Potri.011G000200 [POPLAR]

| External link |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Symbol | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Arabidopsis homologues
|
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Paralogs
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Flax homologues |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
| PFAM info |
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Representative CDS sequence |
>Potri.011G000200.1 pacid=42780328 polypeptide=Potri.011G000200.1.p locus=Potri.011G000200 ID=Potri.011G000200.1.v4.1 annot-version=v4.1
ATGTTTAGCTGGAAACGTCCTTCTGAGCTCCTTCGTTTAACTCTAAATTATGGCTCCGAAGATCTCGGCGACGACCTCAACCGCTCCTCCACCTCCTCCT
CTTCCACCACCGCATTCACTCCTTCCTCGTCTCCTCTGGCCTATATTTCTACGGAGGCCGCCGCGGAGGAAGAGGACCAGGTAGGCTTTAAAATTGAATT
AGATTGGAATGCTGGAGATGATGAAGACCAGGTGGCGTTGAGGTTACAGTCGCAGTTAATGGTTGCGTTGCCTGCGCCTCAGGATTGTGTGATGGTGGAT
TTGAAGGCGGCGGAGGAGGACGAGGAGGGGAGAGTGGAGGTGGGGATGAAGGTGGAGAAGAAGAGAGAGGAATTGAGAGGGTTGATATTAGGGAAGAGTG
GATCGGGTCAACAGAGTGATGGAGTTGGTGTTTTGACTCGGTTGTTTAGATCTGATGATAGTCGGCATTGGAAGAGTGTGACTTTGCTTAGTCTTGGCGG
TTGCGGATTGGCGACATTGCCTGCTGAGATAATTCAGTTGCCAAATCTTGAGAAGCTTTATCTTGAGAACAACAGGCTTTCAGTTTTGCCACCTGAGCTT
GGTGAGCTGAAGAGTTTGAAAATTCTTGCAGTTGATTACAACATGCTGGTTACAGTTCCTCTGGAACTGGGGCAGTGCGTTGAACTGGTGGAATTGTCTT
TGGAACACAATAAGCTTGTCCAACCTCTTCTTGATTTCAGGTCTATGGCTGAGTTACAAATTCTCAGGCTATTTGGTAATCCTCTGGAATTCCTTCCTGA
AATTTTGCCTCTACACAAACTACGACACCTGTCTCTTGCTAATATGAAGATTGAGGCTGATGAAAGTTTGAGATCAGTGAATGTTCAGATAGAGATGGAG
AACAGCTCTTATTTTGGTGCATCTAGACACAAGCTTAGTGCCTTCTTTTCTCTCATATTCCGTTTTTCTTCTTGCCATCATCCTTTGCTGGCATCTGCGC
TGGCAAAGATAATGCAAGACCAAGGAAACCGTGTTGTTGTTGGGAAAGATCTGAATGCAGTGAAGCAGCTTATAAGTATGATGAGTAGTGACAACTGTCA
TGTGGTTAAACAAGCATGCTCTGCTCTATCTGCTCTTGCTGGAGATGTTTCTGTGGCAATGCAGTTGATGAAATGTGACATATTGCAACCCATTGAAACA
GTACTCAAATCGGTTGCTCAGGAAGAAGTAATTTCTGTCTTGCAAGTTGTGGCCACCTTGTCCTTTTCATCTGATACTGTATCTCAGAAGATGTTGACAA
GGGATATGTTGAGATCATTAAAACTGTTATGTGCTCAAAAAAATCCAGAGGTGCAAAGGTTATCTTTATTAGCTGTTGGAAATTTGGCCTTCTGCTTGGA
GAATCGACAGCTTATGGTCACCTCTGGAAGTCTGCAAGACCTTCTGTTGCACCTGACAGCTTCATCTGAACCACGTGTGAATAAAGCAGCAGCTCGTGCT
ATGGCAATTCTTGGAGAAAATGAAAATTTAAGGCGTTCCATAAGAGGGAGACCAGTGGCAAAGCAAGGACTGCGCATACTTTCAATGGATGGAGGTGGAA
