Lus10033440 [FLAX]

| External link |
|
|||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Symbol | ||||||||||||||||||||||||||||||||||||||||||||||
|
Arabidopsis homologues
|
| |||||||||||||||||||||||||||||||||||||||||||||
|
Paralogs
|
|
|||||||||||||||||||||||||||||||||||||||||||||
|
Poplar homologues |
|
|||||||||||||||||||||||||||||||||||||||||||||
| PFAM info |
| |||||||||||||||||||||||||||||||||||||||||||||
|
Representative CDS sequence |
>Lus10033440 pacid=23172060 polypeptide=Lus10033440 locus=Lus10033440.g ID=Lus10033440.BGIv1.0 annot-version=v1.0
ATGGCGTCGGTTTATATTCCTGTGCAGAACTCCGAGGAGGAGGTAAGAGTGGTCTTGGATCAGCTGCCGCGGGATGCCTCTGATATTATCGACATTCTAA
AGGCCGAGCAAGCTCCTCTCAATTTGTGGCTTATTATTGCGAGAGAATACTTTAAACAAGGGAAGGTTGACCAGTTCCGGCAGATATTGGAAGAAGGATC
AAGTCCTGATATTGATGAATATTATGCCGATGTTAGATATGAGAGGATCGCTATCCTCAATGCTCTTGGCGCTTACAATTGCTACCTTGGAAAGATTGAG
ACAAGACAAAAAGAAAGGGAGGAATATTTCATACAGGCTACCAGGCATTATAACAAAGCTTCAAGGATTGACATGCATGAACCTTCTACTTGGATTGGGA
AAGGTCAGCTTCTACTGGTCAAGGGTGAGCTAGAACAGGCTTCTTCTGCTTTTAGGATTGTATTAGATGGAGATCGTGATAATGTACCAGCTCTATTGGG
TCAGGCTTGTGTTGAGTTTAATCGCGGGAGTTACAGTGAATCACTGTCACTGTATAGGAGAGTATTACGAATATTTCCTGATTGTCCTGGACCTGTCAGG
CTTGGTATCGGTCAGTGTCAATATAAGATGGGCCGCTTTGAAAAAGCCCGAAAGGCATTTGAACGGGTTGTACAGGCAAATCCAGACAATGTTGAGGCTC
TAGTTGCACTAGCAATTTTGGACTTGCAAACAAATGAAGCTGCTCATACAAGGAACGGGATGGAAAGAATGAAACAAGCTTTTGAGATTTACCCTTACTG
TCCTATGGCTCTTAATTACCTAGCCAATCACTTTTTCTTCACTGGTCAGCACTTCTTAGTTGAGCAACTGATGGAAACTGCACTGACTGTCACCAATCAT
GGGCCTACAAAGTCACATTCGTACTATAATTTAGCTCGTTGTTACCATAGCAAGGGCGATTATAAAGCAGCCTTAAGATATTACCATGCTTCAGTCCAGG
AAATAACTAAGCCCAGTGAATTTGTGTTCCCGTATTTTGGTTTGGGTCAAGTACAACTAAAGTTAGGAGATACAAAGAGCGCTGTGTCAAATTTTGAAAT
GGTTTTGGAGGTTTACCCGGATAATTGTGATACTTTGAAAGTTCTCGGACATGTATATGTTGGGCAGCCCGAAAAAGCCAAGGACTTTTTGAAGAAGGCT
ACAAAAATTGATCCTCGTGACGCCCAGGCATTTCTTGATCTGGGGGAGTTGTTAATCACGTCTGATACTGCAGCTGCACTTGATTCATTCAAGATGGCAT
