Lus10042072 [FLAX]

| External link |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Symbol | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Arabidopsis homologues
|
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Paralogs
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Poplar homologues |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
| PFAM info |
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Representative CDS sequence |
>Lus10042072 pacid=23153874 polypeptide=Lus10042072 locus=Lus10042072.g ID=Lus10042072.BGIv1.0 annot-version=v1.0
ATGGATCCCGAAGAGGACCCCGATTCAATTCCCTCCTCAGAACCCTCCCCACCTTCTCAAGCGGATACCATTTCACCGCTCCCAACGGCCACGCCGATTG
AGCAGTCTCCGTCAGCTGAGCCAGTGAGTACATCCGTGGACAACGCTCAAGGGACGCCGTACGAGTTGCGTGGCAGTGAGCTGCAACCGCCGGTGAGTAA
TCACGAGTCGGAAGCGGCGGAGGTTGTCGATGAATTCGAGGAGCGAGTGAAGGATTCTGAGCGGAGCCATGAAGAGCTGGCTGGCGGGTCCGGCGGTGAG
GAGGAGTCTCAGTCAGTTGCTGACGAGGCAGCGGCGAGTGAAATGGAAATGACCGTTGATGAGCTTGGAGATCATGCTGAAGGATCAGAGGACGTGTCTT
TGGTCGTTGAAGAGAGCAAGGAGGTTGCTGTGAGAGGAGAAGACTCCTCTGCTGGAGTTGTTGTCGGAGAGCAGGAGAGCAGCGGTATTGTTGACAATGT
CGGTTCACTAGGTAAGGCTGATGTGGACGTCTCTGGTAAGGAGGAAACTCCTGGCGAGACACTGGTAAGCCAGGAGGTGGATGAATTCTCGATGGTTGAA
AAAGTTGAGCAGACAGAGAAGAAAGACGAGGCAGAGGAGGAGAAACAGAATGCGTTGGTGGTTGAGGAAACCACGAAGAAGGACGAGGTAGATAATGTGG
AAAACAAAGATGAGGTAGACGAGAAGCAGATTGAATTGGTTGAGGGGGTCTCCATGAAAGACAAGGAAGACGGTGTCGAGAAGAAGGATGAAATGGAGGT
TGGTCCCGTGCCAGAAAAAGATATGAATGGAGAGAACGTTGATGGAAGTGGGAATGTGGAGGATGATGGCGGAGAGAAGGTGGATAGGGCATGTGTAGAT
GATGTAACAGAGGAAATCCAAGGTTCTGAACAGAATGAAACAGCTAATGTTGGTAGGAGTATTGAGGAAGTAGACGAGATGGAGGTGGATGATGGTATTG
AGGAGAAAGATAAGGGAGATGAGAGACTCGACATAAAAGAAGAGGAAGGTGTGAAGGTGAGTGAAGCTGTAGAAGAGACGGAGAATGTTGATGTGGCAAT
GGATAGGGATGACGAGTCGAATGAATCGGAAGTAGAGTATCTGAAGTTGAAAGAAGTGGCAGAAGAGGATCACAAATTGACTGGAGCGAAAGAAGAGGCT