TGAAAGGTCTGGCTACTGTGCAGATTCTTAAAGCAATTGAGAAGGGAACTGGAAAGCGAATACATGAGATATTCGACCTAATATGTGGCACATCAACTGG
TGGAATGCTGGCTGTTGCTCTTGGCATGAAGCTAATGACCTTGGATCAATGTGAAGAAATATACAAAAATCTTGGAAAACTCGTCTTTGCTGAACCTGTG
CCAAAGGATAATGAAGCTGCAACTTGGAGAGAGAAGTTGGATCAGCTTTACAAAAGTTCATCTCAGAGTTTTAGAGTTGTGGTGCATGGATATAAACACA
GTGCAGATCACTTTGAGAGGCTGTTAAAAGAAATGTGTGCTGATGAGGATGGAGATCTGTTAATAGATTCAGCAGTGAAAAATGTTCCCAAAGTATTTGT
TGTATCAACTTTGGTTAGTGTGATGCCAGCTCAACCATTTGTGTTCCGCAATTATCAGTATCCTGTTGGAACACTTGAAGTGCCCTTTGCAATTTCAGAA
AGTTCAGGAGTTCATGTGCTTGGATCACCTACTACTGGAGGTCAAGTTGGCTATAAACGTAGTGCTTTTATTGGCAGTTGCAAGCATCATGTTTGGCAAG
CCATAAGAGCATCATCTGCTGCTCCATACTATCTTGATGATTTCTCAGACGATGTAAACCGCTGGCAAGATGGTGCTATAGTGGCAAACAACCCTACCAT
ATTTGCTATAAGAGAAGCACAACTTCTATGGCCTGACACCAGAATTGACTGCTTAGTGTCAATAGGGTGTGGCGCTGTTCCAACAAAGGTCCGGAAAGGT
GGTTGGCGTTATCTGGATACCGGCCAAGTGTTGATTGAGAGTGCATGCTCTGTGGATAGAGTGGAGGAAGCTTTAAGTACACTGCTACCCATGCTTCCTG
AGATACAATATTTTCGATTTAATCCAGTTGATGAACGCTGTGGTATGGAGCTGGATGAGACTGACCCAGCTATCTGGCTAAAGTTGGAAGCTGCAGTTGA
TGAATATGTTCAGAACAATTCTGAAGCCTTCAAGAATGTCTGTGAGAGACTAATTTTTCCCTACCAACATGATGATAAATTGTCAGAGATTATGAAATCT
CAGCAATTTTCCAAGGCAAAGTTATCAAATGCAGATGAGACTAGTCCATCTTTAGGTTGGAGGCGTAATGTGCTACTTGTTGAAGCTTTGCACAGTCCTG
ATTCGGGAAGGGCTGTGCAACATTCCCGGGCACTAGAGACATTTTGTTCCCGCAATGCAATAATACTATCTCTCATGCATGCCACATCTGGAATTGCTAG
GACAGTGCCACCAGGAACATTCTCATCCCCTTTTTCATCACCTCTAATTACTGGAAGCTTCCCCTCAAGCCCGCTTCTATTCAGTCCTGATTTGGGCTCA
CAGAGGATTGGCCGTATTGACACGGTCCCACCTTTAAGCTTGGATGGAGTTCAGTCTGGAAAGACAGCTTTATCACCACCAATGTCCCCTTCGAAACACA
GACAGCTCTCTTTACCTGTTCGATCATTGCATGAAAAGCTACAGAATTCACCACAAGTGGGGATTATACATTTAGCCCTTCAAAATGACTCATCAGGCTC
AATATTAAGCTGGCAGAATGATGTATTTGTTGTTGCTGAACCGGGAGATCTTGCTGATAAGTTTCTTCAGAGTGTTAAATTTAGCTTGTTGTCAATGAAC
CGGAGCCGCCATAGGAGGATTACTTCACTGGTTGGCAATATTTCAACTGTTTCTGATTTAGTTCATTGTAAACCATGCTTCCTAGTTGGAAATGTCATCC
ATCGTTATATAGGACGACAGACGCAAGTCATGGAGGATGACCAAGAAATAGGGGCATATATGTTCCGTAGAACAGTTCCTTCTATGCACTTGACACCTGA
AGATGTTCGCTGGATGGTCGGAGCTTGGAGGGACAGGATTATAATTTGCACAGGAGCATATGGGCCTATGCCAACTTTAATCAAGGCCTTTCTGGATTCT
GGTGCAAAAGCTGTAATATGCCCTTCAGTAGAGCCCTTAGAAATCCCGGTGACACTAGTCCATGGATCAGGGGAGTACAATGTTCTGGAAAATGGGAGGT
TTGAGATCGGAGAGGAAGAGGCTGAGGAAGAAGAGGCCGAGCCTACCAGTCCAGTGAGTGATTGGGAAGATAGTGACCCCGAGAAGAATGGTGACCATTC
