Lus10042137 [FLAX]

| External link |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Symbol | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Arabidopsis homologues
|
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Paralogs
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Poplar homologues |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
| PFAM info |
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Representative CDS sequence |
>Lus10042137 pacid=23153654 polypeptide=Lus10042137 locus=Lus10042137.g ID=Lus10042137.BGIv1.0 annot-version=v1.0
ATGCATGGACGGGAAGGTGAGGAGAGGCAAAAAGCTCGGCACATGTGGACAGATCCCACGCCTGCCAATCTGGTTGTAACGGGTGATGGTTCTTTGTCTC
CTCCGGTTCTTAATTCGTTTTACAAGGACGGCCGGAAAATCTGTGTTGGGGATTGCGCTCTTTTCAAACCACCAGAGGAGTCACCTCCTTACATCGGAAT
AATTCACTCTGTGACTGCAAGTGAAGATAATAACTTTATTTTAGGTGTGAATTGGCTTTATCGACCTGCTGAACTAACGCTTGTCAAAGGCATCCAGTTG
GACGCTGCGCCAAACGAAATATTTTATTCCTTTCACAAGGATGCTGCATCTGCTGCATCACTACTTCATCCGTGTAAAGTTTCCTTCCTTCCCAAAGGTG
CTGAGCTTCCATCAGGGATTTCTTCATTTGTGTGCCGCCGTGTTTATGACATAAACAAAAAGTGTTTATGGTGGCTTACTGATCAAGATTATATTGATGA
ACATCAAGAAGAAATAAAAGAAGTATTATCTAAGACTCGCATAGACATGCATACAACAGTGCAGTCCGGAGGACATTCACCAAAGCCAATGAATGGTCCA
ACTGCTACATCACAGTCAAAACCAGGTTCGGATAGCGTGCAGAATAGTGGTTCGTCCTTTCCTTCTCAAGATGATGGGGATTCTGCTAACTCAAGAGCAG
AGAACAACTGGAAATCTGAAATAACAAAAATGAAAGAGAAAGGAGGTCTTGTAGATTACTACGCTGTTGAGAAGTTGGTGCAACTTATGCTATCTGATAG
AAATGAGAAGAAGATAGATTTGGTTGGTCGGTCCATGATGGCTAGTATAGTAGCTGCCACTGACAAGTTCGACTGCCTTATTTGGTTTGTTAAGCACAGA
GGGGTGCCTGTTTTTGATGAATGGATACAGGAGGCACATAAAGGAAAGGTTGGTGATGGTAGTGGTCCCAAGGACAGTGACAAATCAGTAGAAGAGTTTC
TCTTAGTCTTACTCCGTGCTCTTGATAAACTCCCTGTTGATCTACATGCTTTACAAACATGTAACATTGGGAAGTCTGTCAACCATCTACGTACTCACAA
GAGCTTGGAAATTCAGAAGAAGGCTAGGAGTTTGGTTGACACTTGGAAAAAGCGTGTTGAGGCTGAAATGGATGCGAAGTCTGGGTCAAACCATGGTGTC
CATTGGGCTACAAGATCACGTCTTCCGGATGCTTCCCATGGTGGGAACAGACATACAGGTGTGGCCTCTGAGGTTGCCCTCAAGAGTTCTACCAGTCAGC
TTGCTGCTTTGAAAACTGCGCCAGCGAAGCTAGTCTCTGCAGAGGCTATGACGAAGTCGGTATCTGGTTCTCCAGGTTCTAATAAATCAACCCCAGTGCC
TGTGCCTGGGGGTAGCACTGCTAAAGAAGGGCAGGCTCGATATGGCAGTGGTGCGGGTGGATCCGACGCCTCTCCAACAATGGTTAGGGATGAAAAGACC
