Lus10038011 [FLAX]

| External link |
|
|||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Symbol | ||||||||||||||||
|
Arabidopsis homologues
|
| |||||||||||||||
|
Paralogs
|
|
|||||||||||||||
|
Poplar homologues |
|
|||||||||||||||
| PFAM info | ||||||||||||||||
|
Representative CDS sequence |
>Lus10038011 pacid=23163823 polypeptide=Lus10038011 locus=Lus10038011.g ID=Lus10038011.BGIv1.0 annot-version=v1.0
ATGCTTCTTCCTTTCCTCCCTTCACTCTACATCAGAAGCCATTATTGTTGTGCTACAGCTAAAGAACTCCTCGTTCCCCGATTCAGTCCGACAAGGGAAA
GGAGAAGGAAATACGACGACGACGACGACAAGTTGAGCTGTGTTCGAGACAGAAAATATCTGGCAGGTTTCTTCGGGGAGATGTCGATACCCAAGGAGCC
AGAGCATGTCATGAAGCTCCGTGGTGGATCAGTCCTCGGAAAGAAGACCATTCTTAAGAGCGACCATTTCCCTGGCTGCCAGAACAAGCGCTTAACTCCT
CCCATCGATGGCGCCCCAAATTACCGCCAGGCTGACACCTTACCTGTTCATGGCGTTGCAATACCAACTGTTGAGGGGATCCGTAATGTCATCAAGCACA
TACGAGGTAGAAAAGATGGGAAGAGAGCTCAAGTTCTGTGGTTTAACCTTCGTGAGGAACCGTTGATGTACATTAATGGACGTCCATTTGTTCTACGCGA
TGTAGAGAGGCCCTTTTCCAATCTTGAATATACGGGAATAAACAGGTTTAGGGTTGAACAAATGGAGGCTCGATTGAAGGAGGATATCTTGATGGAAGCT
GCCAGATATGGCAATAAGATTCTTGTTACTGATGAATTACCAGACGGTCAGATGGTGGACCAATGGGAGCCAGTATCTAGTGATTCTGTCTATGAAGAAT
TACAGGTGGAAGGTTACCACTTTGACTATGAGCGTGTTCCTATTACTGATGAAAAATCACCAGAGGAGACTGATTTTGATGTCTTAGTTGATAGAATCTA
CCAAACAGATTTGACTTCAGATATAATTTTCAATTGCCAAATGGGGCGTGGTCGCACAACAACTGGGATGGTGATAGCTACTTTGGTTTACCTTAACCGA
ATTGGATCTTCTGGTATCCCAAGATCCAATTCAGTTGGTAGAGTTTGTGACTTGGGTTCTGCTGTGAATGATAATGTCCTAAACTCCGAAGAGGCAATTC
GTAGGGGAGAGTATGGAGTAATAAGAAGTCTAACACGAGTTCTAGAGGGTGGTGTTGAAGGGAAAAGACAAGTGGACAAAGTTATCGACAAGTGCGCCTC
CATGCAGAACCTGCGGGAAGCAATTGCCACTTACCGCAATAGTATTCTTCGTCAACCTGATGAGATGAAGAGGGAGGCATCACTTTCGTTTTTTGTGGAA
TACTTGGAAAGGTATTACTTCCTTATCTGCTTTGCTGTATACATCCACTCAGAGAGAGATGCCCTTCGTTCTAGTTCTTTTGGTCATAGCAGTTTTGCTG
ACTGGATGAAAGCACGCCCCGAGTTGTACAGCATTATTCGCAGACTGGTCCGGCGAGATCCAATGGGTGCCCTTGGATATGCCAGTTCAAAGCCGTCATT
AAGGAAGATTGCTGAATCTGCTGATGGTCGTCCTTATGAGATGGGGGTTGTTGCTGCATCGAGGAATGGGGAGGTGCTAGGTAGTCAGACTGTTTTAAAA
AGTGACCACTGTCCAGGTTGCCAAAATACACATTTACCAGAGAGGGTGGAGGGTGCACCAAATTTCAGAGAAGTTCCTGGATTTCCAGTTTATGGGGTTG
CGAATCCCACAATAGATGGTATTGTTTCAGTGATTAAGAGGATTGGCAGATCTAAAGGTTCTCGGCCAGTTTTTTGGCACAACATGAGGGAAGAGCCTGT
