Lus10023328 [FLAX]

| External link |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Symbol | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Arabidopsis homologues
|
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Paralogs
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Poplar homologues |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
| PFAM info |
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Representative CDS sequence |
>Lus10023328 pacid=23180914 polypeptide=Lus10023328 locus=Lus10023328.g ID=Lus10023328.BGIv1.0 annot-version=v1.0
ATGGGGAGGGGAGGTGAGGACTCCGGTAAGAGTGAAAAACTCGGAGTTGAATCGGAAAATCGCGGAGTATTCCCAGCTTGGGCGAAAGACGTGAAGGAAT
GCGAGGCTGAATACGAGGTTGATAGTCATTACGGGCTTTCGGTTGCGGAAGTGGCGAAGAGGCTCGATATCCATGGTTACAACGAGTTGGAGAAGCACGA
AGGGACGTCGATTTGGGAGTTGATAGTGGAGCAATTCAAGGACACTTTAGTTAGGATATTGTTGGCCGCTGCAGTCATATCTTTTGTTTTGGCTTGGTAT
GATGGCAAGGAAGGCGGGGAGATGGAGATCACTGCTTTTGTGGAGCCATTGGTGATTTTCTTGATATTGATTGTTAATGCGATCGTGGGGATTTGGCAGG
AAAGCAATGCGGAGAAAGCATTGGAAGCGTTGAAGGAAATCCAGTCAGAGACTGCCGCTGTTTTAAGGGATGGGAAGAAGATTTCAAGCTTGCCGGCGAA
GGAACTTGTTCCTGGTGATATTGTGGAGTTGAGGGTAGGAGATAAGGTGCCTGCTGATATGCGGGTTTTGAGTTTGGTCAGCTCCACGGTGAGGGTTGAG
CAAGGTTCTTTGACGGGAGAAAGTGAAGCTGTGAGCAAGACTGTTAAAACTGTTGCTGAGCATACAGATATTCAGGGGAAAAAATGTATGCTTTTTGCCG
GAACCACGGTGGTGAATGGTAATTGCATGTGTTTGGTCACTGGGACTGGAATGAACACTGAGATAGGTAAGGTGCATTCACAAATTCATGAAGCCTCCCA
ACACGAGGAAGATACCCCGTTGAAGAAGAAGTTGAATGAGTTTGGAGAGGCTCTAACCATGATTATTGGCGTTATTTGTGCATTGGTTTGGCTTATTAAT
GTCAAGTACTTCCTCAGTTGGGAATACGTTGATGGCTGGCCGAGAAACTTCAAGTTCTCATTTGAGAAGTGCACCTATTACTTCGAGATTGCTGTGGCAT
TGGCAGTGGCTGCAATACCTGAAGGATTACCAGCAGTCATTACAACTTGTTTGGCACTTGGAACTCGGAAAATGGCTCAGAAAAATGCTCTTGTCAGGAA
GCTGCCAAGTGTTGAAACTCTTGGTTGTACCACTGTCATTTGCTCTGATAAGACAGGTACCCTCACAACCAATCAGATGGCTGTATCAAAGCTTGTGGCT
ATGGGGTCCATGGCTGGAAATCTGAGATCATTTAATGTGGAGGGCACAACTTACAATCCCTGTGATGGTAAAATTGAAGATTGGCCAGTTGGTCGAATAG
ATTCTAACCTTCAGATGATCGCAAAGATTTCTGCCATTTGTAATGATGCTGGTGTGGAACAATCAGGACAGCAATATATTTCTACAGGAATGCCTACAGA
GGCTNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNN
NNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNN
NNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNN
NNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNN
NNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNN
NNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNN
NNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNN
NNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNN
NNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNN
NNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNN
NNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNN
NNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNN
NNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNN
NNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNN
NNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNN
NNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNN
NNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNN
NNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNN
NNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNN
NNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNN
NNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNN
NNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNN
NNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNN
NNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNN
NNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNAAGGAACTTGTTCCTGGTGATATTGTGGAGTTG
AGGGTAGGAGATAAGGTGCCTGCTGATATGCGGGTTTTGAGTTTGGTCAGCTCCACGGTGAGGGTTGAGCAAGGTTCTTTGACGGGAGAAAGTGAAGCTG
TGAGCAAGACTGTTAAAACTGTTGCTGAGCATACAGATATTCAGGGGAAAAAATGTATGCTTTTTGCCGGAACCACGGTGGTGAATGGTAATTGCATGTG
TTTGGTCACTGGGACTGGAATGAACACTGAGATAGGTAAGGTGCATTCACAAATTCATGAAGCCTCCCAACACGAGGAAGATACCCCGTTGAAGAAGAAG
TTGAATGAGTTTGGAGAGGCTCTAACCATGATTATTGGCGTTATTTGTGCATTGGTTTGGCTTATTAATGTCAAGTACTTCCTCAGTTGGGAATACGTTG
ATGGCTGGCCGAGAAACTTCAAGTTCTCATTTGAGAAGTGCACCTATTACTTCGAGATTGCTGTGGCATTGGCAGTAGCTGCAATACCTGAAGGATTACC
AGCAGTCATTACAACTTGTTTGGCACTTGGAACTCGGAAAATGGCTCAGAAAAATGCTCTTGTCAGGAAGCTGCCAAGTGTTGAAACTCTTGGTTGTACC
ACTGTCATTTGCTCTGATAAGACAGGTACCCTCACAACCAATCAGATGGCTGTATCAAAGCTTGTGGCTATGGGGTCCATGGCTGGAAATCTGAGATCAT
TTAATGTGGAGGGCACAACTTACAATCCCTGTGATGGTAAAATTGAAGATTGGCCAGTTGGTCGAATAGATTCTAACCTTCAGATGATCGCAAAGATTTC
TGCCATTTGTAATGATGCTGGTGTGGAACAATCAGGACAGCAATATATTTCTACAGGAATGCCTACAGAGGCTGCACTAAAGGTTTTGGTTGAGAAAATG
GGGTTTCCTGGAGGAGTCAATAATGAATCTTCTTCTGTTAGTGACGATATTTTACGTTGTTCTAGCCTATTGAATAAGATGGAACAGCGATTTGCAACTC
TAGAATTTGACCGAGACAGAAAATCAATGGGTGTCATTGTCAATTCTAGCTCCGGTAGAAAGTTGCTATTCGTGAAGGGTGCTGTGGAGAACGTGTTGGA
GAGAAGTACGCATATTCAATTGCTTGATGGATCTATTGTAGAACTAGACCAATACTCGAGGGATCATATACTACAGAGCCTTCATGACATGTCAACAACT
GCATTACGATGCCTTGGATTTGCATACAAAGAGGATCTTCCAGAGTTTGACACATACAATGGTGATGAAGACCATCCAGCTCATCAGCTGCTACTTAATC
CAGCTAATTATTCCAACATCGAGAGTAAACTTGTGTTTGTCGGTTTGGCTGGGCTAAGGGACCCACCAAGGAAAGAAGTTCCTCAAGCAATTGAAGACTG
CAGGGCTGCCGGAATCAGAGTTATGGTTATTACTGGAGACAACAAAAACACCGCAGAGGCAATTTGCCGTGAAATTGGTGTCTTTGGACGTTATGATGAT
ATTAGTTCGAGAAGCTTTACTGGCAGAGATTTGATGGACCATCCCAACAAGAAGGAGGTTTTGAGACAGAGCGGAGGCCTATTATTCTCTCGAGCAGAAC
CGAGACACAAGCAAGAAATAGTGAGGTTATTGAAGGAGGAAGGAGAGGTGGTTGCAATGACTGGAGATGGGGTGAATGATGCACCTGCTTTGAAGCTGGC
TGACATCGGGATCGCAATGGGCATTTCCGGGACAGAGGTGGCAAAGGAAGCTTCAGATATGGTGTTGGCGGATGACAATTTCAGTACCATTGTTGCTGCT
GTGGGTGAAGGCCGGTCCATTTACAATAACATGAAGGCATTTATCAGGTACATGATATCATCAAACATGGGTGAGGTTGCATCCATATTCTTGACAGCGG
CTTTGGGTATCCCGGAGGGGATGATTCCGGTCCAACTATTATGGGTTAATCTCGTCACTGACGGGCCACCCGCGACAGCTTTAGGATTCAACCCGGCTGA
