Lus10035954 [FLAX]

| External link |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Symbol | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Arabidopsis homologues
|
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Paralogs
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Poplar homologues |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
| PFAM info |
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Representative CDS sequence |
>Lus10035954 pacid=23141157 polypeptide=Lus10035954 locus=Lus10035954.g ID=Lus10035954.BGIv1.0 annot-version=v1.0
ATGGAAGATCTTCAATTCAGCAACCGGGTCTCGGAAACGGTGCTCTCTGGGTCTTCCTCTTCTTGCTTTCCTCCGATTGGAAACAACGGTGATGCGGGTT
ACGGTCCGACAGAATCCGCTTTTGAAGACGCTGATGCTGGGAAATCTTTGGTCGATTCTATGATTTGCGACTCCAATTCAAGGCTCGTTCTTTCTGGGTT
TTCAAGATCGAATTGCTCAGAAACAGATGGAGTTTTCATGATCGTAAATAGTGGAAATGAGAGCTCAGTTGAAACAGAGTCCACTCTCAAATTTGTGGGC
GACTCTTATTACGAGGGAGGTACTGTTTTGCGGACAGATGAGGATATAGCTGATGCTGGGGATTTCCCATTCATCTACAAGTCTGCGAGGTTCGGGAACT
TCTGTTACAGATTTCATGGCCTTCCTTCAGGAGATTATTTCGTCGATCTCCACTTTGCTGAGATTATAAACACTAATGGACCTAAAGGAATACGAGTGTT
TGATGTATTCATACATGAAGACAAGGTCCTATCAGAATTTGATATTTTCTCTATCGTTGGAGCCAATAAGCCATTGCAATTGGTCGATGTGAGGGTTTCA
GTGAAGGAAGATGGAATACTTTTGTTGAGATTTGAAGGTCTTAGTGGGAGTCCAATGTTGAGTGCAATCTGCATCAGGAAAGCATCTGAAGTGACAGCTA
CTCAGCAGCAAAAAGAGTTCCTTAGATGCAATCATTGTGCTTCAGAGATGGAAGTTTCTTCAGCTCAGAAACGGCTTGTGCGAACTAAAGTAACGGATAA
GTATGAGAAAAGGATTCAAGACCTCACTGCTCTCTGCCAGCGTAAGACAAATGAATGCCATGAGGCTTGGATGTCACTTACTGCTGCAAATGAGCAGCTG
GAGAAAGTCCGCATGGAGCTTGATAACAAGACCTACCAGACCCGGTCTTTAGATCAAACTGTGGGCGAACAAGCTGACAATTTAAGGAATATCACCACCA
TGTATGGTCGAGATAAGAAGTCCTGGTCACAAGCGATCAACAACATGCAAGAGAAAATTAGGATTATGAAAGAGGAGCACATTAGGCTTTCTCGTGATGC
ACATGGTTGTATTGATTCCATACCCGAGCTGAATAACATGGTGTCTGGAGTTCAGGCATTAGTTGCACAATGTGAGGAACTAAAGTTGAAATATAGTGAA
