Lus10032911 [FLAX]

| External link |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Symbol | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Arabidopsis homologues
|
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Paralogs
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Poplar homologues |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
| PFAM info |
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Representative CDS sequence |
>Lus10032911 pacid=23160347 polypeptide=Lus10032911 locus=Lus10032911.g ID=Lus10032911.BGIv1.0 annot-version=v1.0
ATGGAGGACGACGAACAGCAACAACAGCCGGCCAAGGTGGTGGAGCTGCAAGAGAAGAAGAACAAGGACGTCGGGAAATTCGACGATGGTGATTTGAAGA
AGGAAGGCGCGACGATCAAAACAGTGTCGTTTCGGGAGCTGCTTAGGTACGCTGACGGGTTCGACTGGATGCTGATGGGGTTAGGGACGCTGGGTTCGGT
AGTACACGGGATGGCTCAGCCGGTTGGGTATCTGTTGCTTGGGAAAGCTCTCAATGCATTCGGAAGTAACATTAACGATGACGTTGCTATGGTCAGGGCC
TTGGACAAGGTTGTGCCTTTCGTTTGGTACATGGCCATAGCCACCTTCCCTGCTGGAATACTTGAAATTGGGTGTTGGATGTACTCGAGTGAAAGGCAAC
TAGCGAGATGGAGGATGGAGTACTTGAAAGCTGTGCTTGATCAAGAAGTTGGAGCTTTCGACACCGAATTAACTACCGGGAAGATTATCACTGGTGTTAC
GAACCACATGACTATCATTCAAGATGCTATCGGAGAAAAGCTGGGACACTTCCTATCAAGTTTTGCAACATTCTTCTGTGGAGTGCTGATCGCTGCAGTA
AGTTCCTGGGAAGTCTCCTTGCTGACTCTAATGGTTGTTCCAATGATCCTTGGCATCGGAGCCACCTACACCAAGAAAATGAATGCCATCTCTTCCTCCA
AAATGGTTTACCTTTCTGCTGCCACCACCATGGTCGAAGAGACGATTACCCAGATAAAGACAGTATTTGCCTTTGTTGGGGAGACAAGAGCCGTGAAGGG
ATTTTCAGAGTTCATAACTCAACAGCTTTCACTTAGCAAAGTAGAAGCCTTGACAAAAGGGATAGGAACTGGGATGTTTCAAGCAGTGACATTCTGCTCA
TGGGCTATCATCATCTGGGTTGGAGCTTTCGTTGTTACTTCTGGTAGATCCTCTGGTGGTGATGTCATTGCTGCTGTTATGAGCATCCTCTTCGGTGCCA
TATCCCTGACTTACGCTGCGCCAGATATGCAAGTTTTCAACCAAGCAATGGTGGCAGGAAGCGAAATCGTGCAAGTAATCGAAAGGAAACCGCTGATTAC
AAGTCGCGATTCGAAGCAGGCAAAGACGCTACACAAAGTCAAAGGTGACATTGAAGTACGCGATGTTCATTTCGCCTATCCGTCCAGACCGGACACAATG
GTTCTCAACGGATTCTCACTGCTCATTCCTGCTGGGAAAATGGTAGCTTTGGTTGGTAGCAGTGGATGTGGGAAAAGTACCATTATCTCACTTGTTGCAA
GGTTCTATGATCCATTAAGAGGGGATATCCTGATTGACAATCACAACATTAAAGACCTGGGACTTAGCTCTCTCAGGAGCAAGATTGGAGCAGTTTCCCA
GGAACCATCTCTATTTGCAGGCACCATCATGGATAACTTGAGAGTTGGAAACATGGAGGCTGAGGATCAACAGATTATAGAAGCAGCTAAGATGGCAAAT