TTTGAGATGAATGAAGTGGAAAAAGATGCTGAGAAAGTCAATGAGGCAGTAGATGGGGATGAAAAGTTGAATGAATCAGCAGGAGAGGGTGTGAAGTTGA
ACGAAGTAGCTGAAGAGGATCAGAAGTTGACTGGAGCAAACGAAGAGGTTGTGGCCATGAAAGAAGTTGAAAAAGAGGAAGAGAATGCTGATGTGACAAT
AGATGGGGATGCCAAGTTGACTGAAGTGGAAGAAGAGGATCTAAAATTGAACGAAGTAGCAAAAGAGGATGCAGAGGCGAGTGAAGCAAATGAAGAGGTC
GTGAAGGTAGAAGGAGCTGAAGAACAGAATATCAATGAGTTGGATGAGCAGGATGAGGAGGAGGAGGAGGAGGAGGAGGAGTTGAATGAAGCTGAAGAAG
AAGACAAAGAAGATACTGATGAAGAAATGACTGAAGTGGCCGAAGAGGATGATAAGATGAATGAGGAAGAAGGAGGAGAAGAAGTAGAAGAAGGTGATGA
TGAGAAAATGAATGAAGCAGAGGATACAGAAGTGGCAGCAGAAGACAATGTTGAGGAAGTGAGTCAAACTAGCAGTGGTAAGAGGAAGCGGGGAAAGAAT
GCAAACGTAATTGGTAAATCGCCATCAAAGAAGAAGACGGAGGAGGATGTATGTTTTATTTGTCTTGACGGCGGGGAGCTTGTCCTGTGTGATCGCAGGG
GGTGCCCAAAGGCATACCATCCCTCCTGCGTAAACCACGATGATGCTTTTTTTCAAACGAAAGGAAAATGGTATTGCGGTTGGCATATTTGCAGTAAGTG
TGAGAAGAATGCTAACTACATGTGTTTGACATGTACATTCTCTTTGTGCAAAGGGTGTATCAAAGAGGATGCTATATTTTGTGTTAGAGGTAACAAAGGG
TTCTGTGAGACATGCTGGAAAACTGTCAAGTTGATTGAGATGAATGAACAAGGAGACAAGGAACCAACCTCAGAGAATGTTGATGAGAAAAACAGCTGGG
AATATCTCTTCAAGGATTACTGGATTGATCTGAAGACAAGCTTATCTATCACGTCAGATGAAGTTGTCATGGCAAAACATCCACGCAAAGGGTCTGATTC
AGTTGCTGCAAAGCAGGACTCTCTTGATGAATTGTACGAAGCTCCCAATGATGCAGGATCTGCATCAGATAGCTCTGCTGGCAATCCTGAATTAACTGCC
TCCAAGAAAAGAAAGGGAAAAAAACGGCTGAAAACTCGTGGTAAGGAAAGGGAATCAGCTGGTAAGAGGAAGTTAAATGGGGTTGGGGTATCCTCAGATA
ATGATGAGTGGGCATCGAAAGAGCTTCTAGAGTTTGTTATGCACATGAAGAACGGTGATAAATCTGTTTCTTCTCAGTTTGACGTACAAGCTCTTCTTTT
GGAGTATATAAAGAGGAATAAACTCCGCGATCCACGTCGGAAAAGTCAAATACTTTGTGATTCGAGGCTTCAACATCTGTTTGGAAAATCTCGAGTGGGC
CACTTTGAGATGTTAAAACTTCTCGAATCTCACTTTCTTTTGAAAGAGAACTCTCAGATGGATGCTGCTCGAGGAAATGTTGACGCTGAAGGCAATCAGG
TAGACGGTGATGGGATCTCTGATGTGAAAGCTGGCAAGGATAAGAAACGGAGGTCCCGTAAGAAGGGCCAGGGTCTGCAGTCTAATGTTGATGACTATGG
