Lus10038008 [FLAX]

| External link |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Symbol | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Arabidopsis homologues
|
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Paralogs
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Poplar homologues |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
| PFAM info |
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Representative CDS sequence |
>Lus10038008 pacid=23163900 polypeptide=Lus10038008 locus=Lus10038008.g ID=Lus10038008.BGIv1.0 annot-version=v1.0
ATGGCTTCGAAATCGTTCAAAGTGAGCAGATCAAATTTGTCAATCAGTTCAGATGCGACGGACTCACAGAAGCCTCCCCTGCCGCCGACGGTGACCTTCG
GACGGAGAACATCTTCCGCCCGCTACTCCAGGGACGACCTGGACAGTGAAATTGGCAGCGTCGACTTCATGAACTACACCGTCCACATCCCTCCGACGCC
GGACAACCAGCCTAGCACTGACCCTTCCATCTCCCAGAAGGTGGAGGAGCAGTACGTGTCCAGCTCCCTCTTCACCGGCGGCTTCAACAGCGTCACCCGT
GCACATCTCATGGACAAGGTTACCGATTCCGAACAGTCTAGCCACCCTCAGATGGCCGGAGCCAAGGGATCCTGCTGCGCCATCCCTGGCTGCGACGCCA
ACGTAATGATCGACCAGCGCGGCGACGATATACTCCCTTGCGACTGTGATTTTAAGATCTGCCGTGACTGCTACGTCGACGCCGTCAAAGCCGGAGGTGC
AATCTGCCCCGGCTGCAAGGATCCTTACAAGAATACTGAACTCGACGAGGTCGCCGTGGACGACGATAATTCCAATTCCCGCCCTCTCCCGCTCCCTCCC
CCGGTCGCCACCATGTCGAAGATGGAGAGACGCCTTTCCCTTATGAAATCTACCAAGTCCGGCCTTATGAGGAGCCAGACTGGCGACTTCGACCACAACA
GGTGGCTCTTTGAGACCAGGGGAACTTACGGCTACGGCAACGCTATCTGGACCAACGATGGTGGCTTTGGCGGCTGCAAGGATGACTCAGCTGCTGAGCC
TAAGGAATTCATGTCCAAGCCATGGAGGCCTCTCACCCGTAAACTGAAGATTCCAGCTGCCGTTATCAGCCCATACAGGCTTCTTGTGTTCATTCGAGTC
ATCGCTCTTGGCTTGTTTTTGTCATGGAGGGTACAAAATCCCAACAAGGAGGCTATGTGGCTGTGGGGGATGTCAGTAGTCTGCGAGCTTTGGTTTGCGT
TTTCTTGGCTTCTTGATCAACTACCAAAGCTGTGTCCAATAAACCGTGCAACTGATCTGAATGTGTTGAAGGATAAGTTCGAGACCCCCACCTTACGTAA
TCCAACAGGAAAGTCCGATCTTCCGGGAGTAGATGTATTCGTCTCCACTGCGGATCCTGAGAAAGAACCGCCTCTTGTTACTGCAAACACCATTTTATCA
ATCTTAGCAGCTGACTACCCTGTTGAAAAGCTTGCATGTTACGTCTCTGATGACGGTGGTGCACTTCTAACCTTTGAGGCCATGGCTGAAGCTGCAAGTT