GCTCACTCCTTTATCTCCCAGCTTCCAAACCAGTACTCAACTCAGGTGGGTCAAAGGGGAGTGCAACTATCAGGAGGACAGAAGCAGAGGATAGCTATAG
CTAGAGCGATTCTGAAGGACCCTCCGATACTTTTACTCGATGAGGCTACAAGTGCCCTCGATTCGGAATCGGAGAGGCTGGTTCAAGATGCATTGGAGAA
GGCAATGCAAGGAAGGACAGTTATATTGATTGCACACAGGATGTCAACCATAATCAATGCTGATATCATAGCAGTTGTGGAGAATGGACAAGTTTTGGAG
ACCGGAACTCATCACAGCTTGCTGGAGACCAACACCTTCTACAATAGTTTATGCACCATGCAGAATCTCAACCCAGATGATGCTGATTCAACTGTCAGGA
CTGAAGGATCAAAAGACACTGCAGATCCCATACAGCAGGAAGCATTGCCTGCAGACAACCAAGAACAAAGTGAAGTAGCCTACAAACCTTCAAGCCCACC
TCCAGTTCAAGAAATCAAGAAAGTAGCAAAGAAAAGACATAATTTCTTCAGAATCTGGTATGGGTTCGGAAAGACGGAAATGGTGCAGACTGCAGTGGGT
TCATTTGCAGCAGCATTCTCAGGAATATCAAAGCCCTTTTTTGGGTTCTACATTATTACTGTGGGAGTAGCATACTACCAAGGTCATGCAAAGCGTAAGG
TCGGGAAGTACTCAATCATCTTTTCCATGATTGGATTGATTTCCTTATTCAGCCATACCTTGCAACATTACCTCTTTGGAGTTGTTGGAGAGAGAGCCAT
GACCAATCTCAGAAGCGCTTTGTACTCAGGTGTGCTGAGAAATGAACTAGGTTGGTTCGAGAAGCCAGACAACACCGTCTCATCACTAACATCACGAATC
ATCCACGACACATCCACAGTAAAGATCATAATCTCAGACCGAATGTCGGGAATCGTGCAATGCGTCTCCTCCATACTGATAGCAACAGTGGTGAGCATGG
TGGTCGACTGGAGAATGGCACTAGTAGCATGGGCAGTAATGCCGTGCCATTTCATAGGAGGACTCATCCAAGCCAAGTCCGCCCAAGGATTCTCCGGCGA
CTCAGCAGCAACACACAGAGAACTCGTCTCCTTAACATCCGAATCCACATCAAACATAAGAACCGTGGCATCATTCTGCTACGAGCCGCACATTTTGGCC
AAAGCCAAATCAAGCCTCAAACATCCCATGAAAATGGTGAGGAACCAAAGCATCAAATTCGGGCTGATCCAAGGGGTATCACTCTGCCTGTGGAACATTG
CACACGCTGTTGCATTGTGGTACACAACACGTCTAGTCGAGAGACATCAGTCTAGTTTCAAAGACGGGATCCGCGCATACCAGATTTTCTCCCTCACTGT
GCCTTCCATCACCGAGCTATGGACACTGATTCCTGCTGTAGTGTCAGCTATGAATGTCTTGGCACCGGCATTCGAAACCCTCGATCGTAAGACCGAGATC
GAACCTGACGAACCAAAGGTAGCCGAATTCATCCTTAGGGAAGGAAGGATCGAGTTTCAAAACGTCAAATTCAACTATCCATTACGCCCCGAAGTAACAG
TTCTAAACAATTTTACCCTGCAAATCGAGCCAGGACTGAAAGTGGCTCTAGTAGGTCCAAGTGGAGCCGGGAAATCATCAGTCTTGGCTCTTCTGCTCAG
ATTCTACGATCCACTACAAGGAAACGTCATAATCGACGGGAAGAACATAAAAGAATGTAACCTAAGGTTGTTGAGGAGACAAATTGGACTCGTCCAGCAG
GAACCCTTACTGTTCAGCTGTTCAATTAGGGATAACATCAAGTACGGAAAAGAAGAAGCAAGTGAGTCAGAAGTTGTTCAAGTGGCGAGGGAAGCAAACA
TACATGGATTCGTGAGCAATTTGCCCGACGGGTACGACACGGTGGTTGGGGACAGAGGCTGCCAGCTTTCCGGAGGGCAGAAACAGAGGATCGCCATTGC
TAGAACTTTGCTAAAGAGGCCGACGATTCTGCTGTTGGATGAGGCGACGAGCGCGTTGGACACTGAATCCGAAAGGTCGATAGTGAATGCTCTGGAATCG