TGCCATTGACACACACAACATAACTTTAATTTACTTGAAGCGGAGTTTGGTGGAGGAACTTCTTCAGGACACAGATACATTTAATGATAAAGTTGTTGGT
TCTTTTGTGAGATTAAGGATATCTGGAAACACTCAAAAGCAAGATTTGTATAGGCTAGTCCAAATTATAGGCACCAAGACAGCTGATAATCCATATAGAG
GGGGAAAAAGGAATATTAATTTCCTGCTGGAAATATTGAATCTAAACAAGACCGAGGTCATTTCAATCGATGCCATTTCGAATCAAGAATTTACAGAGGA
TGAATGCAAGCGTTTGCGGCAAAGCATTAAGTGTCAGCTGCTCAATCCATTGACTGTGGGTGACATTCAGGAAAAGGCCATCGCTCTGCAGGGAGTTAGA
GTTCAAGATACGCTGGATGCAGAAATAACACGTCTCAGTCATCTTCGCGATCGAGCAAGTGACATGGGGAGGAGAAAGGAATATCCTTTATTTGCCAAAA
AGTTGCAGCTTCTGAAAACACCTGAGGAGCGCCAGCGGAGGCTAGGAGAAATTCCTGAAATTCACGTTGACCCAAAGATGGATCCGAGTCACGAGTCTGA
AGAAGAAGTAGATGAAACAGATAATAAGAGTAGAGATACATATTTGAGGCTGCGAGGCAGTGGCTTCAATAGGAGGGCAAGAGAGTCAATTTCGCCAAGG
AAAGGGGCAACGAGTCCAAACGAATCCTGGGGTCGAACACGAAGTTTCTCAAATACGAATCGAGAGTTGACCAGAAACTCGTCTGGCAAGGGGTTCTCTT
ACAGAGGGGATGACACAATTGGGTCTAGCGAAAAAGCGGATGAGAACTTATGGAGTCGGGGAAGAGACAGGGAGATTGAACCTTCCCGGAGTTGGGATAG
TCCAAAACGTGCTTCAAATGCAGAACCACAGAATTCGCATTCAGTGGTAACGCCGGAATTAGCTTCCAGGAGTGCACAAGAGATTTCTCCTGGACCTTCC
TCGACGGGTTTCGGTGACTCAGCTTCCAAAGCAAATGAAACACAGAAGATATGGCATTACAAAGACCCGGCTGGAAAAATTCAAGGACCCTTTTCAATGG
TACAGCTTCGAAAATGGAACAAATCTGGATACTTCCCTGCTAATTTGAGAATATGGAAAGCCACAGAGGACGAAGGGAACTATATACTTCTTACTGATGC
ATTAGATGGAAATTTCCAGACTCCATTGGTTCAGAGTCCAAAAGCATCGTCCTTTAAAGCCGGGATTGCGAGAGAAAATGATAGGCCTTCTGGAAGATCG
GTTCCCATTGCAGTCGAGGTCCCTAATAATTCTGCTGACAGATGGAATTCAGAAACGAGCCTCCCTTCCCCAACTCCATCCTCAGCTGGATCAAGGGTAC
GAGCTAGGGAAAGTAGATGGTCTCCAACACCTCCTCAAACTGCTGGTTCTCAGTTTGAAGTTAATCCATTCTCTGCTGCAAGTAATGACAGGAATACTCT
GTCCTCTAATAATGTAAGTTCTGCAATTGCTCCTCAGATGCATTCTCAATCAATGGCGCCGGTTACATCACCGGCGGTGCCGGTCAACTCCCATATGCTT
CGAATCCCCAATTCCAATGGCGCTGCAACTAATGCAGCGATGGATACAGTAGCTTTCCAGAGCTTGGTTCAGACTATCAGTAATAATCCTCTTCTGGTGT