AGCAGCTCTAGCCAGTCGCACAATAATAGCCAAACTGGTTCTGGTGACCAAACCAAAGCCGCAGGATTTTCTGGGAAGGAGGACACAAGGAGCTCTGGTT
CTGTAACGCCAGGTAGGGTTGCTAGTGGTTCTTCACGGCACCGTAAGTCTAACAATGGCTTTCTGGGCCAAGGTGGAACCATAGTTCAACGGGAAACTGG
GTCGGGTAGAAATTCCCCATTGCGAAGAAATTCCAGTTCAGAAAAGGTATCACAAATTAGTTTGACATCTGATAAGGCAGTTGATGTTCCAGCAGTTGAA
GCCAACAATCACAAAATCGTAGTAAAGATTCCTAACAGAGGCCGCAGTCCCGGCCAGAGTGCCAGTGGAGGAGGAGGATCAATTGATGATCCTTCTGCTG
TGCACATTGGCTCTTGCTCTCCTGCAGTTTCTGATATGCAGGACCAACTCGATCACAATTTGAAAGATAAGGCTGATGCTTCCCGTGCTAACGTAGTCTC
TGATGTTAATACTGAGTCGTGGCAGAGCAATGATTTCAAAGATGTGTTGACTGGGTCAGATGAAGGAGATGTTTCTCCTACAACAGATCTGGATGATGAA
CGCAGTAGGCCCAGTGAAGATGCCAAGAAGTTGCCAGAAGTCTACAAATCTGCATCATTACCCGCTAGCAATGAGTACCAGTTGGCAAAGTTAAATGATG
CTTCATTTAGCTCCATAAATGCCTTGATTGAAAGTTGTGTGAAACACTCTGATGCCAATGCATCGACATCAGCAGCTGACGAGGTTGGGATGAACCTGCT
TGCTAGTGTTGCTGCTGGAGAGATGTCTAAATCGGATGTGGCTCCTCCAGCCTCTCCTCCCCAGCTGCAGTCGCATCCAGATGGCAATTTGGCTGATGAG
CATGGTCGGTCAGGTGATAATATTGTTGGTGAATCTCACAACAAAGGTGGTGGTGTTGATTCGTTAGAGGTTGAGGTGGATGGTGCCTCTCGGGATAAAT
CTCCTATGCAGCTTGGCCATGATCCAATTTCTTCTGCTGTAGAAGCCCAGCAAACTAGAGAAACGGGTAAGGAAGATAAAATGAATGGAATGTTGAGTTG
CAGTTCTGCTCAGCTTCCTGCTGTGGTTGCTGGGGAAAAAAACTTGGGCGGGGTTGTGAAACAACCGGAGAAAGAAGATGTTAGTAGCACACTCAATGGA
GATGCTACCTCTGATATTAAAGAGAAACCACTACCATCCTTTTCAACAGAACCTAAGGTTAATGTTGTTGGTGGCGATGTTAAGGTTGGTGGAGTTCAAA
GTTCATCTTCTCAGTTGGGTTCTAGTGCTGTTGGGGAGAATGAGAAACTGCGGAATGAAGAGTTGAAAGTTGGTTTACTGGACGAGAAGCCACCTGCTGT
GATTCATCCGGATTCTGGTGGGAGAACTGATGTTCAGATGCAGCAGGTGGTTTCTAAATGTCATGAACTGAAAAATGAAGATGTTGATGAAACTGGTGGA
AGAAAATTGTCCCCTGCAAAGCAAAAAGCTGGTCAGCTTTCTGACGGAACTGCTACTGGTCTAAAGGAAAAGCCCAATGTTAAAGTTGAGAGTAATGGGG
CAACCGAACAGAAAATTGCTTCACAGGATGCGACTAATATGCAACCGGACCACAGAGTGGGATCTCAAGGAGCCAAGGTGAAAGTTGGTGAAGCTGATGC
GGAGGAAAATTGTTCAGCTGCAGCAGATGCTTCTACAGTAAGTGAAAATAATGGGGGGAAGGTAGTATTTGATCTGAATGAGGGACTTAACGGTGATGAT
GGGAAGTATCTGGAGCCACCCAGTTCAAAAGTTCCCAGAACTTCTGCTTCTCCTCTTCAACTGCTCTCGGGGCCACTACTCAGCCACGTCTCCGCTTTTC
CCTTTTCGTTGTTCTTCGCGCACCACCGAGTTCCACTGCCTCTGCATCATCCAAAGATCCAAACTTGTCGCAGAAAGATGGTTGCCGTGGAGCCTAACCT
GGACCAGTTCTACGAGGAGAAGAAGCGCGTTAGAAACCCTTTCGTCCCCATAGGCGCACTTTTGACGGCTGGAGTGCTGACGGCAGGACTGGTCAGCTTC