CCAAACTAATGAAGAAGCAAGACGTGCCAGTGGAAGTGCTGAATAACATTGGTGTCATCCATTTTGAAAGGGAAGAGCTTGAGGATGCTCTTGTAGCTTT
TAAAGAGGCACTAGGTGATGGTTTATGGCTCAGTTTCCTTGATGGTACAAGAAAGATCACTTCATCTGTTCTTCAGTACAAGGATGTGCAACTGTTTCAC
CAACTTGAGGAAGATGGCGTTAATGTGGAACTACCATGGAATAAAGTTACACCTTTGTTTAACCTGGCCAGATTACTGGAGCAGTTGCACAAAACCGAAA
CTGCTGCCATCTTTTACCGTCTGATATTGTTCAAGTATCCAGATTATGTAGATGGATATCTCCGGCTTGCTGCAATTGCAACATCTAGAAATAATCACCA
CTTAAGCATTGAACTGGTAAATGAGGCTCTGAAGTTGAATAACAAGTGCCCTAATGCATTGTCAATGCTCGGTGAATTGGAGCTAAAAAATGATGATTGG
GTTAAGGCGAAAGAAACATTGCGTGCTGCTAGTGATGCAATGGATGGGAAAGATTCTTACGCTACACTTGCTCTGGGAAACTGGAACTATTTTGCTGCAT
TGCGTAATGAGAAAAGGAACCCTAAACTGGAATCAACTCACTTGGAGAAAGCCAAGGAATTGTACTCCAGAGGCCTGGGTCAGCACACATCTAACTTGTC
TGCAGTCCTGGTTCAGCACACATCTAACTTGTATGCAGCCAATGGAGCCGGAATAGTGTTGGCTGAAAAAGGGAACTTTGATGTAGCCAAAGATCTTTTC
ACACAGGTCCAGGAAGGTGCAAGTGGAAGTAGCTTTGTACAGTTGCCAGATGTTTGGATAAACTTGGCACATGTGTATTTTGCTCAGGGTAATAATGCCT
TGGCTATAAAAATGTACCAGAATTGCTTACGGAAATACTATCATAATACCGACTATCAAATTCTCCTCTATATGGCACGCACTTATTATGAAGCTGAACA
GTGGCAAGACTGCAAGAAAACTTTGTTGAGAGCAATACACTTAGCCCCTTCAAATTATACACTTAGGTTTGATACAGGCGTTGCAATGCAGAAGTTCTCT
GCTTCCACACTACAGAAGACAAAGAGGACGGTAGATGAGGTTCGGTCCACAGTTGATGAGCTGGAAAATGCTGTTCGTGTCTTTAGTCAGCTGTCTGCTG
GGGCCAACCTCCAGATCCATGGGTTTGATGAGAAGAAGATAAACACTCATGTCGAGTATTGCAAACATTTATTAGAGGCTGCCAAGGTTCACAGAGAAGC
TGCGGAGCGAGAAGAGCAGCAAAACAAGCAGAGGCAAGAAGTTGCTCGTCAGATGGCTTTAGCTGAAGAAGCCCGTCGCAAGGCCGAAGAACAAAGGAAA
GCTCAGATGGAGAGGAGGAAAATTGAGGATGAACGTAAACGGATCCGGCAACAAGAAGAGAACTTTCAGCGTGTCAAGGAACAATGGAAGAGTAGTTCAG
CTTCTAAGCGGAAGGATAGATTGGATATCATTGATGATGATGAGGAGGTTGGGCAGAGTGGAGGTGGGAGGAGGAGGAAGAAAGGTGGAAAGAGGAGAAA
GAAGGAGAAAACCTCAAAGTCACAATACGACAAGGAAGAAGGAGAAGCAGAGATGGATGATCATGAAGAGGGGGAGATGCATGAGAGTTATGGGCAGAAT
AGAAATGAGGCGGAAGATCAGGATCAGGATCAAAATCTTCTTGCTGCAGCTGGGCTTGAAGATTCTGATGCAGAGGATGAAGAGGCGGCAGCGACTGCAA