CAAGGATATCATGAAGAAGCCTCCCAGAAGAAGCAATGATTCTTTGATCACCGCCTGGATATTATTCCGCTACCTGGTGATTGGTCTCTATGTCGGAATA
GCAACCGTCGGAGTATTCGTGATATGGTACACTCACAGCTCATTCATGGGCATCGACCTGAGCGGAGACGGCCACACTCTGGTCACCTACTCCCAGCTCG
TCAGCTGGGATAAATGCCAATCGTGGAACAACTTCACGGTTTCGCCCTTCACAGCTGGGGCTCAGACCATCAAGTTCGATTCGAACCCGTGCGAATACTT
CCGGTCCGGTAAGATCAAGGCTTCGACACTATCACTCTCCGTGCTTGTGGCTATCGAGATGTTCAACTCGCTGAACGCTCTTTCCGAGGACGGAAGTCTT
CTGACAATGCCTCCGTGGGTGAATCCCTTCCTACTGCTGGCGATGGCGGTATCGTTCGGGATGCACTTTTTGATCCTGTACGTGCCGATCCTCGCCCAGA
TTTTCGGAATCGTGCCGCTCAGTTTGAACGAGTGGCTGTTGGTTGTGGCCGTTGCTTTCCCTGTCATTCTGATTGATGAAGTGCTCAAGTTTGTAGGAAG
GTTGACTAGCGAGTCGAGGCATTCTCGCACGAGCTTGGCTAAGTCGAAATCAGACTGA
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
AA sequence
|
>Lus10023328 pacid=23180914 polypeptide=Lus10023328 locus=Lus10023328.g ID=Lus10023328.BGIv1.0 annot-version=v1.0
MGRGGEDSGKSEKLGVESENRGVFPAWAKDVKECEAEYEVDSHYGLSVAEVAKRLDIHGYNELEKHEGTSIWELIVEQFKDTLVRILLAAAVISFVLAWY
DGKEGGEMEITAFVEPLVIFLILIVNAIVGIWQESNAEKALEALKEIQSETAAVLRDGKKISSLPAKELVPGDIVELRVGDKVPADMRVLSLVSSTVRVE
QGSLTGESEAVSKTVKTVAEHTDIQGKKCMLFAGTTVVNGNCMCLVTGTGMNTEIGKVHSQIHEASQHEEDTPLKKKLNEFGEALTMIIGVICALVWLIN
VKYFLSWEYVDGWPRNFKFSFEKCTYYFEIAVALAVAAIPEGLPAVITTCLALGTRKMAQKNALVRKLPSVETLGCTTVICSDKTGTLTTNQMAVSKLVA
MGSMAGNLRSFNVEGTTYNPCDGKIEDWPVGRIDSNLQMIAKISAICNDAGVEQSGQQYISTGMPTEAXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXKELVPGDIVEL
RVGDKVPADMRVLSLVSSTVRVEQGSLTGESEAVSKTVKTVAEHTDIQGKKCMLFAGTTVVNGNCMCLVTGTGMNTEIGKVHSQIHEASQHEEDTPLKKK
LNEFGEALTMIIGVICALVWLINVKYFLSWEYVDGWPRNFKFSFEKCTYYFEIAVALAVAAIPEGLPAVITTCLALGTRKMAQKNALVRKLPSVETLGCT
TVICSDKTGTLTTNQMAVSKLVAMGSMAGNLRSFNVEGTTYNPCDGKIEDWPVGRIDSNLQMIAKISAICNDAGVEQSGQQYISTGMPTEAALKVLVEKM
GFPGGVNNESSSVSDDILRCSSLLNKMEQRFATLEFDRDRKSMGVIVNSSSGRKLLFVKGAVENVLERSTHIQLLDGSIVELDQYSRDHILQSLHDMSTT
ALRCLGFAYKEDLPEFDTYNGDEDHPAHQLLLNPANYSNIESKLVFVGLAGLRDPPRKEVPQAIEDCRAAGIRVMVITGDNKNTAEAICREIGVFGRYDD
ISSRSFTGRDLMDHPNKKEVLRQSGGLLFSRAEPRHKQEIVRLLKEEGEVVAMTGDGVNDAPALKLADIGIAMGISGTEVAKEASDMVLADDNFSTIVAA
VGEGRSIYNNMKAFIRYMISSNMGEVASIFLTAALGIPEGMIPVQLLWVNLVTDGPPATALGFNPADKDIMKKPPRRSNDSLITAWILFRYLVIGLYVGI
ATVGVFVIWYTHSSFMGIDLSGDGHTLVTYSQLVSWDKCQSWNNFTVSPFTAGAQTIKFDSNPCEYFRSGKIKASTLSLSVLVAIEMFNSLNALSEDGSL
LTMPPWVNPFLLLAMAVSFGMHFLILYVPILAQIFGIVPLSLNEWLLVVAVAFPVILIDEVLKFVGRLTSESRHSRTSLAKSKSD
|
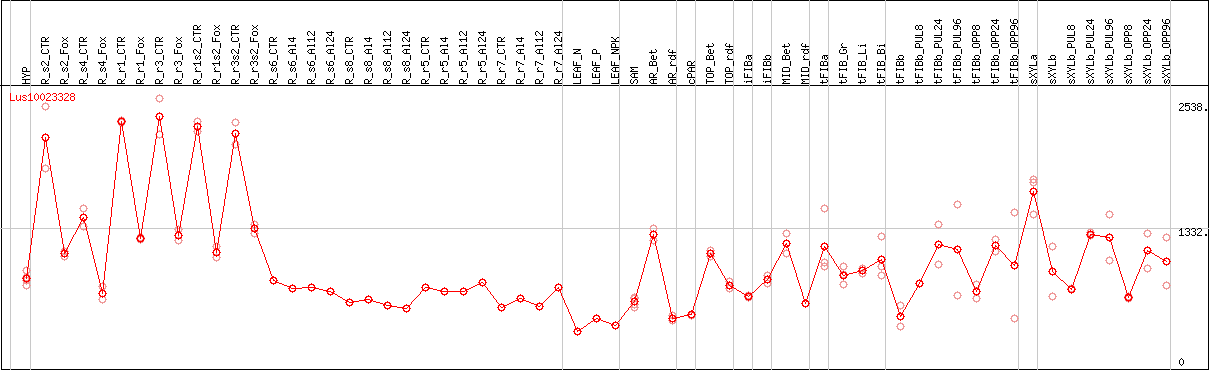
DESeq2's median of ratios [FLAX]
Coexpressed genes
Lus10023328 coexpression network
*The number of genes in the network is adjusted within 50 genes.*Gene name represents symbol(s) of closest Arabidopsis gene if symbol(s) for the gene itself doesn't exist.
*Circle diameter represents the number of connection with other genes within this network.
*Color for gene name represents subnetwork based on the result of network clustering.