TATCTACATCAATGGAAAACCATTTGTCCTCCGTGAAGTCGAGAGACCGTACAAAAACATGCTGGAGTATTCGGGAATTGATCGGAAAAGAGTGGAGAGA
ATGGAAGCTCGGCTGAAAGAAGATATCCTGAGAGAATCAGAACGTTATGGAGGTGCAATAATGGTCATTCATGAAACAGAGGATGGTCAAATCTTCGATG
CCTGGGAGTACGTGAATTCTAAATCTGTGAAGACCCCACTGGAGGTCTTCAGGTGCTTAGAAGCCGATGGTTCCCCTGTTAAATATGCACGAGTGCCTAT
CACTGATGGTAAAGCTCCCAAGAGTTCTGACTTCGACTTATTGGCAACAAACATTGCTTCTGCTCCCCAGGAAACTGCTTTTGTGTTCAATTGTCAGATG
GGAAGGGGAAGAACAACCACAGGTACAGTTATTGCTTGCCTTGTGAAACTGAGAGTAGAATTTGGGAAACCGATTAAAGTCTTGCACGATGATATAAACC
ATGACGAGGAGGATACTGGTAGCTCAAGTGGAGAAGACACAGGAGGGAATTCAGGATCCACCCCTGATACTACTGAAATGATAACTGAGAGGGAGCAAGT
CCGTGCCTTTGGCATTGACGATATCCTATTGCTGTGGAAGATAACGAGATTATTTGATAATGGAGTCGAATGCCGCGAGGTTTTAGATGCCATCATCGAC
AGATGCTCTGCACTGCAGAACATTCGCCAAGCAGTTCTGCAATATAGGAAGGTGATTAACCAACAACATGTGGAGCCAAGGGTTCGGAGAGTGGCATTGA
ATCGTGGTGCTGAATACCTAGAGCGTTATTTCCGGTTGATTGCTTTTGCTGCTTATCTTGGTAGTGGAGCATTTGATGGATTCTGTGGACAAGGAGACTC
GAGAATGACTTTCAAGAGTTGGCTACACCAAAGACCTGAGGTTCAAGCAATGAAATGGAGCATAAGATTGAGACCTGGGCGATTCTTCACTATCCCTGCG
GCATTAAGAGCACCTGAGGAATCTCAGCATGGAGATGCAGTAATGGAAGCTGCAATCAGGTCCCGTAGTGGTTCAGTTCTGGGGAAAGGCTCCATACTTA
AAATGTACTTCTTTCCTGGTCAGAGGACTTCCAGCCATATACAGATCCACGGGGCACCACACGTTTTCAAGGTGGATGGATACCCAGTTTATAGCATGGC
AACTCCAACTATTGCTGGTGCTAAGGAGATGCTAAAATATTTAGGAGCCAAGCCCAAGGTTGAGGGCTCAGCGACTCCCAAAGTGATATTGACTGACCTC
AGAGAAGAAGCTGTAGTATACATCAATGGAACACCTTTCGTCCTCCGAGAGTTAAATAAACCAGTGGATGCATTGAAACATGTCGGGATCACGGGACCAC
TGGTGGAAAGCATGGAAGCCAGACTAAAAGAAGACATAGTCTCGGAGGTGAGGCAGTCCGGTGGACGAATGCTATTGCACCGAGAAGAGTATAATCCAGC
TACAAACCAGTCCAGTGTTGTCGGATATTGGGAAAACATAGTTGCGGAGGACGTAAAGACACCTGCTGAGGTGTATGCTGCGCTGGAGGACGAGGGTTAT
TGTTTAGCATACAGGAGGATACCATTAACACGTGAAAAGGAAGCTGTGGCTTCTGATGTTGATGCTATCCAGGATCGTAAAGATGATAATGCAGGGTATT
ACCTTTTCGTTTCACATACCGGGTTTGGAGGAGTGGCCTATGCAATGGCAATCATTTGTACTCGACTCGGAGCAGAAGGAAATTTTGTCTCAGACATTGG
ACCACAACTGTCTGTTTCAGATTCTCTTCCTACTCTAGATGGGAACTTACCCTCTCAATCGTCAAATGAAGAAACTCTTAGAATGGGTGACTATCGAGAC
ATACTAAGCCTGACGCGAGTTATAATGTATGGGCCAAAGAGTAAGGCAGATGTCGACATTGTTATAGAGAAGTGTGCAGGAGCAGGACATTTGCGCGACG
ATATCTTCCGCTACACCAACAAACTCATAAACTTTTGCGACGGAGATGATGAGCGGCGTGCACACCTCTTGGATATGGGCATTAAGGCTTTAAGGCGGTA