TTGCTAACATTTGGGTCCCCTTCTGCCGTAAACATGATATAGAGCCTAGGAATCCAGAGTCTTACTTTAGCCTGAAGAGAGATCCCTACAAGAACAAAGT
GAAGGCAGACTTTGTCAAGGATCGCAGGCGTCTAAAGCGGGAGTATGATGAGTTCAAGGTTCGAATTAATGGTTTGCCTGATTCCATTCGACGACGATCT
GATGCATATCATACAAGGGAAGAAATCAAAGCATTGAAGCTTCAGAGGCAGAACAGGGTGGTTGAAGTTGAACCTGTTGAGACTGTGAAGATTCCCAAGG
CTACATGGATGGCTGATGGTACCCACTGGCCTGGTACTTGGATGAATTCTGTCCCTGATCACTCCAAAGGAGACCATGCTGGGATTATCCAGGTGATGCT
GAAACCACCCAGCGACGAACCACTACACGGAAGCTCCGATGAAACCAAGACCTTGGACCTTACCGATGTCGATATACGTCTCCCACTCCTTGTCTACGTT
TCCCGCGAGAAGCGTCCTGGATATGATCACAACAAAAAGGCAGGAGCAATGAACGCTCTGGTTCGCGCATCAGCAATCATGTCCAACGGTCCATTCATCC
TCAACCTTGACTGCGACCACTACATCTACAACTCACTAGCTCTTCGAGAAGGCATGTGCTTCATGATGGACCGAGGTGGCGACCGTCTCTGCTACGTCCA
GTTCCCCCAGAGATTCGAAGGCATCGACCCTTCTGACCGATACGCAAATCACAACACCGTCTTCTTCGACGTCAACATGCGTGCTCTCGACGGTCTAATG
GGACCCGTCTATGTCGGAACCGGATGCCTCTTCAGAAGAATCGCTCTCTATGGCTTCGACCCTCCTCGAGCCAAAGAGGATAACCCAGGATGCTGTGGCA
GGTGGCTCTCCTTTCCCAGCTGCTTCTCCTTCTCTAGCCGCAAGAAGAAGCATACGCCGGAAGAGAACAAGTCCTTAAGAATGGAGGATTCCGACGATGA
CGTAGAGATCATGAACATGAACATGTCCTTCCTTCCCAAGAAGTTCGGCAACTCTACTTTCCTCATCGACTCAATCCCAGTAGCAGAATTCCAAGGCCGT
CCACTTGCAGACCATCCCGCCGTAAAAAACGGCCGTCCACCGGGAGCTCTCACCATCCCGCGAGATCTCCTTGATGCATCAACAGTTGCAGAAGCAATCA
GCGTCATATCCTGCTGGTACGAAGAGAAGACCGAGTGGGGTCAACGAATCGGATGGATCTACGGCTCCGTCACGGAAGACGTTGTAACTGGTTACAGAAT
GCACAACAGAGGATGGAAATCTGTCTACTGCGTCACCAAACGTGACGCCTTCCGTGGAACTGCACCCATAAACTTAACGGACAGACTCCACCAGGTGCTT
CGTTGGGCAACAGGCTCAGTCGAAATCTTCTTCTCCAGAAACAACGCCTTACTCGCCAGTCCAAGAATGAAGCTCCTTCAAAGAATAGCATACTTAAACG
TCGGAATCTATCCATTCACCTCGTTCTTCCTCATCGTCTACTGCTTCCTCCCGGCGTTGTCATTATTCTCAGGACAGTTCATCGTGTCAACTCTCAACGT
GACTTTCTTAGCGTACTTACTCATCATAACGGTGACACTATGCATGCTGGCGGTGCTTGAGATAAAATGGTCGGGGATTGAGTTGGAGGAATGGTGGAGG
AACGAGCAGTTCTGGTTAATCGGCGGGACAAGCGCTCATCTTGCGGCGGTGTTGCAAGGTTTGCTTAAAGTGGTGGCGGGGATTGAGATATCGTTCACTC