GATCGGTTTTTGGGATGATGATGAAGAGGAGCTATCCCAGTTTGTTTGCAAGTTGTATGATTTGTTATTTCGGGTAGGGGCAAGAGTAGATGCTGCTCTT
CAAAATGCTCTTGCTTTACACCAGAGGCTAAGGTATTCGTGCCATCTTCCTAGTATACAATAG
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
AA sequence
|
>Potri.011G000200.1 pacid=42780328 polypeptide=Potri.011G000200.1.p locus=Potri.011G000200 ID=Potri.011G000200.1.v4.1 annot-version=v4.1
MFSWKRPSELLRLTLNYGSEDLGDDLNRSSTSSSSTTAFTPSSSPLAYISTEAAAEEEDQVGFKIELDWNAGDDEDQVALRLQSQLMVALPAPQDCVMVD
LKAAEEDEEGRVEVGMKVEKKREELRGLILGKSGSGQQSDGVGVLTRLFRSDDSRHWKSVTLLSLGGCGLATLPAEIIQLPNLEKLYLENNRLSVLPPEL
GELKSLKILAVDYNMLVTVPLELGQCVELVELSLEHNKLVQPLLDFRSMAELQILRLFGNPLEFLPEILPLHKLRHLSLANMKIEADESLRSVNVQIEME
NSSYFGASRHKLSAFFSLIFRFSSCHHPLLASALAKIMQDQGNRVVVGKDLNAVKQLISMMSSDNCHVVKQACSALSALAGDVSVAMQLMKCDILQPIET
VLKSVAQEEVISVLQVVATLSFSSDTVSQKMLTRDMLRSLKLLCAQKNPEVQRLSLLAVGNLAFCLENRQLMVTSGSLQDLLLHLTASSEPRVNKAAARA
MAILGENENLRRSIRGRPVAKQGLRILSMDGGGMKGLATVQILKAIEKGTGKRIHEIFDLICGTSTGGMLAVALGMKLMTLDQCEEIYKNLGKLVFAEPV
PKDNEAATWREKLDQLYKSSSQSFRVVVHGYKHSADHFERLLKEMCADEDGDLLIDSAVKNVPKVFVVSTLVSVMPAQPFVFRNYQYPVGTLEVPFAISE
SSGVHVLGSPTTGGQVGYKRSAFIGSCKHHVWQAIRASSAAPYYLDDFSDDVNRWQDGAIVANNPTIFAIREAQLLWPDTRIDCLVSIGCGAVPTKVRKG
GWRYLDTGQVLIESACSVDRVEEALSTLLPMLPEIQYFRFNPVDERCGMELDETDPAIWLKLEAAVDEYVQNNSEAFKNVCERLIFPYQHDDKLSEIMKS
QQFSKAKLSNADETSPSLGWRRNVLLVEALHSPDSGRAVQHSRALETFCSRNAIILSLMHATSGIARTVPPGTFSSPFSSPLITGSFPSSPLLFSPDLGS
QRIGRIDTVPPLSLDGVQSGKTALSPPMSPSKHRQLSLPVRSLHEKLQNSPQVGIIHLALQNDSSGSILSWQNDVFVVAEPGDLADKFLQSVKFSLLSMN
RSRHRRITSLVGNISTVSDLVHCKPCFLVGNVIHRYIGRQTQVMEDDQEIGAYMFRRTVPSMHLTPEDVRWMVGAWRDRIIICTGAYGPMPTLIKAFLDS
GAKAVICPSVEPLEIPVTLVHGSGEYNVLENGRFEIGEEEAEEEEAEPTSPVSDWEDSDPEKNGDHSIGFWDDDEEELSQFVCKLYDLLFRVGARVDAAL
QNALALHQRLRYSCHLPSIQ
|
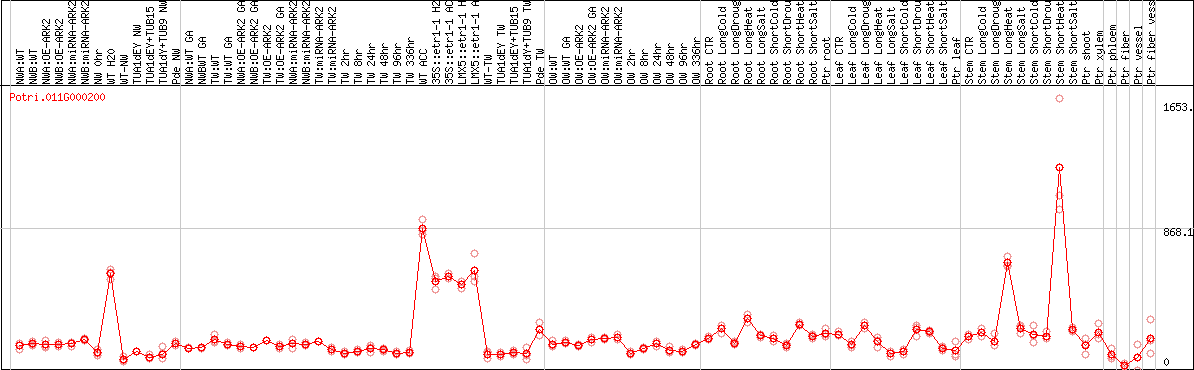
DESeq2's median of ratios [POPLAR]
Coexpressed genes
Potri.011G000200 coexpression network
*The number of genes in the network is adjusted within 50 genes.*Gene name represents symbol(s) of closest Arabidopsis gene if symbol(s) for the gene itself doesn't exist.
*Circle diameter represents the number of connection with other genes within this network.
*Color for gene name represents subnetwork based on the result of network clustering.