GAACAAGCAAAGAGGAAGCAGTTATATAATCAAATACAAGAGACTAAAGGAAACATCCGAGTTTTTTGCCGTTGTCGGCCATTAAGTAAGGAAGAAGCAT
CAACTGGGTATGCAACAGTTGTTGACTTTGATGCCGCGAAGGATGGGGATCTTGGAGTTCTCACAGGCGGCTCCAACAAAAAGATTTTCAAATTTGACAG
GGTCTATACCCCTAGAGATGGTCAAGTTGACGTGTTTTCAGATGCCTCACCAATGGTGGTGTCGGTGCTGGATGGTTACAATGTATGCATATTTGCGTAT
GGACAAACAGGAACAGGAAAGACATTTACAATGGAGGGGCCTGAGCATAATAGGGGTGTCAATTATAGGACTCTTGAGCAATTGTTCACAGTCGCCCGAG
AAAGGAGTGATACTTTCACGTATAACATATCTGTCAGTGTCCTTGAAGTCTACAATGAACAAATTAGGGATCTGTTGACTACATCAACAACATCAAAGAA
GTTGGAGATAAAACAAACAGCTGAAGGATCACATCACGTTCCAGGGGTTGTAGAAGCAAAGGTTGATAACATCAAAGATGTTTGGAGTGTACTGCAGGCT
GGAAGCAATGCCAGGGCTGTTGGTTCAAACAATGTCAACGAACACAGCAGCCGGTCTCATTGTATGCTGTGCATCATGGTAAAAACAAAAAATCTGATGA
ACGGCGAGTGCACGAAAAGCAAACTTTGGCTTGTAGACTTGGCGGGAAGTGAACGATTGGCAAAAACTGATGCACAAGGTGAAAGACTGAAGGAAGCACA
AAACATCAACAAATCGCTCTCTGCTCTTGGAGATGTTATATATGCTTTGGCAACTAAGAGCAGTCACATTCCATACAGGAATTCTAAGTTGACACATTTA
CTTCAGGACTCTTTAGGAGGCGACTCAAAAACCTTGATGTTCGTTCAAATTAGCCCTTCTGAGCATGACTTGAGCGAGACTCTGAGCTCACTGAATTTCG
CAACTCGAGTTCGAGGGGTTGAGCTGGGTCCTCCAAAGAAGCAACTTGATACAAGTGAGATCCAGAGATTGAAAACACTGCTTGAAAAAACAAGGCAAGA
ATCTAGATCGAAAGATGAATCACTACGAAAACTTGAAGAGAATTTACAGAACCTGGAGAATAAGACCAGAAGCAAAGACCATGTGTACAAAAGCCAGTTA
GAGAAGATACGAGAACTCGAGGGGCAGCTTGAACAGAAAGGTAATTTGCATGGCCAATCAGAGAAGTACGTTTCCCAACTTTCAGAAAGACTGAAAGGGA
GAGAAGAAATATGTAACGAATTGCAGCAAAAGGTCAAGGAATTGGAGAGCAAGCTGAAACAAAGAGAGCAATCAGACTCTGAAACTTTTCAACATAAGGT
TAGGGAAATGGAGAAGAAAATGAATGAGCAAGCCCAAGAGTCGGAGTCTCAATCCTTCACTCTGCAACAAAAGATTAAGGAGCTAGAAAGCAGACTGCAT
GAACAGAATCAAAATTCGGAGGCAGTGGCGCTTCATGTAAAGATTAAGGAGCTAGAAGAAAAGCTGAGGGAGCATGAACAGAAGTTACAGAATAGGCGAG
TTAGCAACGCAGTGGATGGCATTAGGGCTAGTCCGACAGGAAAAAATACTTGTGCTAAAGATGATGAACGGATGACAGATGTTGAGGCTAACATCTTAAA
GTGTTCAAACTCAATAAACCGTCCCTCGGATGTCAAAGGGTACTCGACGGCAAAGGCTGCTGGTGATGAGGCCCGAAAGAAAAGGCATTCCAGAAATGGA
GAAACAGAGAATTGTAATACGCAAGCATGCTTCAATGATTACAGAGGTAGGAAATCAGACCCTCCAAAGATAGCTAGAGTTACCAGTCAAGCGACCTTGA
