAACTTGGTGATGTAATCCGGGAGAAAGATGAAAAACTTGATGCCCCAGTTCTAGAAAATGGAGATAACTGGAGCGTGGGACAGAGGCAACTTG
TTGCACTAGGGCGTGCGTTGCTCAAACAGGCCAGAATACTGGTACTAGATGAAGCAACCGCATCAGTCGACACGGGGACTGACAATCTTATCCAGAAGAT
TATCCGGACAGAGTTCAAGAACTGCACTGTCTGCACAATTGCTCACCGCATCCCAACAGTCATTGACAGTGATCTCGTTTTGGTACTAAGCGACGGTCGT
CGCGCTGAGTTTGATACTCCAACTCGGTTGTTAGAGGATAAATCGTCCATGTTCCTAAAACTGGTCACTGAATACTCGTCAAGGTCAAATGGCATACCTG
ACTTCTAA
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
AA sequence
|
>Lus10022858 pacid=23160069 polypeptide=Lus10022858 locus=Lus10022858.g ID=Lus10022858.BGIv1.0 annot-version=v1.0
MGSSYWVVDNHYWLPFHHTLWEAIHGIPVLELTSICVNLTLFLVFLLIIFASKLSLCVGRTRLLKDDASSVASSSPIRRASIVDGETREIVVGTMFKFSL
FCCFYVLFLQLLVLGYDGFVLVRDSVGGEVQDWTVLCLPASQGLTWLLLSSWALHCKFHACEKFPALLRIWWVFSFLMCLCTLYVDWRSLLTDGYGHLNA
TVVVNFAATPAMAFLSFLSTRGVTGIEVLRNSDLQEPLLLEEDPACLRITPYSDAGFFSVLTLSWLNPLLSTGAKRPLELKDIPLLAPEDRAKANFKLLN
SNWEKMKADNPSKQPSLAMAILKSFWREAFRNAIFALLNTVVSYVGPYLISYFVEYLGGQQTFQYEGYILAGIFFSAKLAETVTTRQWYLGVDILGMHVR
SALTGMVYRKGLKLSSLSKQSHTSGEIVNYMAVDVQRVGDYSWYLHDIWMLPLQIILALAILYKNVGIAAGATLLATIFSIVVTIPLARLQENYQDKLMA
AKDERMRKTSECLRNMRILKLQAWEDRYRLQLEEMRSVEFKWLQKALYSQSFITFFFWSSPIFVAVVTFGTSILLGGQLTAGSVLSSLATFRILQEPLRN
FPDLVSMMAQTKVSLDRLSTFLQEEELSEDATIVLPRGTTPFAIEIKDGEFSWTPTVPMPTLSGIQMKVQKGMRVAVCGKVGSGKSSFLSCILGEIPKLS
GEVRICGSAAYVPQSAWIQSGNIEENILFGSPMDKPKYKAVIHACSLKKDLELFSHGDQTIIGDRGINLSGGQKQRVQLARALYQDADVYLLDDPFSAVD
AHTGSELFKEYILTALAAKTVIYVTHQVEFLPAADLILVLKEGQITQAGRYEELLRAGTDFISLVSAHQEAIGAMDIPIHSTDDSDDGVALDGPIMLHKK
CEASVSNVDNLAKEVQETAASSDQKAVKEKKKVKRSRKKQLVQEEERVRGTVSMKVYLSYMAAAYKGMLVPLILLSQALFQFLQIASNWWMAWANPQMEG
GEAKVSPMVLLGVYMALAFGSSVFILSRAVLVATFGLAAAQKLFLMMLRSVFRSPMSFFDSTPAGRILNRVSVDQSVVDLDIPFRLGGFASTTIQLIGIV
AVMTQVTWQILLLVIPMAVACLWMQKYYMASSRELVRIVSIQKSPVFHLFSESIAGAATIRGFGQEKRFMKRNLYLLDCFTRPFFCSLAAIEWLCLRMEL
LSTFVFAFCMLLLVSFPHGSIDPSMAGLAVTYGLNLNARLSRWILSFCKVENKIISIERIYQYSRISSEAPAIIEESRPPSSWPENGQIDIIDLKVRYGE
NLPMVLHGVSCSFPGGKKIGIVGRTGSGKSTLIQALFRLIEPAGGRIIIDNIDISKIGLHDLRSRLSIIPQDPTLFEGTIRGNLDPLEEHTDQEIWQALD
KSQLGDVIREKDEKLDAPVLENGDNWSVGQRQLVALGRALLKQARILVLDEATASVDTGTDNLIQKIIRTEFKNCTVCTIAHRIPTVIDSDLVLVLSDGR
RAEFDTPTRLLEDKSSMFLKLVTEYSSRSNGIPDF
|
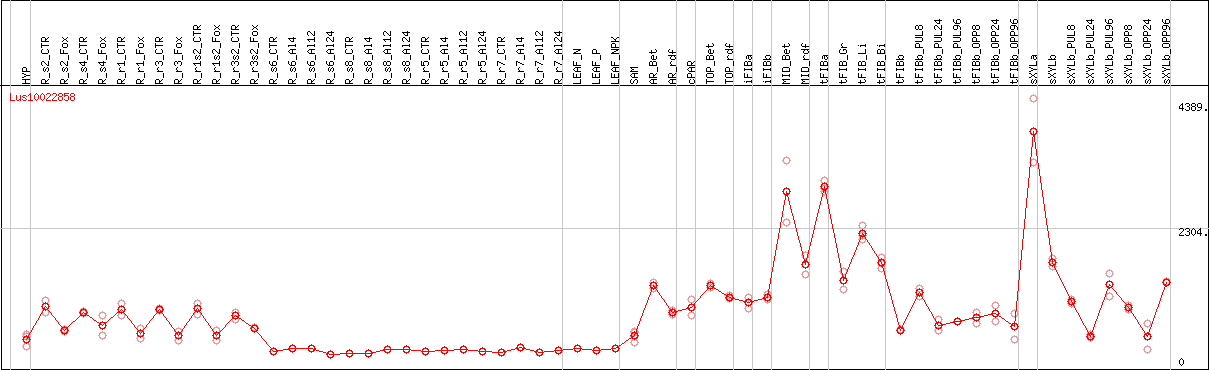
DESeq2's median of ratios [FLAX]
Coexpressed genes
Lus10022858 coexpression network
*The number of genes in the network is adjusted within 50 genes.*Gene name represents symbol(s) of closest Arabidopsis gene if symbol(s) for the gene itself doesn't exist.
*Circle diameter represents the number of connection with other genes within this network.
*Color for gene name represents subnetwork based on the result of network clustering.