CACAGGGAATGGGAGGAGTCGTTCCGGTTTCTAGGCCCGAAACAAACATGAGCGCTGCAAGTGGGACTCATCAAGCATGGGGAACTGCTTCTTCACTGCA
GCGGCCCGAGCTCAATAATAGTCAAATGCATGTGGCTCCTTTAAGTAATGCTTATGGGAACTGGGGAGCTCCTATGGCAGCTCAGTCAAACGTTCAACAT
TCTGGTCAGGCCGGGGCACAATGGGGAATGGGTGTTGCAGTTGTAGACAACAACCCGGTTTCTACCGCCAATTCGACCCAGGGATGGAGCGGAATCCCAG
GAAACCAAACCATGGTCTGGGGAGGAAACATGCCTGCAAATGCGAATCAGGGATGGGTACCACCACAAAATCAGGGAATGATTGCTGGAAACGCGAATGC
TGGTTGGATTCAGGGGCAGCAGGTAGTGAGCAACACAAATGCAGGGTGGTCTGCTCCAGCTGTTCATCAACAAGTTCAAGGTTGGGCACCGGCGCCCGTA
CCAACTTCTTCTACAAATCAGAACTCGGGAGGGTATATCAGTCATGGAAACGCAAACAACAACCCCGGTTGGAGTGTGGCAGCTCCTAGTGTAGGAGGGA
ACAACTGGGGGAACGAAAGGAACAATGGTGTCGGCGGGTCAGGCAATAGGGACAGAGGCACTCCTCAAGGAGGAGATTCTGGGTATGGAGGTGGACGAAG
CGGCGGGGATAGAGCATGGAATAGACAGTCTTCTTCTTCCTCGGGGAGAGGCGGAGGAGGAGATTTCGGATCGAGAGCGTATAATAGTAGAGGGCAAAAG
TGTGAAGCAAACAGAGAGGTGGTGGAGGAAGTAGGAATTTTGAGCACCGTTGGAAATGTGTGTACAGTGATTTCTAACTTGTATCAACATAGAATGGTGC
AGTGCAGCAGGAACCTCCGTAACCGAAGAATCGGTCAATACTCGATACAACGTGCCAAGCTGAACATTGAGGATAGGTAA
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
AA sequence
|
>Lus10042072 pacid=23153874 polypeptide=Lus10042072 locus=Lus10042072.g ID=Lus10042072.BGIv1.0 annot-version=v1.0
MDPEEDPDSIPSSEPSPPSQADTISPLPTATPIEQSPSAEPVSTSVDNAQGTPYELRGSELQPPVSNHESEAAEVVDEFEERVKDSERSHEELAGGSGGE
EESQSVADEAAASEMEMTVDELGDHAEGSEDVSLVVEESKEVAVRGEDSSAGVVVGEQESSGIVDNVGSLGKADVDVSGKEETPGETLVSQEVDEFSMVE
KVEQTEKKDEAEEEKQNALVVEETTKKDEVDNVENKDEVDEKQIELVEGVSMKDKEDGVEKKDEMEVGPVPEKDMNGENVDGSGNVEDDGGEKVDRACVD
DVTEEIQGSEQNETANVGRSIEEVDEMEVDDGIEEKDKGDERLDIKEEEGVKVSEAVEETENVDVAMDRDDESNESEVEYLKLKEVAEEDHKLTGAKEEA
FEMNEVEKDAEKVNEAVDGDEKLNESAGEGVKLNEVAEEDQKLTGANEEVVAMKEVEKEEENADVTIDGDAKLTEVEEEDLKLNEVAKEDAEASEANEEV
VKVEGAEEQNINELDEQDEEEEEEEEELNEAEEEDKEDTDEEMTEVAEEDDKMNEEEGGEEVEEGDDEKMNEAEDTEVAAEDNVEEVSQTSSGKRKRGKN