ATCAGTGAGAACAACGACGGCGGCGGTGGGTCGTTGTCGGCTAGGATGACGCAGATTACGGTTGCGCATAGGCTTTCGACGATAAGGAAATCAGATAGTA
TAGTGGTGATGGATAGAGGTGAGATTGTGGAGATGGGTACTCATTCCAGTCTTTTGGCGTCCAGTGGTGGAGTGTATTCCAGATTGTACGAGCTGCAGAG
CTTGGCTTAG
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
AA sequence
|
>Lus10032911 pacid=23160347 polypeptide=Lus10032911 locus=Lus10032911.g ID=Lus10032911.BGIv1.0 annot-version=v1.0
MEDDEQQQQPAKVVELQEKKNKDVGKFDDGDLKKEGATIKTVSFRELLRYADGFDWMLMGLGTLGSVVHGMAQPVGYLLLGKALNAFGSNINDDVAMVRA
LDKVVPFVWYMAIATFPAGILEIGCWMYSSERQLARWRMEYLKAVLDQEVGAFDTELTTGKIITGVTNHMTIIQDAIGEKLGHFLSSFATFFCGVLIAAV
SSWEVSLLTLMVVPMILGIGATYTKKMNAISSSKMVYLSAATTMVEETITQIKTVFAFVGETRAVKGFSEFITQQLSLSKVEALTKGIGTGMFQAVTFCS
WAIIIWVGAFVVTSGRSSGGDVIAAVMSILFGAISLTYAAPDMQVFNQAMVAGSEIVQVIERKPLITSRDSKQAKTLHKVKGDIEVRDVHFAYPSRPDTM
VLNGFSLLIPAGKMVALVGSSGCGKSTIISLVARFYDPLRGDILIDNHNIKDLGLSSLRSKIGAVSQEPSLFAGTIMDNLRVGNMEAEDQQIIEAAKMAN
AHSFISQLPNQYSTQVGQRGVQLSGGQKQRIAIARAILKDPPILLLDEATSALDSESERLVQDALEKAMQGRTVILIAHRMSTIINADIIAVVENGQVLE
TGTHHSLLETNTFYNSLCTMQNLNPDDADSTVRTEGSKDTADPIQQEALPADNQEQSEVAYKPSSPPPVQEIKKVAKKRHNFFRIWYGFGKTEMVQTAVG
SFAAAFSGISKPFFGFYIITVGVAYYQGHAKRKVGKYSIIFSMIGLISLFSHTLQHYLFGVVGERAMTNLRSALYSGVLRNELGWFEKPDNTVSSLTSRI
IHDTSTVKIIISDRMSGIVQCVSSILIATVVSMVVDWRMALVAWAVMPCHFIGGLIQAKSAQGFSGDSAATHRELVSLTSESTSNIRTVASFCYEPHILA
KAKSSLKHPMKMVRNQSIKFGLIQGVSLCLWNIAHAVALWYTTRLVERHQSSFKDGIRAYQIFSLTVPSITELWTLIPAVVSAMNVLAPAFETLDRKTEI
EPDEPKVAEFILREGRIEFQNVKFNYPLRPEVTVLNNFTLQIEPGLKVALVGPSGAGKSSVLALLLRFYDPLQGNVIIDGKNIKECNLRLLRRQIGLVQQ
EPLLFSCSIRDNIKYGKEEASESEVVQVAREANIHGFVSNLPDGYDTVVGDRGCQLSGGQKQRIAIARTLLKRPTILLLDEATSALDTESERSIVNALES
ISENNDGGGGSLSARMTQITVAHRLSTIRKSDSIVVMDRGEIVEMGTHSSLLASSGGVYSRLYELQSLA
|
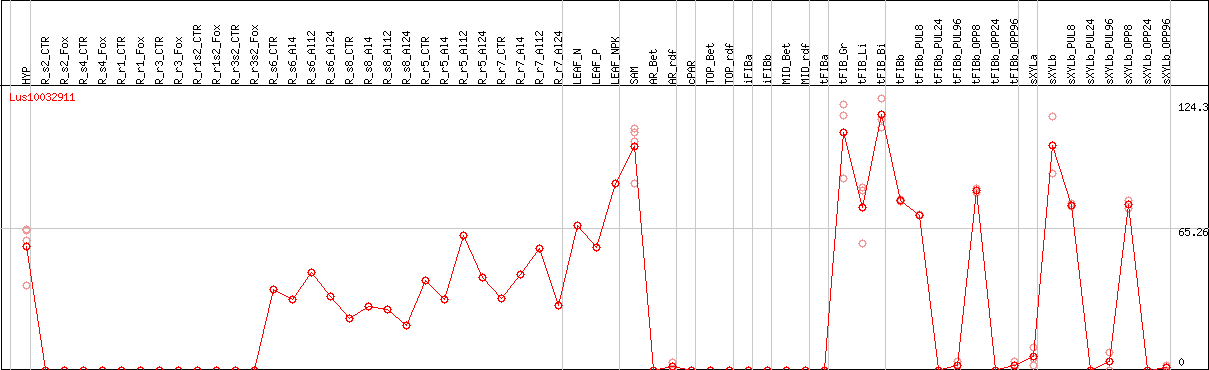
DESeq2's median of ratios [FLAX]
Coexpressed genes
Lus10032911 coexpression network
*The number of genes in the network is adjusted within 50 genes.*Gene name represents symbol(s) of closest Arabidopsis gene if symbol(s) for the gene itself doesn't exist.
*Circle diameter represents the number of connection with other genes within this network.
*Color for gene name represents subnetwork based on the result of network clustering.