CTTCTATCTGATAACATTCAGATCATACCTGTACAGCACGAGGCCGACAGAGGTGAGATTCGTGGAGTGGATGAAGGGAAGGCCTGAACTGGGGAATCTC
TGCAATAATCTGAGGATAGATAAATGA
|
|||||||||||||||
|
AA sequence
|
>Lus10038011 pacid=23163823 polypeptide=Lus10038011 locus=Lus10038011.g ID=Lus10038011.BGIv1.0 annot-version=v1.0
MLLPFLPSLYIRSHYCCATAKELLVPRFSPTRERRRKYDDDDDKLSCVRDRKYLAGFFGEMSIPKEPEHVMKLRGGSVLGKKTILKSDHFPGCQNKRLTP
PIDGAPNYRQADTLPVHGVAIPTVEGIRNVIKHIRGRKDGKRAQVLWFNLREEPLMYINGRPFVLRDVERPFSNLEYTGINRFRVEQMEARLKEDILMEA
ARYGNKILVTDELPDGQMVDQWEPVSSDSVYEELQVEGYHFDYERVPITDEKSPEETDFDVLVDRIYQTDLTSDIIFNCQMGRGRTTTGMVIATLVYLNR
IGSSGIPRSNSVGRVCDLGSAVNDNVLNSEEAIRRGEYGVIRSLTRVLEGGVEGKRQVDKVIDKCASMQNLREAIATYRNSILRQPDEMKREASLSFFVE
YLERYYFLICFAVYIHSERDALRSSSFGHSSFADWMKARPELYSIIRRLVRRDPMGALGYASSKPSLRKIAESADGRPYEMGVVAASRNGEVLGSQTVLK
SDHCPGCQNTHLPERVEGAPNFREVPGFPVYGVANPTIDGIVSVIKRIGRSKGSRPVFWHNMREEPVIYINGKPFVLREVERPYKNMLEYSGIDRKRVER
MEARLKEDILRESERYGGAIMVIHETEDGQIFDAWEYVNSKSVKTPLEVFRCLEADGSPVKYARVPITDGKAPKSSDFDLLATNIASAPQETAFVFNCQM
GRGRTTTGTVIACLVKLRVEFGKPIKVLHDDINHDEEDTGSSSGEDTGGNSGSTPDTTEMITEREQVRAFGIDDILLLWKITRLFDNGVECREVLDAIID
RCSALQNIRQAVLQYRKVINQQHVEPRVRRVALNRGAEYLERYFRLIAFAAYLGSGAFDGFCGQGDSRMTFKSWLHQRPEVQAMKWSIRLRPGRFFTIPA
ALRAPEESQHGDAVMEAAIRSRSGSVLGKGSILKMYFFPGQRTSSHIQIHGAPHVFKVDGYPVYSMATPTIAGAKEMLKYLGAKPKVEGSATPKVILTDL
REEAVVYINGTPFVLRELNKPVDALKHVGITGPLVESMEARLKEDIVSEVRQSGGRMLLHREEYNPATNQSSVVGYWENIVAEDVKTPAEVYAALEDEGY
CLAYRRIPLTREKEAVASDVDAIQDRKDDNAGYYLFVSHTGFGGVAYAMAIICTRLGAEGNFVSDIGPQLSVSDSLPTLDGNLPSQSSNEETLRMGDYRD
ILSLTRVIMYGPKSKADVDIVIEKCAGAGHLRDDIFRYTNKLINFCDGDDERRAHLLDMGIKALRRYFYLITFRSYLYSTRPTEVRFVEWMKGRPELGNL
CNNLRIDK
|
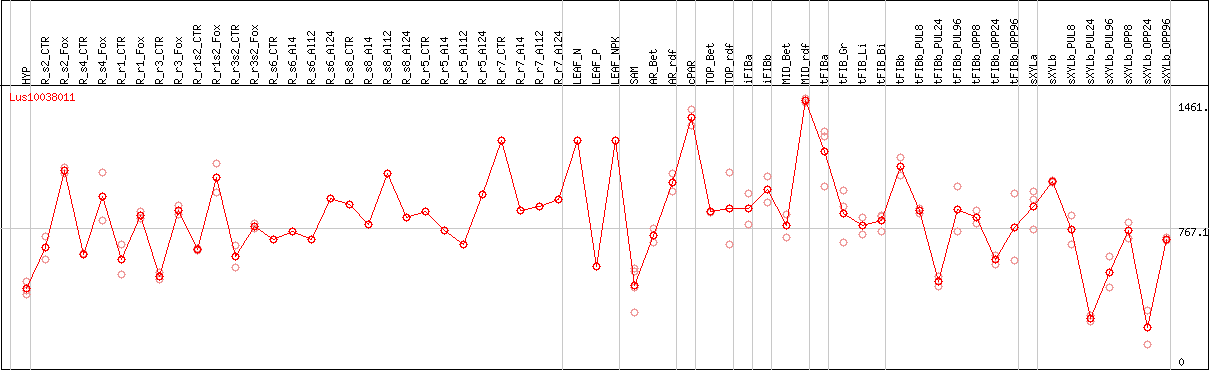
DESeq2's median of ratios [FLAX]
Coexpressed genes
Lus10038011 coexpression network
*The number of genes in the network is adjusted within 50 genes.*Gene name represents symbol(s) of closest Arabidopsis gene if symbol(s) for the gene itself doesn't exist.
*Circle diameter represents the number of connection with other genes within this network.
*Color for gene name represents subnetwork based on the result of network clustering.