ANVIGKSPSKKKTEEDVCFICLDGGELVLCDRRGCPKAYHPSCVNHDDAFFQTKGKWYCGWHICSKCEKNANYMCLTCTFSLCKGCIKEDAIFCVRGNKG
FCETCWKTVKLIEMNEQGDKEPTSENVDEKNSWEYLFKDYWIDLKTSLSITSDEVVMAKHPRKGSDSVAAKQDSLDELYEAPNDAGSASDSSAGNPELTA
SKKRKGKKRLKTRGKERESAGKRKLNGVGVSSDNDEWASKELLEFVMHMKNGDKSVSSQFDVQALLLEYIKRNKLRDPRRKSQILCDSRLQHLFGKSRVG
HFEMLKLLESHFLLKENSQMDAARGNVDAEGNQVDGDGISDVKAGKDKKRRSRKKGQGLQSNVDDYGAIDTHNITLIYLKRSLVEELLQDTDTFNDKVVG
SFVRLRISGNTQKQDLYRLVQIIGTKTADNPYRGGKRNINFLLEILNLNKTEVISIDAISNQEFTEDECKRLRQSIKCQLLNPLTVGDIQEKAIALQGVR
VQDTLDAEITRLSHLRDRASDMGRRKEYPLFAKKLQLLKTPEERQRRLGEIPEIHVDPKMDPSHESEEEVDETDNKSRDTYLRLRGSGFNRRARESISPR
KGATSPNESWGRTRSFSNTNRELTRNSSGKGFSYRGDDTIGSSEKADENLWSRGRDREIEPSRSWDSPKRASNAEPQNSHSVVTPELASRSAQEISPGPS
STGFGDSASKANETQKIWHYKDPAGKIQGPFSMVQLRKWNKSGYFPANLRIWKATEDEGNYILLTDALDGNFQTPLVQSPKASSFKAGIARENDRPSGRS
VPIAVEVPNNSADRWNSETSLPSPTPSSAGSRVRARESRWSPTPPQTAGSQFEVNPFSAASNDRNTLSSNNVSSAIAPQMHSQSMAPVTSPAVPVNSHML
RIPNSNGAATNAAMDTVAFQSLVQTISNNPLLVSQGMGGVVPVSRPETNMSAASGTHQAWGTASSLQRPELNNSQMHVAPLSNAYGNWGAPMAAQSNVQH
SGQAGAQWGMGVAVVDNNPVSTANSTQGWSGIPGNQTMVWGGNMPANANQGWVPPQNQGMIAGNANAGWIQGQQVVSNTNAGWSAPAVHQQVQGWAPAPV
PTSSTNQNSGGYISHGNANNNPGWSVAAPSVGGNNWGNERNNGVGGSGNRDRGTPQGGDSGYGGGRSGGDRAWNRQSSSSSGRGGGGDFGSRAYNSRGQK
CEANREVVEEVGILSTVGNVCTVISNLYQHRMVQCSRNLRNRRIGQYSIQRAKLNIEDR
|
DESeq2's median of ratios [FLAX]
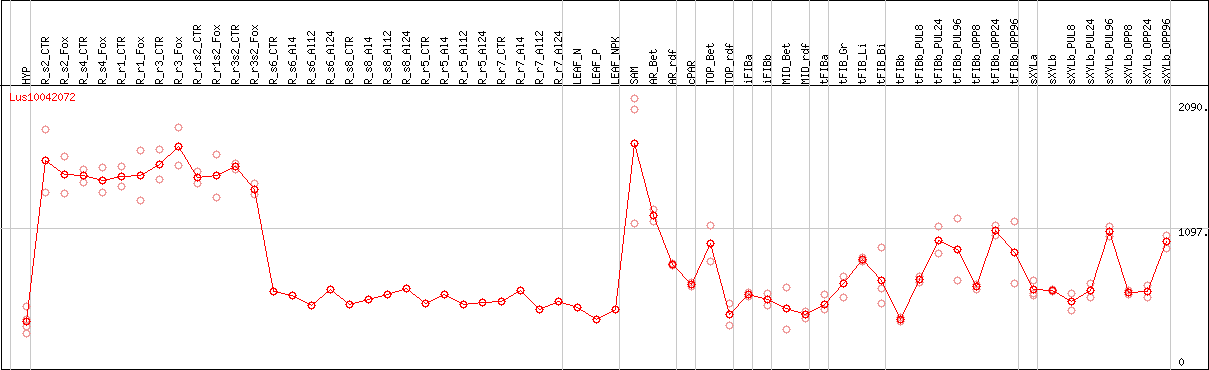
Coexpressed genes
Lus10042072 coexpression network
*The number of genes in the network is adjusted within 50 genes.*Gene name represents symbol(s) of closest Arabidopsis gene if symbol(s) for the gene itself doesn't exist.
*Circle diameter represents the number of connection with other genes within this network.
*Color for gene name represents subnetwork based on the result of network clustering.