TGACGTCGAAGTCGGGAGGGGATGACGTGGACGACGAGTTTGCTGATCTGTACATAGTGAAGTGGACGAGTTTGATGATACCGCCGATAGTGTGA
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
AA sequence
|
>Lus10038008 pacid=23163900 polypeptide=Lus10038008 locus=Lus10038008.g ID=Lus10038008.BGIv1.0 annot-version=v1.0
MASKSFKVSRSNLSISSDATDSQKPPLPPTVTFGRRTSSARYSRDDLDSEIGSVDFMNYTVHIPPTPDNQPSTDPSISQKVEEQYVSSSLFTGGFNSVTR
AHLMDKVTDSEQSSHPQMAGAKGSCCAIPGCDANVMIDQRGDDILPCDCDFKICRDCYVDAVKAGGAICPGCKDPYKNTELDEVAVDDDNSNSRPLPLPP
PVATMSKMERRLSLMKSTKSGLMRSQTGDFDHNRWLFETRGTYGYGNAIWTNDGGFGGCKDDSAAEPKEFMSKPWRPLTRKLKIPAAVISPYRLLVFIRV
IALGLFLSWRVQNPNKEAMWLWGMSVVCELWFAFSWLLDQLPKLCPINRATDLNVLKDKFETPTLRNPTGKSDLPGVDVFVSTADPEKEPPLVTANTILS
ILAADYPVEKLACYVSDDGGALLTFEAMAEAASFANIWVPFCRKHDIEPRNPESYFSLKRDPYKNKVKADFVKDRRRLKREYDEFKVRINGLPDSIRRRS
DAYHTREEIKALKLQRQNRVVEVEPVETVKIPKATWMADGTHWPGTWMNSVPDHSKGDHAGIIQVMLKPPSDEPLHGSSDETKTLDLTDVDIRLPLLVYV
SREKRPGYDHNKKAGAMNALVRASAIMSNGPFILNLDCDHYIYNSLALREGMCFMMDRGGDRLCYVQFPQRFEGIDPSDRYANHNTVFFDVNMRALDGLM
GPVYVGTGCLFRRIALYGFDPPRAKEDNPGCCGRWLSFPSCFSFSSRKKKHTPEENKSLRMEDSDDDVEIMNMNMSFLPKKFGNSTFLIDSIPVAEFQGR
PLADHPAVKNGRPPGALTIPRDLLDASTVAEAISVISCWYEEKTEWGQRIGWIYGSVTEDVVTGYRMHNRGWKSVYCVTKRDAFRGTAPINLTDRLHQVL
RWATGSVEIFFSRNNALLASPRMKLLQRIAYLNVGIYPFTSFFLIVYCFLPALSLFSGQFIVSTLNVTFLAYLLIITVTLCMLAVLEIKWSGIELEEWWR
NEQFWLIGGTSAHLAAVLQGLLKVVAGIEISFTLTSKSGGDDVDDEFADLYIVKWTSLMIPPIV
|
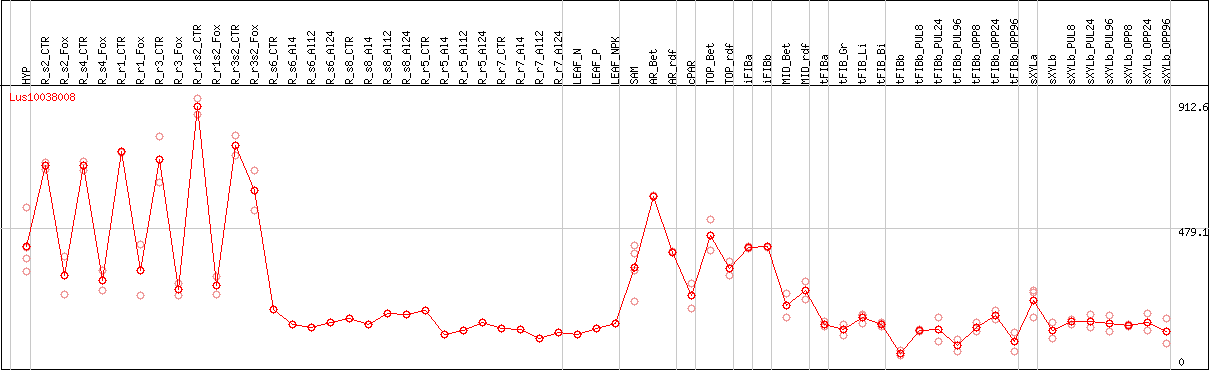
DESeq2's median of ratios [FLAX]
Coexpressed genes
Lus10038008 coexpression network
*The number of genes in the network is adjusted within 50 genes.*Gene name represents symbol(s) of closest Arabidopsis gene if symbol(s) for the gene itself doesn't exist.
*Circle diameter represents the number of connection with other genes within this network.
*Color for gene name represents subnetwork based on the result of network clustering.