AGAAGAGGGAATTCGCAGCTGGGGCAGAAGTTGATGAGAGCTAGAGTGGTAGTACAAGGAGCAACCGTGGCGCTTATGGTTGGGACTGCATTCTACTATG
AACAGAATCCCTGGAAGAAGTCTGACTGA
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
AA sequence
|
>Lus10042137 pacid=23153654 polypeptide=Lus10042137 locus=Lus10042137.g ID=Lus10042137.BGIv1.0 annot-version=v1.0
MHGREGEERQKARHMWTDPTPANLVVTGDGSLSPPVLNSFYKDGRKICVGDCALFKPPEESPPYIGIIHSVTASEDNNFILGVNWLYRPAELTLVKGIQL
DAAPNEIFYSFHKDAASAASLLHPCKVSFLPKGAELPSGISSFVCRRVYDINKKCLWWLTDQDYIDEHQEEIKEVLSKTRIDMHTTVQSGGHSPKPMNGP
TATSQSKPGSDSVQNSGSSFPSQDDGDSANSRAENNWKSEITKMKEKGGLVDYYAVEKLVQLMLSDRNEKKIDLVGRSMMASIVAATDKFDCLIWFVKHR
GVPVFDEWIQEAHKGKVGDGSGPKDSDKSVEEFLLVLLRALDKLPVDLHALQTCNIGKSVNHLRTHKSLEIQKKARSLVDTWKKRVEAEMDAKSGSNHGV
HWATRSRLPDASHGGNRHTGVASEVALKSSTSQLAALKTAPAKLVSAEAMTKSVSGSPGSNKSTPVPVPGGSTAKEGQARYGSGAGGSDASPTMVRDEKT
SSSSQSHNNSQTGSGDQTKAAGFSGKEDTRSSGSVTPGRVASGSSRHRKSNNGFLGQGGTIVQRETGSGRNSPLRRNSSSEKVSQISLTSDKAVDVPAVE
ANNHKIVVKIPNRGRSPGQSASGGGGSIDDPSAVHIGSCSPAVSDMQDQLDHNLKDKADASRANVVSDVNTESWQSNDFKDVLTGSDEGDVSPTTDLDDE
RSRPSEDAKKLPEVYKSASLPASNEYQLAKLNDASFSSINALIESCVKHSDANASTSAADEVGMNLLASVAAGEMSKSDVAPPASPPQLQSHPDGNLADE
HGRSGDNIVGESHNKGGGVDSLEVEVDGASRDKSPMQLGHDPISSAVEAQQTRETGKEDKMNGMLSCSSAQLPAVVAGEKNLGGVVKQPEKEDVSSTLNG
DATSDIKEKPLPSFSTEPKVNVVGGDVKVGGVQSSSSQLGSSAVGENEKLRNEELKVGLLDEKPPAVIHPDSGGRTDVQMQQVVSKCHELKNEDVDETGG
RKLSPAKQKAGQLSDGTATGLKEKPNVKVESNGATEQKIASQDATNMQPDHRVGSQGAKVKVGEADAEENCSAAADASTVSENNGGKVVFDLNEGLNGDD
GKYLEPPSSKVPRTSASPLQLLSGPLLSHVSAFPFSLFFAHHRVPLPLHHPKIQTCRRKMVAVEPNLDQFYEEKKRVRNPFVPIGALLTAGVLTAGLVSF
RRGNSQLGQKLMRARVVVQGATVALMVGTAFYYEQNPWKKSD
|
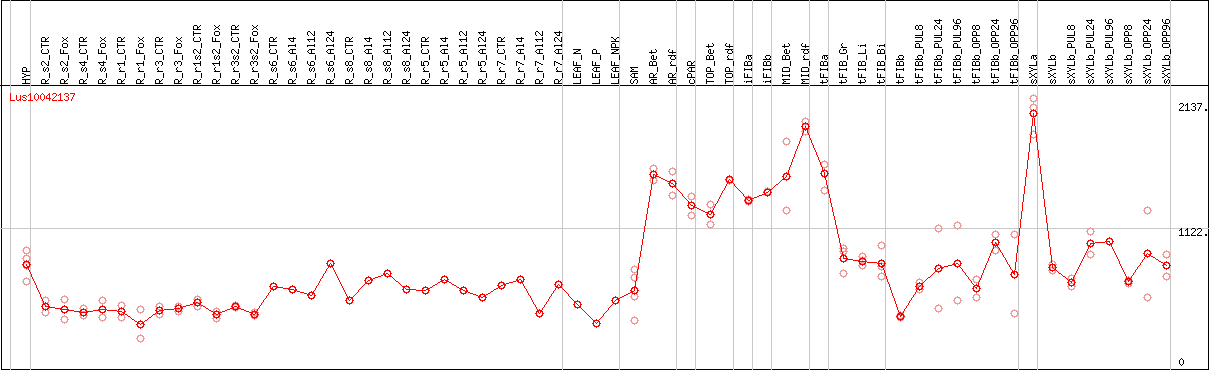
DESeq2's median of ratios [FLAX]
Coexpressed genes
Lus10042137 coexpression network
*The number of genes in the network is adjusted within 50 genes.*Gene name represents symbol(s) of closest Arabidopsis gene if symbol(s) for the gene itself doesn't exist.
*Circle diameter represents the number of connection with other genes within this network.
*Color for gene name represents subnetwork based on the result of network clustering.