CAGCTGCGAGGAGGAGGCGGGCATTGTCAGAATCGGAGGACGACGAACCAATCCCTGTAAGAGAAGATTCTAATGACGTGCACGTGAGTGATGGAGAAGC
TGCCGCCAAGGATCATGGCGACGATGCTGGTCTTGATGGGGAGGATTAA
|
|||||||||||||||||||||||||||||||||||||||||||||
|
AA sequence
|
>Lus10033440 pacid=23172060 polypeptide=Lus10033440 locus=Lus10033440.g ID=Lus10033440.BGIv1.0 annot-version=v1.0
MASVYIPVQNSEEEVRVVLDQLPRDASDIIDILKAEQAPLNLWLIIAREYFKQGKVDQFRQILEEGSSPDIDEYYADVRYERIAILNALGAYNCYLGKIE
TRQKEREEYFIQATRHYNKASRIDMHEPSTWIGKGQLLLVKGELEQASSAFRIVLDGDRDNVPALLGQACVEFNRGSYSESLSLYRRVLRIFPDCPGPVR
LGIGQCQYKMGRFEKARKAFERVVQANPDNVEALVALAILDLQTNEAAHTRNGMERMKQAFEIYPYCPMALNYLANHFFFTGQHFLVEQLMETALTVTNH
GPTKSHSYYNLARCYHSKGDYKAALRYYHASVQEITKPSEFVFPYFGLGQVQLKLGDTKSAVSNFEMVLEVYPDNCDTLKVLGHVYVGQPEKAKDFLKKA
TKIDPRDAQAFLDLGELLITSDTAAALDSFKMASKLMKKQDVPVEVLNNIGVIHFEREELEDALVAFKEALGDGLWLSFLDGTRKITSSVLQYKDVQLFH
QLEEDGVNVELPWNKVTPLFNLARLLEQLHKTETAAIFYRLILFKYPDYVDGYLRLAAIATSRNNHHLSIELVNEALKLNNKCPNALSMLGELELKNDDW
VKAKETLRAASDAMDGKDSYATLALGNWNYFAALRNEKRNPKLESTHLEKAKELYSRGLGQHTSNLSAVLVQHTSNLYAANGAGIVLAEKGNFDVAKDLF
TQVQEGASGSSFVQLPDVWINLAHVYFAQGNNALAIKMYQNCLRKYYHNTDYQILLYMARTYYEAEQWQDCKKTLLRAIHLAPSNYTLRFDTGVAMQKFS
ASTLQKTKRTVDEVRSTVDELENAVRVFSQLSAGANLQIHGFDEKKINTHVEYCKHLLEAAKVHREAAEREEQQNKQRQEVARQMALAEEARRKAEEQRK
AQMERRKIEDERKRIRQQEENFQRVKEQWKSSSASKRKDRLDIIDDDEEVGQSGGGRRRKKGGKRRKKEKTSKSQYDKEEGEAEMDDHEEGEMHESYGQN
RNEAEDQDQDQNLLAAAGLEDSDAEDEEAAATATAARRRRALSESEDDEPIPVREDSNDVHVSDGEAAAKDHGDDAGLDGED
|
DESeq2's median of ratios [FLAX]
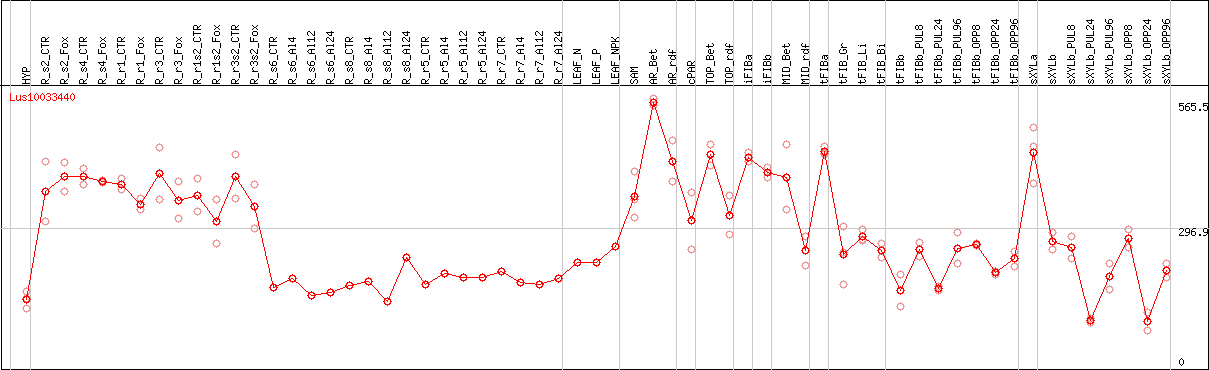
Coexpressed genes
Lus10033440 coexpression network
*The number of genes in the network is adjusted within 50 genes.*Gene name represents symbol(s) of closest Arabidopsis gene if symbol(s) for the gene itself doesn't exist.
*Circle diameter represents the number of connection with other genes within this network.
*Color for gene name represents subnetwork based on the result of network clustering.