CCCACAAGAGAATCAACAGAGAAACAACAAGACTTGCAATCAAGGACAGGGATCCAAAGAAAAGGACTTGGTGCTAG
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
AA sequence
|
>Lus10035954 pacid=23141157 polypeptide=Lus10035954 locus=Lus10035954.g ID=Lus10035954.BGIv1.0 annot-version=v1.0
MEDLQFSNRVSETVLSGSSSSCFPPIGNNGDAGYGPTESAFEDADAGKSLVDSMICDSNSRLVLSGFSRSNCSETDGVFMIVNSGNESSVETESTLKFVG
DSYYEGGTVLRTDEDIADAGDFPFIYKSARFGNFCYRFHGLPSGDYFVDLHFAEIINTNGPKGIRVFDVFIHEDKVLSEFDIFSIVGANKPLQLVDVRVS
VKEDGILLLRFEGLSGSPMLSAICIRKASEVTATQQQKEFLRCNHCASEMEVSSAQKRLVRTKVTDKYEKRIQDLTALCQRKTNECHEAWMSLTAANEQL
EKVRMELDNKTYQTRSLDQTVGEQADNLRNITTMYGRDKKSWSQAINNMQEKIRIMKEEHIRLSRDAHGCIDSIPELNNMVSGVQALVAQCEELKLKYSE
EQAKRKQLYNQIQETKGNIRVFCRCRPLSKEEASTGYATVVDFDAAKDGDLGVLTGGSNKKIFKFDRVYTPRDGQVDVFSDASPMVVSVLDGYNVCIFAY
GQTGTGKTFTMEGPEHNRGVNYRTLEQLFTVARERSDTFTYNISVSVLEVYNEQIRDLLTTSTTSKKLEIKQTAEGSHHVPGVVEAKVDNIKDVWSVLQA
GSNARAVGSNNVNEHSSRSHCMLCIMVKTKNLMNGECTKSKLWLVDLAGSERLAKTDAQGERLKEAQNINKSLSALGDVIYALATKSSHIPYRNSKLTHL
LQDSLGGDSKTLMFVQISPSEHDLSETLSSLNFATRVRGVELGPPKKQLDTSEIQRLKTLLEKTRQESRSKDESLRKLEENLQNLENKTRSKDHVYKSQL
EKIRELEGQLEQKGNLHGQSEKYVSQLSERLKGREEICNELQQKVKELESKLKQREQSDSETFQHKVREMEKKMNEQAQESESQSFTLQQKIKELESRLH
EQNQNSEAVALHVKIKELEEKLREHEQKLQNRRVSNAVDGIRASPTGKNTCAKDDERMTDVEANILKCSNSINRPSDVKGYSTAKAAGDEARKKRHSRNG
ETENCNTQACFNDYRGRKSDPPKIARVTSQATLTHKRINRETTRLAIKDRDPKKRTWC
|
DESeq2's median of ratios [FLAX]
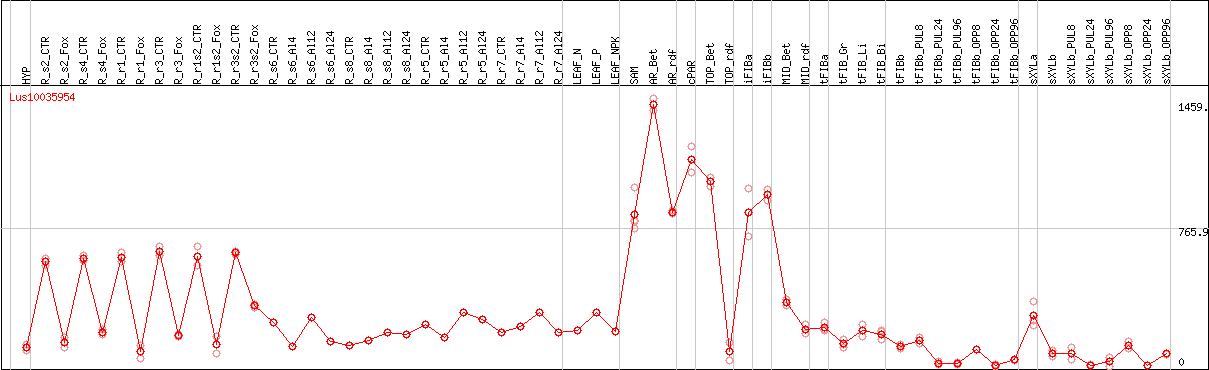
Coexpressed genes
Lus10035954 coexpression network
*The number of genes in the network is adjusted within 50 genes.*Gene name represents symbol(s) of closest Arabidopsis gene if symbol(s) for the gene itself doesn't exist.
*Circle diameter represents the number of connection with other genes within this network.
*Color for gene name represents subnetwork based on the result of network clustering.